






MUTR:Referred by Multi-Modality: A Unified Temporal Transformer for Video Object Segmentation
多模态参考: 用于视频对象分割的统一时态变换器
出版年份:2023\
出版期刊:AAAI2024\
文章作者:Yan Shilin,Zhang Renrui,Guo Ziyu,Chen Wenchao,Zhang Wei,Li Hongyang,Qiao Yu,Dong Hao,He Zhongjiang,Gao Peng
摘要+引言+结论:
研究背景:
探索模态内的语义对齐和跨帧的视觉对应关系具有挑战性
目前的缺陷:
现有方法针对不同模态采用单独的网络架构,忽略了与指代相关的帧间的时间交互
1、性能有待加强,忽略了跨帧的多模态信息
目前的方法主要关注独立帧内的视觉-语言或视觉-音频模态融合,简单地通过跨模态关注或动态卷积进行特征交互
然而,这忽略了跨帧的多模态时间信息,这对于视频中一致的目标分割和跟踪具有重要意义。
2、不够统一,不同模态的提示没有统一的框架
其次,对于给定的语言和音频两种模态的参照物,现有工作采用不同的架构设计和训练策略来分别处理它们的模态特异性特征。
多模态VOS的两大挑战
1、探索视频中丰富的时空一致性,
2、协调图像、语言和音频之间的多模态语义。
研究设计(这篇文献的研究方法是什么,数据是怎么获取的):
本文提出了用于指代视频对象分割的多模态统一时间转换器MUTR。
MUTR首次采用了统一的框架处理语言和音频的提示信息
1、采用了类似于DETR的编码器-解码器转换器作为基本架构来处理不同帧内的视觉信息。在此基础上,我们引入了两个基于注意力的模块,分别用于低层次的多模态时间聚合( MTA )和高层次的多目标时间交互( MTI )
低层次的多模态时间聚合( MTA )
在transformer之前,利用编码后的referring作为查询,通过MTA模块来聚合视觉和时间特征
将相邻帧的视觉特征进行串联,对于多模块token采用连续的注意力块,以渐进的捕捉不同图像尺度的时间视觉线索
优点:
这有助于更好的低层次跨模态对齐和时间一致性。然后,我们将MTA后的多模态令牌作为对象查询,并将其输入到Transformer中进行逐帧解码。
高层次的多目标时间交互( MTI )
进行帧间对象级的交互,维持一组视频级的查询表示,用于关联帧间对象
该模块增强了实例级时空通信,有利于在视频中分割同一对象时实现视觉对应。
最后,我们仿效先前的研究成果(Wu 等,2022 年;Wu 等,2021 年),利用分割头输出多模态输入的最终对象掩码。
采用了DETR风格的转换器,能够对文本或音频引用指定的视频对象进行分割。具体来说,我们引入了两种策略来充分挖掘视频和多模态信号之间的时间关系
1、首先,对于Transformer之前的低级时间聚合,我们使多模态参考能够从连续的视频帧中捕获多尺度的视觉线索。这有效地赋予了文本或音频信号以时间知识,并促进了模态之间的语义对齐
2、其次,对于Transformer之后的高级时间交互,我们针对不同的对象嵌入进行帧间特征通信,为沿视频的跟踪提供更好的对象对应关系
本篇文章主要是针对视频指代分割进行的,从上面两个部分加强帧与帧之间的联系,增强模型的事件知识
实验结果(研究获得了什么结果):
在Ref - YouTube - VOS和AVSBench数据集上,MUTR分别在文本和音频参考数据集上取得了+ 4.2 %和+ 8.7 %的J & F提升,证明了我们对于统一多模态VOS的意义。
YouTube - VOS
Ref - DAVIS 2017
AVSBench
基础知识:
DETR
图表:
图1:

参考视频对象分割的MUTR整体流水线。我们提出了一个统一的Transformer架构来处理多模态输入所涉及的视频对象分割。我们提出了MTA模块和MTI模块分别用于低层多尺度聚合和高层多目标交互。
图2:


多尺度时间聚合。对于低层次的多模态时间聚合,我们提出了用于帧间交互的MTA模块,该模块生成具有多模态知识的令牌作为Transformer解码的输入查询
图3:
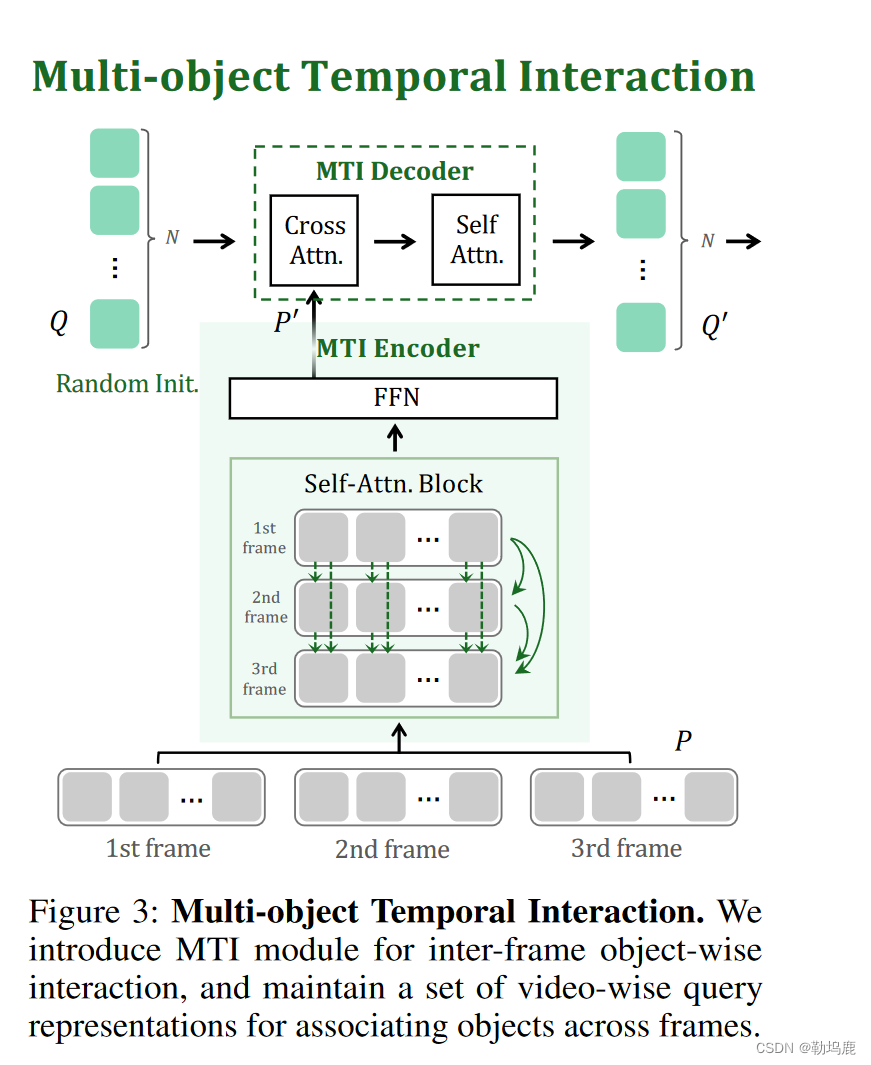
多目标时间交互。我们引入MTI模块进行帧间对象级的交互,并维护一组视频级的查询表示,用于跨帧关联对象。
表1:

表2:

表3-6:
使用了多模态联合训练后性能有所提升

图4:

Mutr .的定性结果。我们在R - VOS基准上可视化了ReferFormer和MUTR之间的结果,在AV - VOS基准上可视化了Baseline ( Zhou et al 2022)和MUTR之间的结果。与ReferFormer相比,MUTR在分割多个相似物体时表现出更好的时间一致性,如Ref - YouTube - VOS中的消防车和Ref - DAVIS 2017中的方框。同时,与图中AV - VOS ( Zhou et al 2022)的基线" Baseline "相比,MUTR可以处理严重遮挡。
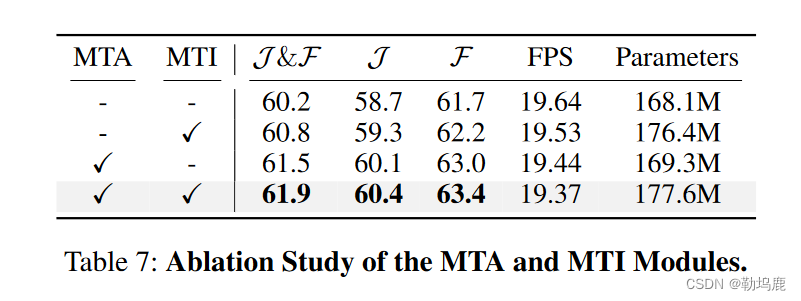
表7:消融实验
疑问:(在粗读的过程中的疑问)
与图中AV - VOS ( Zhou et al 2022)的基线" Baseline "相比,MUTR可以处理严重遮挡是如何实现的?
音频引导与文字引导的区别在于(不是很重要)
研究目的:
1、提出了一个统一的Transformer架构,MUTR,用于处理多模态输入(即语言和音频)所涉及的视频对象分割
2、为了更好地将时间信息与多模态信号对齐,提出了两个基于注意力的模块,MTA和MTI,分别用于低级多尺度聚合和高级多对象交互,以实现视频中优越的跨模态理解
理论基础:
Referring video object segmentation (R-VOS).
应用语言引导的图像分割方法
独立应用于视频帧
忽略了时间信息,因此难以处理常见的视频难题,如再现中的物体消失。
“Another approach involves propagating the target mask detected from key frame and selecting the object to be segmented based on a visual grounding model” (Yan 等, 2023, p. 2) 另一种方法是传播从关键帧中检测到的目标掩膜,并基于视觉接地模型选择待分割对象
传播从关键帧中检测到的目标掩膜
并基于vision-ground模型选择待分割对象
“Although it applies the temporal information to some extent, its complex multi-stage training approach is not desirable.” (Yan 等, 2023, p. 2) 虽然它在一定程度上利用了时间信息,但其复杂的多阶段训练方法并不可取。
基于查询的机制
MTTR
ReferFormer
然而,它们都是端到端的框架,它们使用图像级分割来执行R - VOS任务。
本文的模型
统一框架可充分挖掘视频级视觉语言信息,实现低级时空聚合
Audio-visual video object segmentation (AV-VOS)”
受最近多模态工作( Zhang et al.2023a ; Gao et al.2023 ;林毅夫等2023 ; Wang et al.2023 ;郭庆旺等2023 ; Han et al.2023b , a)的启发,AV - VOS被提出用于根据给定的声音信号预测像素级别的个体位置。
以往关于视听视频对象分割的工作很少。直到最近( Zhou et al 2022)提出了视听视频对象分割数据集。
与之不同的是,(莫言和田2023)是基于最近的视觉基础模型Segment Anything Model (基里洛夫et al 2023 ; Zhang et al 2023c)来实现音视频分割的。
然而,它们都缺乏多模态信息之间的时间对齐。
研究方法:
整体框架
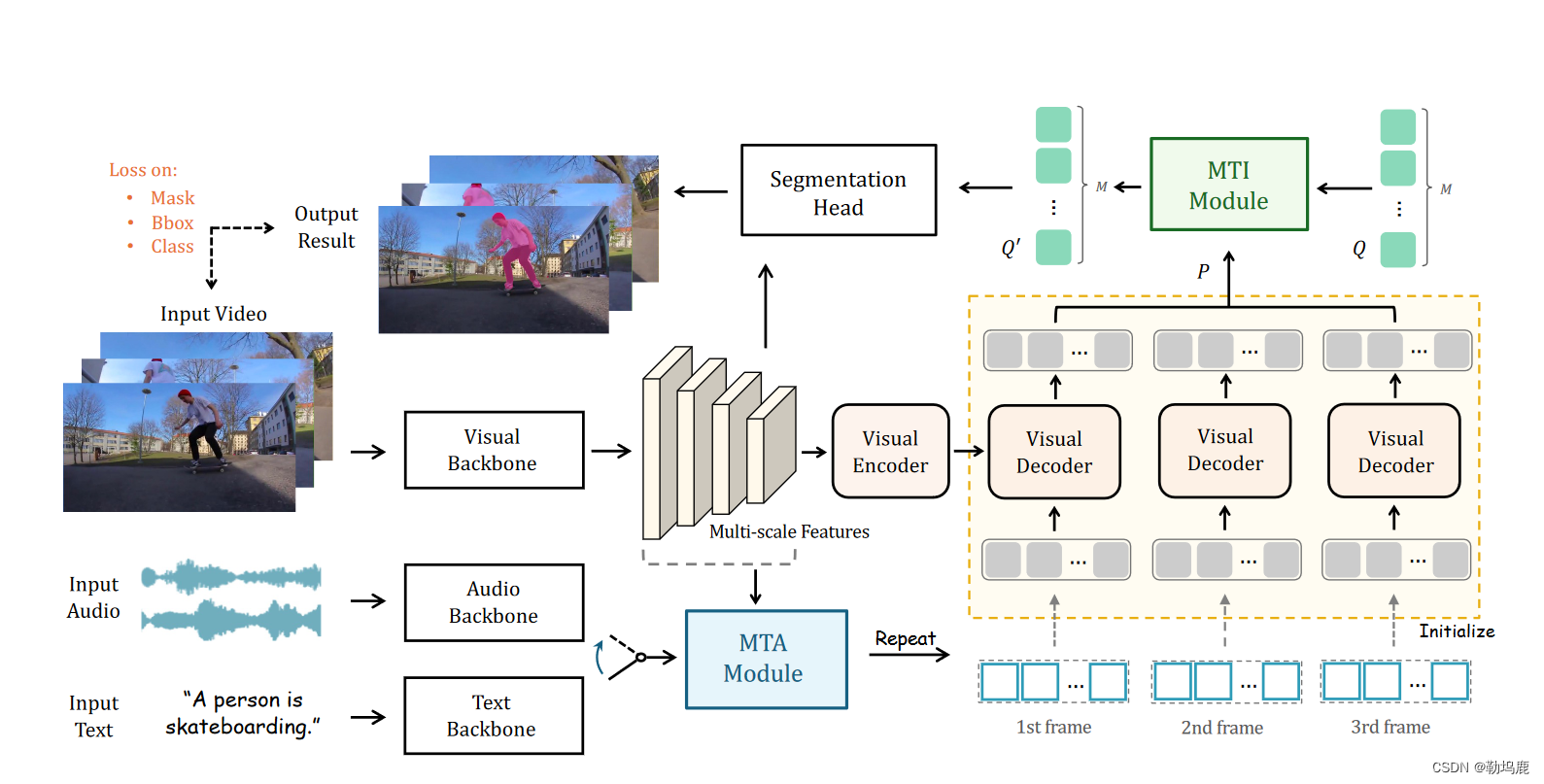
提出了一个统一的Transformer架构来处理多模态输入所涉及的视频对象分割。
提出了MTA模块和MTI模块分别用于低层多尺度聚合和高层多目标交互
采用基于DETR的转换器作为基本架构,包括视觉主干网、视觉编码器和解码器,并在此基础上提出了两个用于时间多模态交互的模块MTA和MTI
Feature Backbone
给定一对输入视频-文本/音频,首先从视频片段中采样 T 帧,然后利用视觉骨干网和预训练的文本/音频骨干网提取图像和多模态特征
1、使用 ResNet或 Swin Transformer作为视觉骨干,并获得第二、第三和第四阶段的多尺度视觉特征
同时,对于文本参考,我们采用现成的语言模型 RoBERTa(Liu 等人,2019 年)对语言嵌入标记进行编码。
对于音频参考,我们首先通过短时傅里叶变换将其处理为频谱图变换,然后将其输入预训练的 VGGish(Hershey 等人,2017 年)模型。
文本/音频编码后,采用线性投影层将多模态特征维度与视觉特征对齐。
需要注意的是,根据之前的工作(Wu 等人,2022 年),我们在视觉骨干中采用了早期融合模块,将初步的文本/音频知识注入视觉特征。
“Liang, C.; Wu, Y.; Zhou, T.; Wang, W.; Yang, Z.; Wei, Y.; and Yang, Y. 2021. Rethinking cross-modal interaction from a top-down perspective for referring video object segmentation. arXiv preprint arXiv:2106.01061.”
“MTA Module”
多尺度时间聚合模块
输入:视频特征/文本特征、语音特征
输出值作为查询
“Visual Encoder-decoder Transformer”
不依赖帧的方式处理,专注于单帧内的特征融合
编码器:采用vanilla self-attention block编码多尺度视觉特征
Vanilla self-attention block是Transformer架构中的一个核心组件,它使得模型能够在处理序列数据(如文本、图像等)时考虑序列中各个元素之间的关系。这种机制的引入,相较于以往的序列处理模型(如RNNs和LSTMs),在很多任务上都表现出了显著的性能提升。下面我将详细解释vanilla self-attention block的组成和工作原理。
组件
一个vanilla self-attention block主要包含以下几个组件:
1. Self-Attention Mechanism:核心组件,用于计算序列内各元素之间的关系。
2. Multi-Head Attention:将输入分割为多个头(head),每个头独立进行self-attention计算,最后将结果拼接起来。这样可以让模型同时从不同的表示子空间学习信息。
3. Position-wise Feed-Forward Networks:对multi-head attention的输出进行进一步处理的全连接网络,对每个位置应用相同的操作,但是对不同的元素是独立的。
4. Add & Norm:包括残差连接和层归一化(Layer Normalization),用于改善训练过程中的梯度流动,促进深层网络的训练。
工作原理
1. **输入表示**:首先,输入序列通过嵌入层转换为固定维度的向量表示,并加入位置编码(Position Encoding)以包含序列中元素的位置信息。
2. **Self-Attention**:Self-attention通过计算序列中每个元素与其他所有元素的关系,来获取全局上下文信息。具体来说,它使用三个权重矩阵将输入的向量表示转换为Query(Q)、Key(K)、Value(V)三种向量。然后,通过计算Q与K的点积,得到一个注意力分数(attention scores)矩阵,表示序列中每对元素之间的相似度。这个分数矩阵经过softmax归一化后,与V相乘,得到加权后的输出,这个输出即为考虑了全局上下文信息的表示。
3. **Multi-Head Attention**:将Q、K、V分割为多个头,独立地进行self-attention操作,可以让模型在不同的表示子空间中捕获信息。各头输出后拼接并通过一个线性层进行合并。
4. **Position-wise Feed-Forward Networks**:接着是两层全连接网络的处理,对multi-head attention的结果进行进一步的非线性变换。
5. **Add & Norm**:最后,通过残差连接将输入直接加到Feed-Forward网络的输出上,然后应用层归一化。这有助于避免深层网络中的梯度消失问题,使得训练更加稳定。
这个过程在Transformer模型中会重复多次(即多个self-attention blocks堆叠),以构建深度模型。通过这种方式,Transformer能够有效地处理序列数据,无论是长距离依赖还是复杂的模式关系,都能捕捉到,从而在各种任务上实现出色的性能。
key\value:编码后的视觉特征
query:MTA模块输出的referring(查询方面改进,DETR是随机初始化的查询,而这里的查询是MTA模块的输入条件拆线呢,包含了丰富的多模块知识)
视觉解码器:目标查询获得了丰富的实例信息,为最终的分割过程提供了有效的线索
(有点错误,可能需要更改)
“MTI Module”
视觉transformer后,使用MTI模块进行对象间的交互1
MTI编码器:通信同一对象在不同视图(帧)之间的时间特征
MTI解码器:将信息提取到一组视频查询表示中,用于关联跨帧的对象
“Heo, M.; Hwang, S.; Oh, S. W.; Lee, J.-Y.; and Kim, S. J. 2022. Vita: Video instance segmentation via object token association. arXiv preprint arXiv:2206.04403.”
“Segmentation Head and Loss Function”
分割头:bounding box head、classification head、mask head
使用匈牙利匹配从MUTR的预测中找到最佳的分配?
“Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; and Zagoruyko, S. 2020. End-to-end object detection with transformers. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16, 213–229. Springer.”
损失函数
MUTR中计算了三个损失,分别是关于参考对象序列预测的focal loss( Lin et al 2017)Lcls
预测实例边界框上的Lbox和预测对象掩码上的Lmask。
其中,Lbox是L1损失和GIoU损失( Rezatofighi等2019)的组合
Lmask是Dice (米莱塔里、Navab和Ahmadi 2016)和“binary focal loss” 的和。
整体损失计算为:
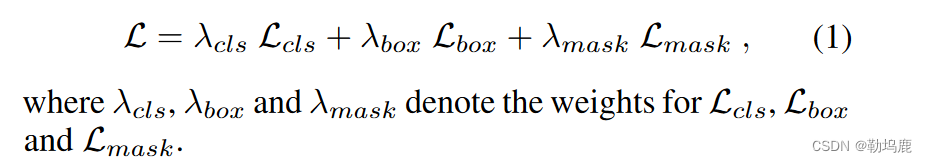
MTA多尺度时序融合模块
作用:低层次的时序聚合——>促进多模态的多帧视频之间的融合
生成一组包含多模态知识的对象查询,用于后续的transformer decoder
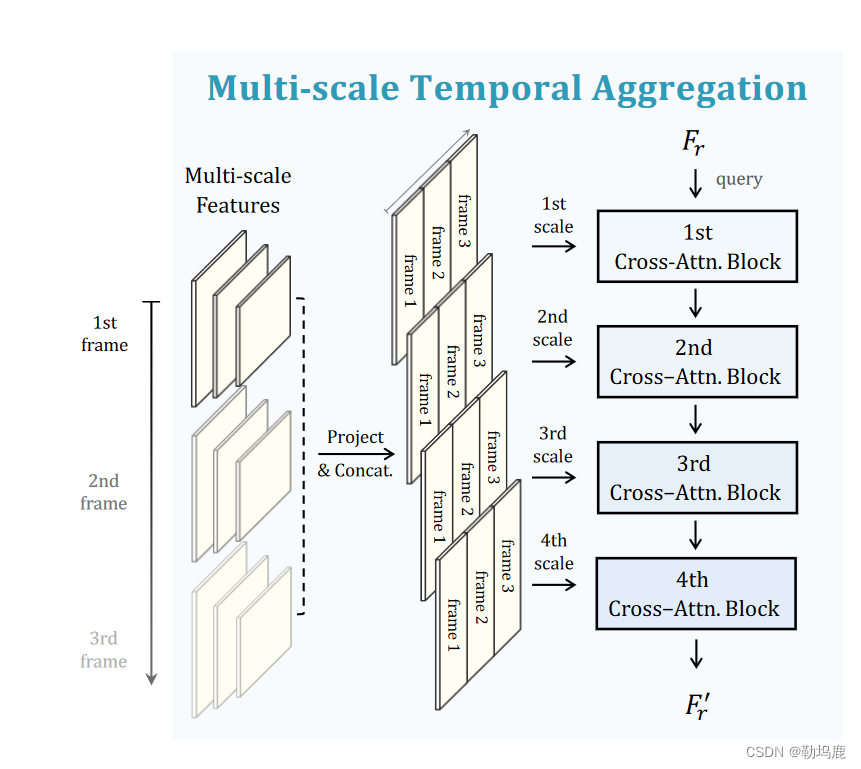
对于低层次的多模态时间聚合,我们提出了用于帧间交互的MTA模块,该模块生成具有多模态知识的token作为Transformer解码的输入查询。
“Multi-scale Temporal Transform”
具体操作:
1、使用多尺度特征上的线性投射将他们变换到相同的维度
将2、3、4层使用11卷积变换、在第4层上额外使用3*3的卷积
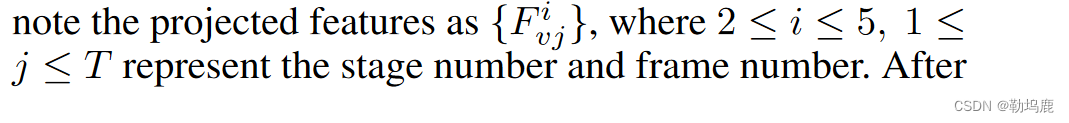
2、每一层的特征按照帧拼接到一起得到投射的特征
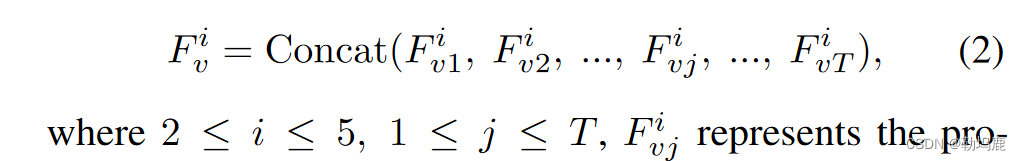
F i vj表示第i个尺度的第j帧投影特征,{ F i v } 5i = 2为最终变换后的多尺度视觉特征。然后,将得到的多模态时间特征作为后续交叉注意力块中的关键和价值。
3、
Multi-model Cross-attention
除此之外,采用多模态标记的顺序交叉注意力机制来逐步捕获不同图像尺度的时间视觉线索。
我们采用4个交叉注意力块,分别分配给每个尺度进行多尺度时间特征提取。在每个注意力块中,文本/音频特征作为查询,而多尺度视觉特征作为键和值。
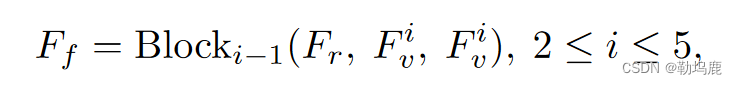
其中,Block表示MTA模块中的顺序交叉注意力块,Ff为输出的包含多模态信息的多模态token
这里公式可能有些问题,根据公式来说应该是跟每次都还是跟FR做交叉注意力的
之后,简单重复Ff的class tokenT × N次,其中T为帧数,N为查询数?
应该是在这里已经讲述到了decoder的部分,每一帧跟之前的encoder的特征做注意力计算,这里的referring做查询。
将它们作为初始化的查询输入到视觉transformer中进行逐帧解码
通过MTA模块,预先初始化的输入查询可以获得先验的多尺度知识和时间信息,以便在后续解码过程中更好地进行多模态对齐
ps:
这里的query应该是referring,通过MTA模块,将原来简单编码的referring加入了更多是觉得多尺度知识(不同特征图之间的拼接)和视频之间的时间信息(不同帧之间的拼接)
MTI
多目标时间交互。我们引入MTI模块进行帧间对象级的交互,并维护一组视频级的query表示,用于跨帧关联对象。
由于“visual transformer” 采用的是帧独立的方式,无法进行多帧之间的信息交互,我们进一步引入了多对象时序交互模块来进行帧间的对象级交互。该模块增强了物体的高层时序通信,有利于视觉对应进行有效分割。MTI的详细信息如图3所示,它由MTI编码器和MTI解码器组成
MTI Encoder
从Transformer解码器中获取每一帧的目标查询输出P,并将其输入到MTI编码器中,该编码器包含一个自注意力层,用于跨多帧进行目标交互,以及一个用于特征转换的前馈网络层。
为了实现更高效的实现,我们在自注意力层中采用了具有线性计算复杂度的移位窗口注意力。
在这个部分帧与帧之间进行交互,采用了移位窗口的注意力(swim-transformer?)
代码解释:
def _window_attn(self, frame_query, attn_mask, layer_idx):
T, fQ, LB, C = frame_query.shape
# LBN, WTfQ = attn_mask.shape
W = self.window_size
Nw = T // W
frame_query = frame_query.view(Nw, W, fQ, LB, C)
frame_query = frame_query.permute(1,2,3,0,4).reshape(W*fQ, LB*Nw, C)
frame_query = self.enc_self_attn[layer_idx](frame_query, tgt_key_padding_mask=attn_mask)
frame_query = self.enc_ffn[layer_idx](frame_query)
frame_query = frame_query.reshape(W, fQ, LB, Nw, C).permute(3,0,1,2,4).reshape(T, fQ, LB, C)
return frame_query
def _shift_window_attn(self, frame_query, attn_mask, layer_idx):
T, fQ, LB, C = frame_query.shape
# LBNH, WfQ, WfQ = attn_mask.shape
W = self.window_size
Nw = T // W
half_W = int(ceil(W / 2))
frame_query = torch.roll(frame_query, half_W, 0)
frame_query = frame_query.view(Nw, W, fQ, LB, C)
frame_query = frame_query.permute(1,2,3,0,4).reshape(W*fQ, LB*Nw, C)
frame_query = self.enc_self_attn[layer_idx](frame_query, tgt_mask=attn_mask)
frame_query = self.enc_ffn[layer_idx](frame_query)
frame_query = frame_query.reshape(W, fQ, LB, Nw, C).permute(3,0,1,2,4).reshape(T, fQ, LB, C)
frame_query = torch.roll(frame_query, -half_W, 0)
return frame_query
```
用于在编码阶段对输入帧查询应用窗口化的注意力机制,旨在提高模型处理长序列时的效率和效果。通过将序列分成多个窗口,并对每个窗口分别应用注意力机制(可选地进行滑动以覆盖窗口之间的边界区域),模型能够更好地捕获局部依赖关系
MTI Decoder
基于MTI编码器,我们维护一组**视频查询Q,用于在随机初始化的帧间关联对象**。将MTI编码器的输出作为密钥和值,将其和视频查询Q送入MTI解码器进行视频解码。
这里的“video-wise queries Q”** 是什么**
-
初始化和表示
:查询
Q通过self.query_embed和/或self.query_feat在模型初始化时被随机生成,每个查询向量的维度与输入特征的维度相同。这些查询向量代表了模型试图在视频序列中跟踪和识别的对象或特征的抽象表示。 -
解码器中的使用
:在解码器中,视频级别查询
Q与编码器的输出(作为key和value)通过交叉注意力层进行交互,使查询能够聚焦于与对象关联相关的特征。交叉注意力层后,自注意力层进一步处理这些查询,使每个查询能够根据其他查询的信息更新自身表示,增强了模型对视频中多对象关系的理解。最后,通过前馈网络层进一步加工这些信息,为下游任务(如对象检测、跟踪等)提供更准确的特征表示。 -
跨帧关联:通过在解码器中处理,查询
Q可以学习到如何跨越多个帧关联同一对象或特征,即便它们在视频中的位置、形态或其他特性发生变化。这对于理解视频内容,尤其是在动态变化的场景中,是非常重要的
MTI解码器由交叉注意力层、自注意力层和前馈网络层组成。
公式为Q′= MTI _ Decoder( Q , P′, P′) ( 5 )式中,MTI _ Decoder表示MTI译码器,Q′为MTI译码器的输出。
通过这种方式,提出的MTI模块促进了高层次的时间融合,增强了不同帧中相同对象的连接和交互,从而进一步有助于有效分割。
ps:因为帧之间计算了自注意力
最后查询Q通过交叉注意力和自注意力不断学习成为了Q’
最终分割部分,通过多级的特征图和学习到的视频级的特征得到不同帧之间的mask,实现视频之间的分割
“Joint Training for Multi-modality”
作为多模态的统一VOS框架,MUTR具有分割文本或音频引用的视频对象的潜力。为了实现这一点,我们通过结合文本和音频参考数据集进行联合训练。具体地,为了平衡两种模态的数据量,联合训练数据由部分Ref - YouTube - VOS ( Seo , Lee , and Han 2020) (文本参考)和整个AVSBench S4 ( Zhou et al 2022) (音频参考)组成。我们从72,920个实例中抽取了Ref - YouTube - VOS的一个子集用于训练( 10 , 093个片段(每个片段5帧)) ),对于具有多个文本描述的视频只使用一个描述,并根据奇数索引位置过滤掉一半的实例用于训练。对于文本或音频的引用,我们相应地切换到它们的方面
实验:
在RVOS数据集上
在AV-VOS数据集上
在联合数据集上
定性分析
消融实验:
不同部件之间的消融实验
讨论:
●总结
1、通用性:统一的框架处理语言和音频的提示信息的思想
2、每一帧之间的多模态交互与帧与帧之间的包含时间信息交互
创新点:
1、提出一个统一的架构MUTR,用于处理多模态(语言和音频)的视频对象分割
2、提出了两个基于注意力的模块MTA和MTI,用于低级多尺度聚合和高级多对象交互
3、在两个任务数据集上都取得了最先进结果
局限性:
改进方法:
">后期回顾:
“Another approach involves propagating the target mask detected from key frame and selecting the object to be segmented based on a visual grounding model” (Yan 等, 2023, p. 2) 另一种方法是传播从关键帧中检测到的目标掩膜,并基于视觉接地模型选择待分割对象














 1174
1174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









