







Numpy,即Numeric Python是高性能科学计算和数据分析的基础包。NumPy为我们提供了丰富的数学函数、强大的多维数组对象以及优异的运算性能。NumPy与SciPy、Matplotlib、SciKits等其他众多Python科学计算库很好地结合在一起,共同构建了一个完整的科学计算生态系统。
功能主要包括:
1、一个强大的N维数组对象Array;
2、比较成熟的(广播)函数库;
3、用于整合C/C++和Fortran代码的工具包;
4、实用的线性代数、傅里叶变换和随机数生成函数。
import numpy as npNumpy的ndarry:一种多维数组
它最重要的一个特点是其N维数组对象(即ndarry),可以利用这种数组对整块数据执行一些数学运算。
创建Ndarray,使用array函数,它接受一切序列型的对象,然后产生一个新的含有传入数据的Numpy数组
data1=[6,7.6,8,0,5]
arr1=np.array(data1)arr1array([ 6. , 7.6, 8. , 0. , 5. ])
嵌套序列(比如一组等长列表组成的列表),将会转换为一个多维数组
data2=[[1,2,3,4,],[5,6,7,8]]arr2=np.array(data2)data2[[1, 2, 3, 4], [5, 6, 7, 8]]
arr2.shape(2, 4)
arr2.ndim2
数据类型保存在一个特殊的dtype对象中。
arr1.dtypedtype('float64')
arr2.dtypedtype('int32')
使用zero和one分别可以创建指定的长度或形状的全0或全1数组。empty可以创建一个没有任何具体值的数组
np.zeros(10)array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
np.zeros((3,6))array([[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.]])
np.empty((2,3,4))array([[[ 3.53905284e-316, 7.36157812e-322, 0.00000000e+000,
0.00000000e+000],
[ 2.18226563e+243, 1.16095484e-028, 3.23769002e+131,
1.13168766e-095],
[ 9.29846444e+242, 9.16526748e+242, 7.90316782e-071,
3.68423986e+180]],
[[ 9.92169729e+247, 4.78111609e+180, 1.02124020e+277,
4.54814392e-144],
[ 6.06003395e+233, 1.06400250e+248, 1.15359351e+214,
4.89287583e+199],
[ 8.03704417e-095, 9.07235856e+223, 1.16417019e-028,
3.59453120e+246]]])
empty在多数情况下,返回的都是一些未初始化的垃圾值
arange是python内置函数range的数组版本
np.arange(15)array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
np.arange(16).dtypedtype('int32')
np.ones(3)array([ 1., 1., 1.])
np.eye(3)array([[ 1., 0., 0.],
[ 0., 1., 0.],
[ 0., 0., 1.]])
np.identity(3)array([[ 1., 0., 0.],
[ 0., 1., 0.],
[ 0., 0., 1.]])

ndarray的数据类型
dtype(数据类型)是一个特殊的对象,含有ndarray将一块内存解释为特定数据类型所需的信息。
arr1=np.array([1,2,3],dtype=np.float64)arr2=np.array([1,2,3],dtype=np.int32)arr1.dtypedtype('float64')
arr2.dtypedtype('int32')
数值型dtype的命名方式相同,一个类型名,后面加上表示各个元素位长的数字,标准的双精度浮点值需要占用8个字节(即64位),因此该类型在numpy中记为float64.


可以通过ndarray的astype方式显示地转换其他的dtype类型
arr=np.array([1,2,3,4,5])arr.dtypedtype('int32')
float_arr=arr.astype(np.float64)float_arr.dtypedtype('float64')
可以看到整数转换为浮点数,如果浮点数转换为整数,则小数部分会被去掉
arr=np.array([3.7,-1.2,-2.6,0.5,12.8,10.2])arrarray([ 3.7, -1.2, -2.6, 0.5, 12.8, 10.2])
arr.astype(np.int32)array([ 3, -1, -2, 0, 12, 10])
如果某字符串数组表示的全都是数字,可以使用astype转换为数值型
numeric_strings=np.array(['1.25','-6.8','66'],dtype=np.string_)numeric_strings.astype(float)array([ 1.25, -6.8 , 66. ])
numeric_strings.astype(float64)---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-51-a186845b40d0> in <module>()
----> 1 numeric_strings.astype(float64)
NameError: name 'float64' is not defined
如果转换过程失败了,比如某个不能转换为float64的字符串就会引发TypeError,numpy很聪明,知道将python类型映射到等价的dtype上面。
数组的另外一种用法
int_array=np.arange(10)int_array.dtypedtype('int32')
calibers=np.array([.22,.280,.357,.390,.44,.55],dtype=np.float64)calibersarray([ 0.22 , 0.28 , 0.357, 0.39 , 0.44 , 0.55 ])
int_array.astype(calibers.dtype)array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
也可以用简洁的代码表示dtype
empty_unint32=np.empty(8,dtype='u4')empty_unint32array([1, 2, 3, 4, 5, 6, 7, 8], dtype=uint32)
注意:astype无论如何都会创建一个新的数组(原始数据的一种拷贝);浮点数只能表示近似的分数值(比如float32和float64)
数组和标量之间的运算
大小相等的数组之间的任何算术运算都会应用到元素级
arr=np.array([[1.,2.,3.],[4.,5.,6.]])arrarray([[ 1., 2., 3.],
[ 4., 5., 6.]])
arr*arrarray([[ 1., 4., 9.],
[ 16., 25., 36.]])
arr+arrarray([[ 2., 4., 6.],
[ 8., 10., 12.]])
arr-arrarray([[ 0., 0., 0.],
[ 0., 0., 0.]])
1/arrarray([[ 1. , 0.5 , 0.33333333],
[ 0.25 , 0.2 , 0.16666667]])
arr**0.5array([[ 1. , 1.41421356, 1.73205081],
[ 2. , 2.23606798, 2.44948974]])
不同大小数组之间的运算叫广播
基本索引的切片
arr=np.arange(10)arrarray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
arr[6]6
arr[4:8]array([4, 5, 6, 7])
arr[4:8]=12arrarray([ 0, 1, 2, 3, 12, 12, 12, 12, 8, 9])
可以看出将一个标量值赋值给一个切片时候,该值会自动传播到整个选区,跟列表最重要的区别在于,数组切片是原始数组的视图,
意味着数据不会被复制,视图上的任何修改会直接反映到原来数组上。
arr_slice=arr[5:8]arr_slice[1]=123456arrarray([ 0, 1, 2, 3, 64, 64, 64, 64, 8, 9])
arr_slice[:]=64arrarray([ 0, 1, 2, 3, 64, 64, 64, 64, 8, 9])
如果想要得到的是ndarry切片的是一份副本而不是视图,就需要显示地进行复制操作,例如arr[5:8].copy()
copy_arr=arr[5:8].copy()copy_arrarray([64, 64, 64])
在一个二维数组中,各索引位置上的元素不在是标量而是一维数组
arr2d=np.array([[1,2,3],[4,5,6],[7,8,9]])arr2darray([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
arr2d[2]array([7, 8, 9])
arr2d[0][2]3
arr2d[0,2]3
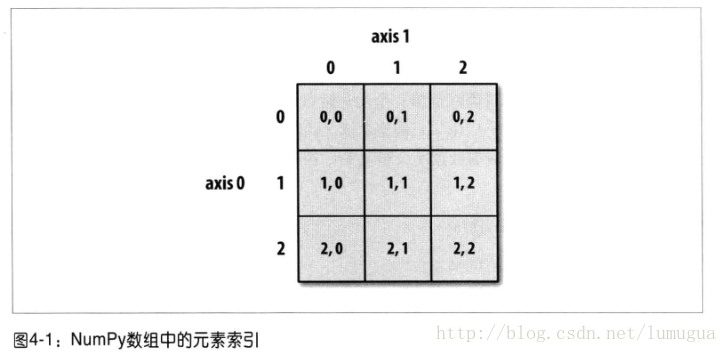
Numpy数组中元素的索引
在多维数组中如果省略了后面的索引,则返回对象会是一个维度低一点的ndarry(它含有高一级维度上的所有数据)
arr3d=np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])arr3darray([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
arr3d[0]array([[1, 2, 3],
[4, 5, 6]])
arr3d[0]是一个2*3数组
标量值和数组都可以被赋值给arr3d[0]
old_values=arr3d[0].copy()old_valuesarray([[1, 2, 3],
[4, 5, 6]])
arr3d[0]=42arr3darray([[[42, 42, 42],
[42, 42, 42]],
[[ 7, 8, 9],
[10, 11, 12]]])
arr3d[0]=old_valuesarr3darray([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
arr3d[1,0]array([7, 8, 9])
上面的这些选取数组子集的例子中,返回的数组都是视图。
arr3d[:,0]array([[1, 2, 3],
[7, 8, 9]])
arr3d[0,1]array([4, 5, 6])
arr3d[0,1,2]6
arr3d[:,:,1]array([[ 2, 5],
[ 8, 11]])
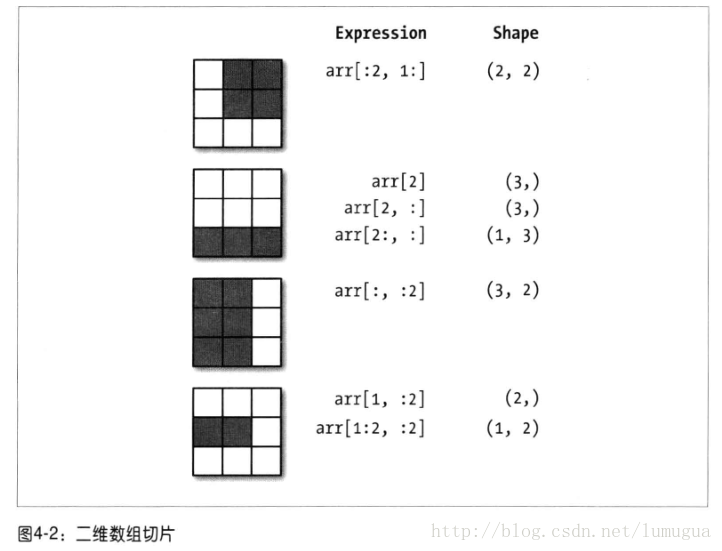
切片索引
arrarray([ 0, 1, 2, 3, 64, 64, 64, 64, 8, 9])
arr[1:6]array([ 1, 2, 3, 64, 64])
高维度可以在一个或者多个轴上进行切片,也可以根据数组索引混合使用
arr2darray([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
arr2d[:2]array([[1, 2, 3],
[4, 5, 6]])
可以看出是沿着0轴(即第一个轴)切片的,切片的沿着一个轴向选取元素的,可以一次传入多个切片,就像传入多个索引那样
arr2d[:2,1:]array([[2, 3],
[5, 6]])
可以通过数组索引和切片混合,可以得到低维度的切片
arr2d[1,:2]array([4, 5])
arr2d[2,:1]array([7])
注意:“只有冒号”表示选取整个轴,因此可以这样只对高维轴进行切片
arr2d[:,:1]array([[1],
[4],
[7]])
arr2d[:2,1:]array([[2, 3],
[5, 6]])
arr2d[:2,1:]=0arr2d[:2,1:]array([[0, 0],
[0, 0]])
对切片表达式的赋值操作也会被扩展到整个选区。
布尔型索引
现在使用numy.random中的randn函数生成一些正态分布的随机数据
names=np.array(['Bob','Joe','Will','Bob','Will','Joe','Joe'])namesarray(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'],
dtype='<U4')
data=np.random.randn(7,4)dataarray([[ 1.20160119, -1.05723288, -0.57060877, 0.93471043],
[ 0.5413258 , 0.18615647, 0.57429245, -0.07045294],
[-1.57840839, 0.03816457, 0.06441022, 1.15967355],
[-0.87407974, -0.28018097, 0.80884835, 1.07076835],
[-1.5814758 , 0.81780567, 0.43782677, -0.91748426],
[ 2.03128426, -0.21807742, -0.73759551, 0.42158797],
[-2.13423716, 0.99993262, -1.02045863, -0.31841384]])
假设每个名字都对应数组中的一行,而我们想要选出对应于名字“Bob”的所有行。跟算术运算一样,数组的比较运算也是适量化的,
因此对nams和字符串“Bob”的比较运算将会产生一个布尔型数组
names == 'Bob'array([ True, False, False, True, False, False, False], dtype=bool)
data[names=='Bob']array([[ 1.20160119, -1.05723288, -0.57060877, 0.93471043],
[-0.87407974, -0.28018097, 0.80884835, 1.07076835]])
布尔型数组的长度必须跟被索引的长度一致,也可以将布尔型数组跟切片、整数(或整数序列)混合使用
data[names=='Bob',2:]array([[-0.57060877, 0.93471043],
[ 0.80884835, 1.07076835]])
data[names=='Bob',3]array([ 0.93471043, 1.07076835])
可以使用不等号(!=),也可以使用符号(~)对条件进行否定,其中负号(-)被舍弃使用了
names!='bob'array([ True, True, True, True, True, True, True], dtype=bool)
data[~(names == 'Bob')]array([[ 0.5413258 , 0.18615647, 0.57429245, -0.07045294],
[-1.57840839, 0.03816457, 0.06441022, 1.15967355],
[-1.5814758 , 0.81780567, 0.43782677, -0.91748426],
[ 2.03128426, -0.21807742, -0.73759551, 0.42158797],
[-2.13423716, 0.99993262, -1.02045863, -0.31841384]])
选取这三个名字中的两个需要组合应用多个布尔条件,使用&(和),|(或)布尔算术符号运算即可
mask=(names=='Bob')|(names=='Will')maskarray([ True, False, True, True, True, False, False], dtype=bool)
data[mask]array([[ 1.20160119, -1.05723288, -0.57060877, 0.93471043],
[-1.57840839, 0.03816457, 0.06441022, 1.15967355],
[-0.87407974, -0.28018097, 0.80884835, 1.07076835],
[-1.5814758 , 0.81780567, 0.43782677, -0.91748426]])
通过布尔型选取数组中的数据,将总数创建数据的副本,即使返回一模一样的数据也是如此
警告:python关键字and和or在布尔型数组中无效
为了将data中的所有负值都设置为0,可以这样做
data[data<0]=0dataarray([[ 1.20160119, 0. , 0. , 0.93471043],
[ 0.5413258 , 0.18615647, 0.57429245, 0. ],
[ 0. , 0.03816457, 0.06441022, 1.15967355],
[ 0. , 0. , 0.80884835, 1.07076835],
[ 0. , 0.81780567, 0.43782677, 0. ],
[ 2.03128426, 0. , 0. , 0.42158797],
[ 0. , 0.99993262, 0. , 0. ]])
通过一维数组设置整行或整列的值也是简单的
data[names!='Joe']=7dataarray([[ 7. , 7. , 7. , 7. ],
[ 0.5413258 , 0.18615647, 0.57429245, 0. ],
[ 7. , 7. , 7. , 7. ],
[ 7. , 7. , 7. , 7. ],
[ 7. , 7. , 7. , 7. ],
[ 2.03128426, 0. , 0. , 0.42158797],
[ 0. , 0.99993262, 0. , 0. ]])
花式索引 是一个Numpy术语,指的是利用整数数组进行索引
arr=np.empty((8,4))arrarray([[ -6.13838792e-078, -1.53355745e+181, -7.86332188e-031,
-4.01320607e-020],
[ -1.63080546e+176, -2.58653382e-247, -3.48443862e-020,
-1.68896544e+200],
[ -7.86331065e-031, -2.84375690e-227, 7.83497075e+012,
-1.76690439e-286],
[ -2.45631074e-145, -1.41321561e+191, -5.26157217e-228,
-3.43723434e-150],
[ -2.95588215e+191, -4.85165577e-209, -9.70435194e-083,
-1.20930730e+201],
[ -4.71890748e-200, -5.37932783e+178, -7.86322845e-031,
-1.48209356e+181],
[ -2.36374766e-064, -2.09443292e-304, -6.04055784e+195,
-1.32298607e-194],
[ -5.32612414e-025, -1.32349375e+176, -5.13949951e-209,
-4.01320607e-020]])
for i in range(8):
arr[i]=iarrarray([[ 0., 0., 0., 0.],
[ 1., 1., 1., 1.],
[ 2., 2., 2., 2.],
[ 3., 3., 3., 3.],
[ 4., 4., 4., 4.],
[ 5., 5., 5., 5.],
[ 6., 6., 6., 6.],
[ 7., 7., 7., 7.]])
为了以特定的顺序选取行子集,只需要传入一个用于指定顺序的整数列表或者ndarray即可
arr[[4,3,0,6]]array([[ 4., 4., 4., 4.],
[ 3., 3., 3., 3.],
[ 0., 0., 0., 0.],
[ 6., 6., 6., 6.]])
使用负数索引将会从末尾开始进行选取
arr[[-3,-5,-7]]array([[ 5., 5., 5., 5.],
[ 3., 3., 3., 3.],
[ 1., 1., 1., 1.]])
一次传入多个索引数组会有些特别。,其中的元素对应各个索引元组arr=np.arange(32).reshape((8,4))arrarray([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
arr[[1,5,7,2],[0,3,1,2]]array([ 4, 23, 29, 10])
最终选取的元素是(1,0)、(5,3)、(7,1)和(2,2),下面采取选取行列的子集方法
arr[[1,5,7,2]][:,[0,3,1,2]]array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])
另外一个方法:使用np.ix_函数,它可以将两个一维整数数组转换为一个用于选取方形区域的索引器
arr[np.ix_([1,5,7,2],[0,3,1,2])]array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])
花式索引和切片索引不同,它总是将数据复制到新数组中。
数组转置和轴对换
转置(response)是重塑的一种特殊形式,返回的是原数据的视图,
不会进行任何数据的复制操作,还有一个T属性
arr=np.arange(15).reshape((3,5))arrarray([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
arr.Tarray([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]])
在进行矩阵计算时,经常使用到该操作,比如利用np.dot计算矩阵的内积 X T X
arr=np.random.randn(6,3)arrarray([[-2.06876168, 0.97947713, -0.46649118],
[ 0.44427728, -1.04164276, 0.50228949],
[ 0.19183828, 0.06747897, -0.84046042],
[-0.69185812, 1.36772582, -0.27280976],
[ 1.06867616, 0.6844193 , 1.57195584],
[-0.32461881, 0.49908568, 0.1293782 ]])
np.dot(arr.T,arr)array([[ 6.24007288, -2.85300014, 2.85364119],
[-2.85300014, 4.63713872, -0.26951829],
[ 2.85364119, -0.26951829, 3.73849153]])
对于高维数组,tranpose需要得到一个由编号组成的元组才能对这些轴进行转置
arr=np.arange(16).reshape((2,2,4))arrarray([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
arr.transpose((1,0,2))array([[[ 0, 1, 2, 3],
[ 8, 9, 10, 11]],
[[ 4, 5, 6, 7],
[12, 13, 14, 15]]])
简单转置使用.T,其他的其实就是进行轴对换而已。
ndarray还有一个swapaxes方法,需要接受一对轴编号:
arrarray([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
arr.swapaxes(1,2)array([[[ 0, 4],
[ 1, 5],
[ 2, 6],
[ 3, 7]],
[[ 8, 12],
[ 9, 13],
[10, 14],
[11, 15]]])















 6640
6640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









