







SQL开发规范及其优化(Oracle为例)
1.利用PL/SQL工具进行SQL美化和格式化
-
PL/SQL美化
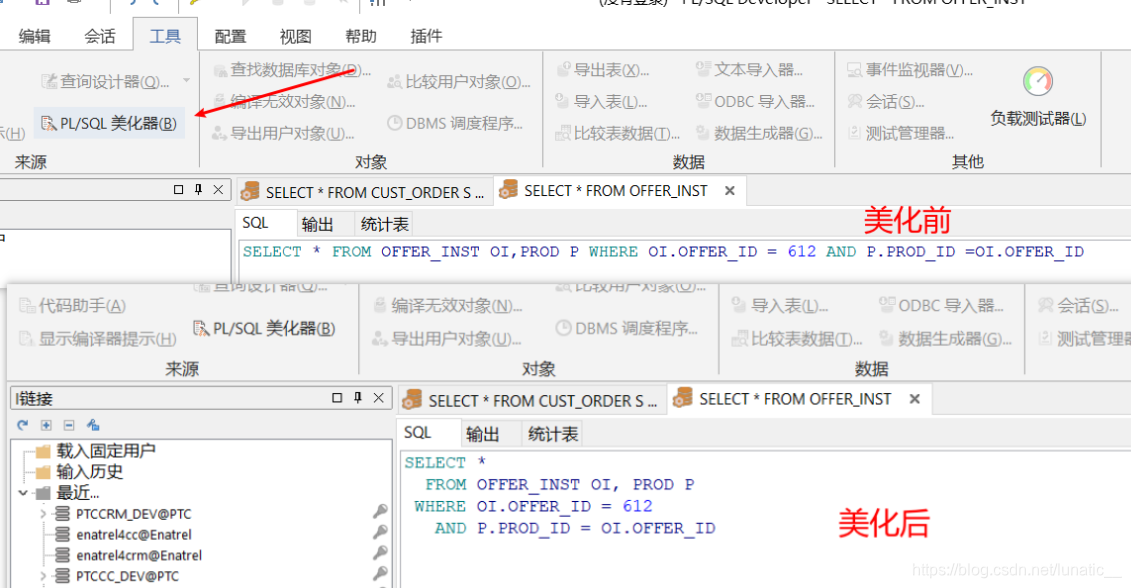
-
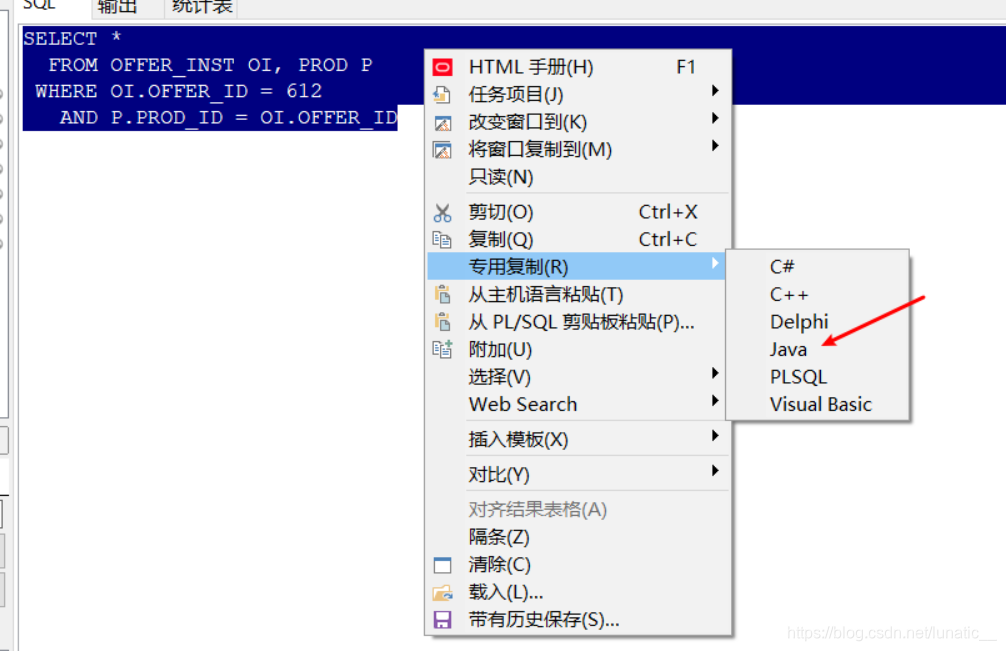
专用复制

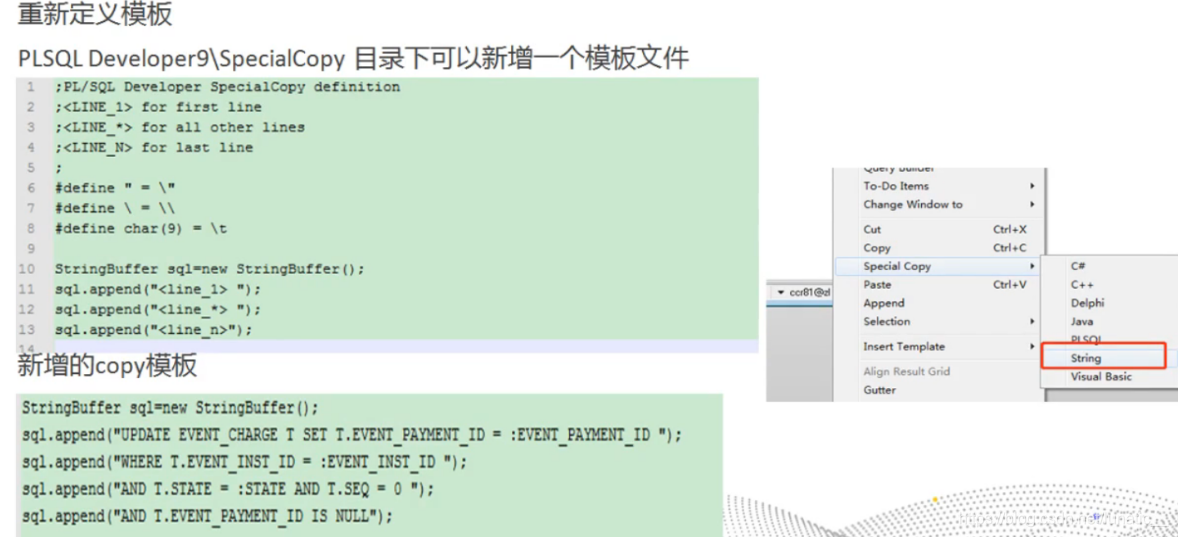
自定义模板
2.SQL规范
-
SQL语句字符全部大写。
系统出问题时,最先要查询的就是数据。要在大量的日志中快速地定位到相关SQL是比较艰难的,SQL语句全部大写可以帮助我们更快速的找到它们。
-
书写风格美化:增加空格,增加别名,换行。
3.SQL优化
-
现网频发故障点
- 大表关联,导致查询时间过长。
- 避免SELECT * 的使用,该问题会导致数据库在解析的过程中将*依次转换成所有的列名,这个工作室通过查询数据字典完成的,会导致耗费过多时间。

-
索引问题:法则:不要在建立的索引的数据列进行如下操作。
-
避免在索引字段进行计算操作。
-
避免在索引字段上使用not,<>,!=,not in,not exit,会导致查询不走索引而执行全表扫描。
-
如果不等条件的值不多,而且是确认的,可以改成为等值或IN查询,比如status状态字段一般值类别很少。
-
如果不等条件之外的值很多,可以改为>或<的形式。
-
-
-
不能用包含null值得列作为索引,任何包含null值的列都不会被包含在索引中。即使索引有多列这样的情况,只要这些列中有一列含有null,该列就会从索引中排除。
-
避免在索引列上出现数据类型转换。

- 避免在索引字段上使用函数也会导致不走索引。
如:
select id from t where substring(name,1,3)='abc'
--name以abc开头的id select id from t where datediff(day,createdate,'2005-11-30')=0--'2005-11-30'生成的id 应改为: select id from t where name like 'abc%' select id from t where createdate>='2005-11-30' and createdate<'2005-12-1'
- 对索引列使用OR将造成全表扫描(使用UNION)。
// UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
SELECT column_name(s) FROM table_name1
UNION
SELECT column_name(s) FROM table_name2
// 默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
SELECT column_name(s) FROM table_name1
UNION ALL
SELECT column_name(s) FROM table_name2
UNION ALL 命令和 UNION 命令几乎是等效的,不过 UNION ALL 命令会列出所有的值。
因为 UNION ALL 仅仅是简单的合并查询结果, 并不会做去重操作, 也不会排序, 所以 UNION ALL 效率要比 UNION 高.
所以在能够确定没有重复记录的情况下, 尽量使用 UNION ALL
-
左模糊查询也将导致全表扫描: select id from t where name like ‘%abc%’ 。若要提高效率,可以考虑全文检索。
-
如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描: select id from t where num=@num 可以改为强制查询使用索引: select id from t with(index(索引名)) where num=@num
-
应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描
如: select id from t where num/2=100 应改为: select id from t where num=100*2
-
like通配符可能导致索引失效。
-
联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。
-
并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
-
索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
-
SQL的排序对性能成本的消耗是非常大的,如果可以请把排序放在程序中来实现。
-
当数据量非常大的时候,一定要考虑分页查询,众多上线升级中由于没分页把内存库搞挂的案例比比皆是。
-
有ORDER BY 和 ROWNUM时,先给ROWNUM赋值,然后再对结果ORDER BY
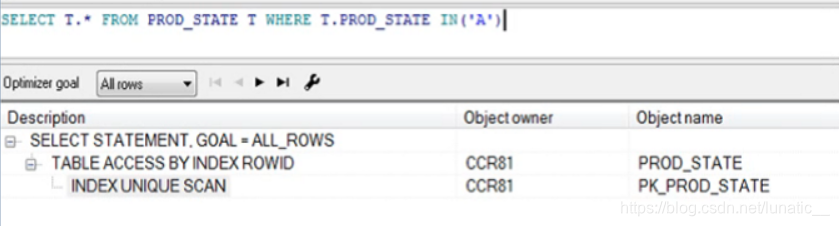
4.执行计划

我们首先看第一列的Description,下面的内容分别是我们这条SQL的执行步骤,缩进量最多的步骤最先执行,如果缩进量相同,则按照从上往下执行。
TABLE ACCESS FULL:全表扫描
INDEX UNIQUE SCAN:唯一索引范围内查找
TABLE ACCESS BY INDEX ROWID:根据索引找到的ROWID来查找需要的数据
分析步骤:
- 查看总COST,获得资源耗费的总体印象
- 按照从左往右,从上至下的方法,了解执行计划的执行步骤
- 分析表的访问方式
- 分析表的连接方式和连接顺序
总结:这里看到的执行计划,只是SQL运行前可能的执行计划,实际运行时可能因为软硬件环境的不同,而有所改变,而且cost高的执行 计划,不一定在实际运行起来,速度就一定差,我们平时需要结合执行计划,和实际测试的运行时间,来确定一个执行计划的好坏。
5.其他
-
请使用事务,特别是当查询比较耗时。如果系统出现问题,这样做会救你一命的。一般有些经验的程序员都有体会–你经常会碰到一些 不可预料的情况会导致内存崩溃。
同时,只要有可能,在程序中尽量多使用COMMIT,这样程序的性能得到提高需求也会因为COMMIT 所释放的资源而减少。
-
在程序编码时使用大数据量的数据库
程序员在开发中使用的测试数据库一般数据量都不大,可经常的是最终用户的数据量都很大。 -
多层子查询嵌套
可以考虑适当拆成几步,先生成一些临时数据表,再进行关联操作
求也会因为COMMIT 所释放的资源而减少。
-
在程序编码时使用大数据量的数据库
程序员在开发中使用的测试数据库一般数据量都不大,可经常的是最终用户的数据量都很大。 -
多层子查询嵌套
可以考虑适当拆成几步,先生成一些临时数据表,再进行关联操作














 1085
1085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









