









目录
参考:
https://splash.readthedocs.io/en/stable/
https://github.com/scrapinghub/splash
一、简介
Splash是一个Javascript渲染服务(a javascript rendering service),
1、可以很方便的通过Docker镜像启动;
2、提供丰富Http Api接口(可一定程度减少Lua脚本的编写):

3、基于Python3中Twisted和QT5实现,提供全异步(fully asynchronous) 的渲染服务,且充分利用webkit内核并发性;
4、可以方便的与Scrapy结合(Scrapy-Splash),
(1)可以执行JS进行渲染(模拟浏览器在加载页面后的JS执行)
(2)且充分利用Splash全异步(对比Selenium+ChromeDriver的线程阻塞)的特性以提升Scrapy性能;
5、官方给出的Splash特性如下(并发、全异步、截屏、Har、关闭图片加载、自定义JS、自定义Lua等):
- process multiple webpages in
parallel; - get
HTML resultsand/or takescreenshots; turn OFF imagesor useAdblock Plus rules* to make rendering faster;- execute
custom JavaScriptin page context; - write
Luabrowsing scripts; - develop Splash Lua scripts in Splash-Jupyter Notebooks.
- get detailed rendering info in
HARformat.
二、安装Splash
参考:
https://splash.readthedocs.io/en/stable/install.html
https://splash.readthedocs.io/en/stable/faq.html#how-to-run-splash-in-production
https://splash.readthedocs.io/en/stable/faq.html#i-m-getting-lots-of-504-timeout-errors-please-help
长期运行、4GB RAM限制、Daemonizes、自动重启 - 启动命令示例:
docker run -d -p 8050:8050 --memory=4.5G --restart=always scrapinghub/splash:master --maxrss 4000
注:
1、splash默认没有内存使用限制,可通过–memery(docker选项)和–maxrss(splash选项)来进行限制(已避免耗光系统内存);
2、可通过–restart=always来设置splash崩溃后(如内存超过限制)自动重启;
3、可通过–slots来设置splash处理并发度(亦可通过多实例+Haproxy来提高并发处理能力)
When all slots are used a request is put into a queue.
The thing is that a timeout starts to tick once Splash receives a request, not when Splash starts to render it.
If a request stays in an internal queue for a long time it can timeout even if a website is fast and splash is capable of rendering the website.
注: 可通过启动项–help获取启动义参数说明
splash@mx-splash-fcd98cf6b-zx68n:/app/dockerfiles/tests$ splash --help
Usage: splash [options]
Options:
-h, --help show this help message and exit
-f LOGFILE, --logfile=LOGFILE
log file
-m MAXRSS, --maxrss=MAXRSS
exit if max RSS reaches this value (in MB or ratio of
physical mem) (default: 0)
--proxy-profiles-path=PROXY_PROFILES_PATH
path to a folder with proxy profiles
--js-profiles-path=JS_PROFILES_PATH
path to a folder with javascript profiles
--no-js-cross-domain-access
disable support for cross domain access when executing
custom javascript (default)
--js-cross-domain-access
enable support for cross domain access when executing
custom javascript (WARNING: it could break rendering
for some of the websites)
--allowed-schemes=ALLOWED_SCHEMES
comma-separated list of allowed URI schemes (default:
http,https,data,ftp,sftp,ws,wss)
--filters-path=FILTERS_PATH
path to a folder with network request filters
--xvfb-screen-size=XVFB_SCREEN_SIZE
screen size for xvfb (default: 1024x768)
--disable-private-mode
disable private mode (WARNING: data may leak between
requests)
--disable-xvfb disable Xvfb auto start
--disable-lua-sandbox
disable Lua sandbox
--disable-browser-caches
disables in-memory and network caches used by webkit
--browser-engines=BROWSER_ENGINES
Comma-separated list of enabled browser engines
(default: webkit,chromium). Allowed engines are
chromium and webkit.
--dont-log-args=DONT_LOG_ARGS
Comma-separated list of request args which values
won't be logged, regardless of the log level. Example:
lua_source,password
--lua-package-path=LUA_PACKAGE_PATH
semicolon-separated places to add to Lua package.path.
Each place can have a ? in it that's replaced with the
module name.
--lua-sandbox-allowed-modules=LUA_SANDBOX_ALLOWED_MODULES
semicolon-separated list of Lua module names allowed
to be required from a sandbox.
--strict-lua-runner enable additional internal checks for Lua scripts
(WARNING: for debugging only)
-v VERBOSITY, --verbosity=VERBOSITY
verbosity level; valid values are integers from 0 to 5
(default: 1)
--version print Splash version number and exit
-p PORT, --port=PORT port to listen to (default: 8050)
-i IP, --ip=IP binded ip listen to (default: 0.0.0.0)
-s SLOTS, --slots=SLOTS
number of render slots (default: 20)
--max-timeout=MAX_TIMEOUT
maximum allowed value for timeout (default: 90.0)
--disable-ui disable web UI
--disable-lua disable Lua scripting
--argument-cache-max-entries=ARGUMENT_CACHE_MAX_ENTRIES
maximum number of entries in arguments cache
(default:500)
启动完成后,可通过http://localhost:8050来进行访问:
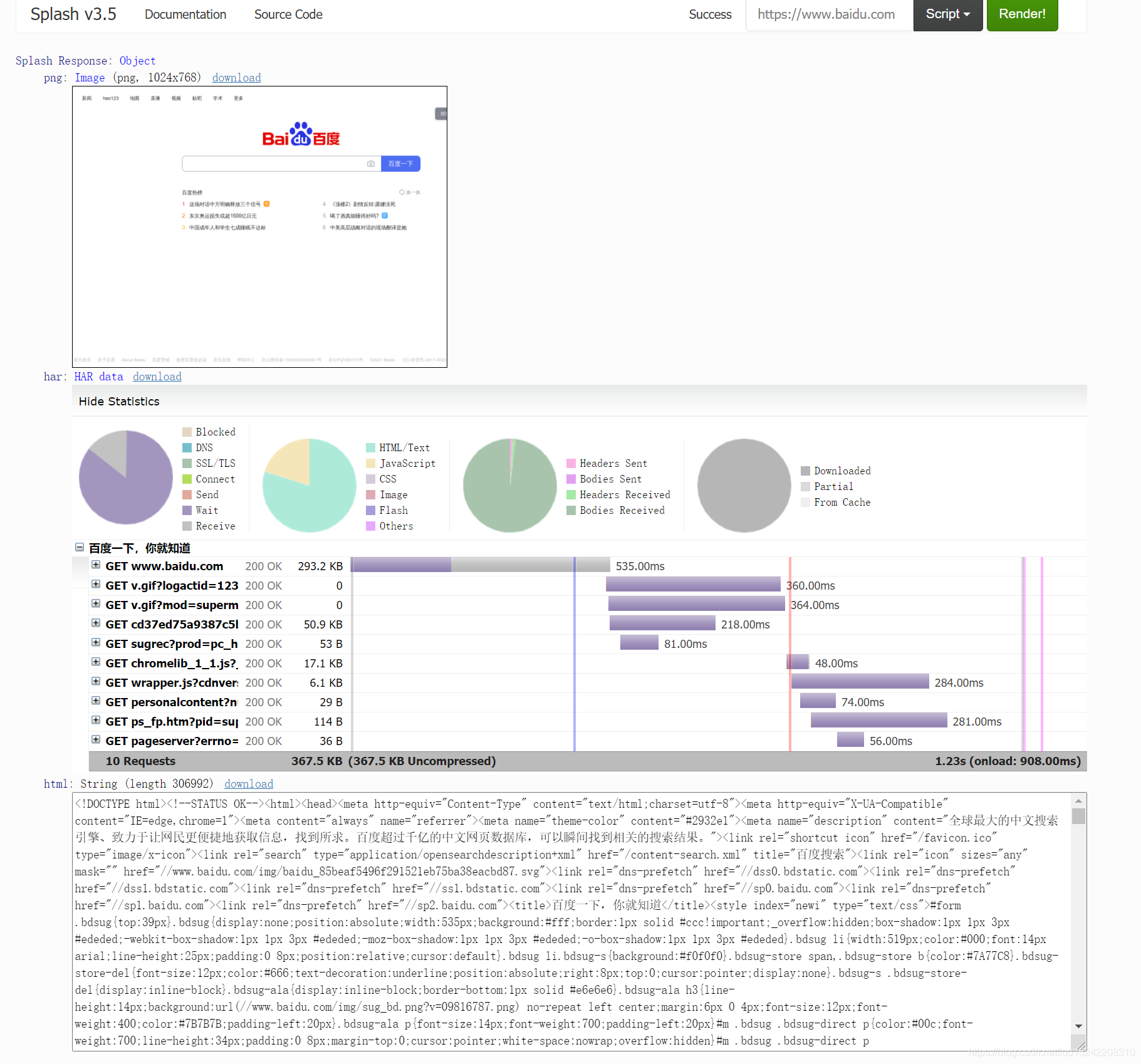
修改url为https://www.baidu.com后点击按钮Render me!后,结果如下:
三、使用Splash HTTP API
具体HTTP API参见文档:
https://splash.readthedocs.io/en/stable/api.html

render.html
# 请求百度首页html内容,且禁用图片加载
# 返回结果为完整网页的html
curl http://192.168.3.5:8050/render.html?url=http://www.baidu.com&images=0
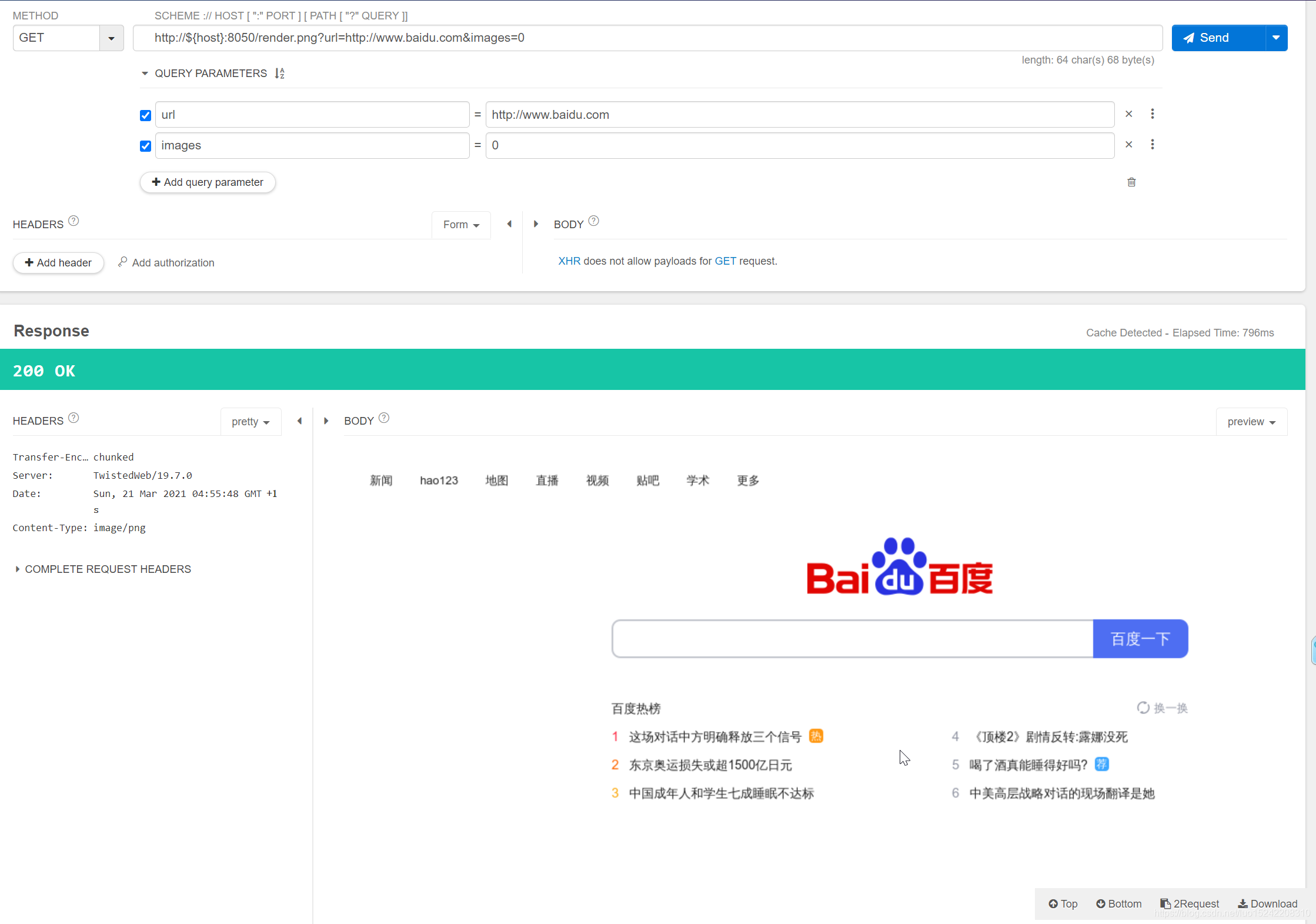
render.png、render.jpeg
# 请求百度首页截图
# 虽然此处images=0禁用图片加载,但是之前缓存过的图片还是会被渲染进图片
curl http://192.168.3.5:8050/render.png?url=http://www.baidu.com&images=0
curl http://192.168.3.5:8050/render.jpeg?url=http://www.baidu.com&images=0
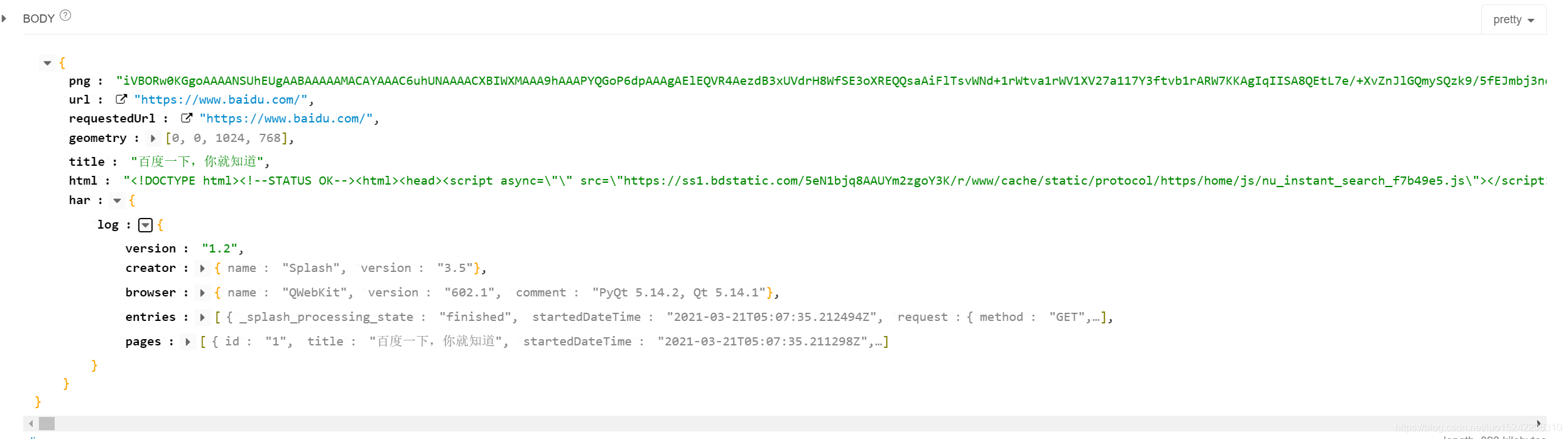
render.json
# 组合多个endpoint并以Json形式返回结果
# 组合render.html、render.png、render.har
curl http://192.168.3.5:8050/render.json?url=http://www.baidu.com&images=0&html=1&png=1&har=1
四、Scrapy-Splash💘
参考:
https://github.com/scrapy-plugins/scrapy-splash
1、python集成Scrapy-Splash
pip install scrapy-splash
2、使用Splash(Requests, Responses)
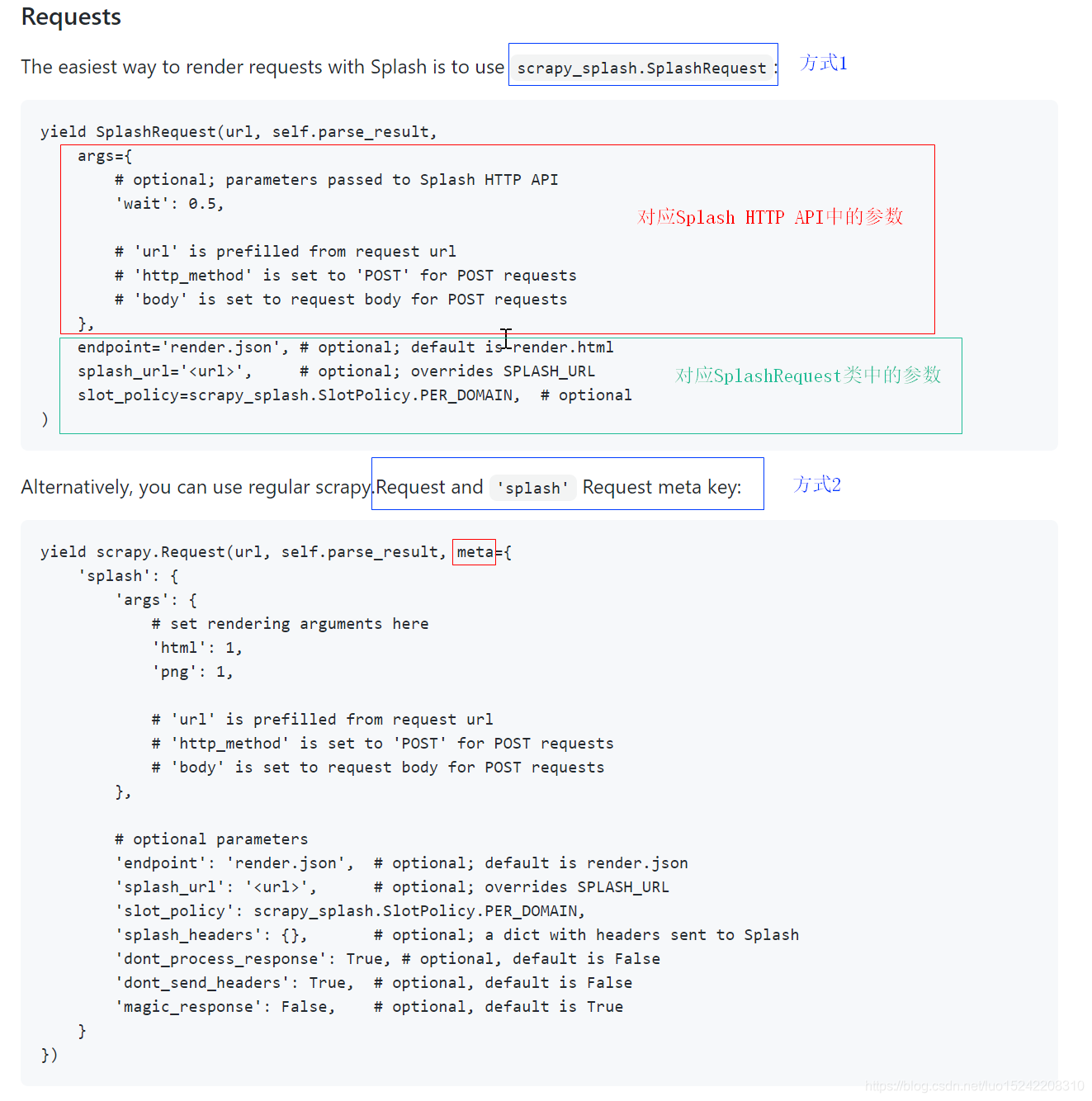
以上截图部分中,
Splash HTTP API参数:🔗https://splash.readthedocs.io/en/stable/api.html#
SplashRequest类参数:🔗https://github.com/scrapy-plugins/scrapy-splash
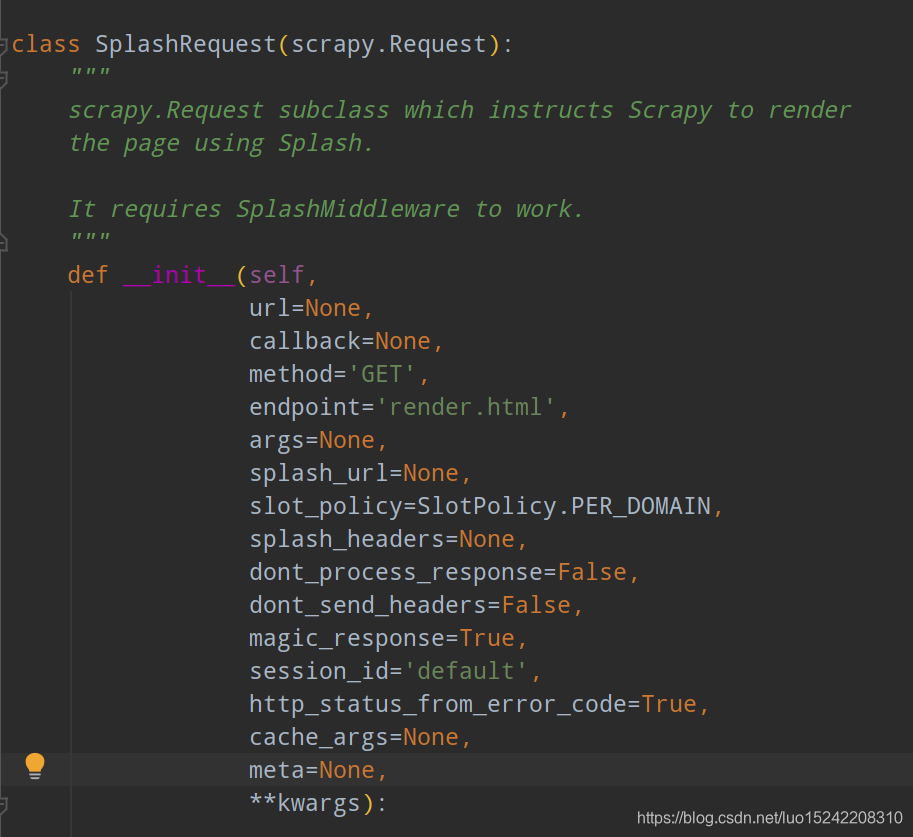

注:
Session Handling必须使用endpoint: execute即lua脚本的形式(待使用时再具体研究)
function main(splash)
splash:init_cookies(splash.args.cookies)
-- ... your script
return {
cookies = splash:get_cookies(),
-- ... other results, e.g. html
}
end
3、Scrapy settings.py配置
参见:https://github.com/scrapy-plugins/scrapy-splash
Scrapy集成Scrapy-Splash settings.py具体配置修改如下:
# 配置Splash,参见:https://github.com/scrapy-plugins/scrapy-splash
# Splash url
SPLASH_URL = 'http://192.168.3.5:8050'
# Enable the Splash downloader middleware
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# Enable SplashDeduplicateArgsMiddleware - support cache_args feature
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
# Set a custom DUPEFILTER_CLASS - dup filter
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# If you use Scrapy HTTP cache then a custom cache storage backend is required.
# scrapy-splash provides a subclass of scrapy.contrib.httpcache.FilesystemCacheStorage:
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
# Enable debugging cookies in the SplashCookiesMiddleware: logs sent and received cookies for all requests.
# similar to COOKIES_DEBUG for the built-in scarpy cookies middleware:
SPLASH_COOKIES_DEBUG = False
# log all 400 errors from Splash.
# They are important because they show errors occurred when executing the Splash script.
# Set it to False to disable this logging.
SPLASH_LOG_400 = True
# It specifies how concurrency & politeness are maintained for Splash requests,
# and specify the default value for slot_policy argument for SplashRequest
# PER_DOMAIN | SINGLE_SLOT | SCRAPY_DEFAULT
from scrapy_splash import SlotPolicy
SPLASH_SLOT_POLICY = SlotPolicy.PER_DOMAIN
4、Scrapy Spider集成Splash
Get HTML contents:
import scrapy
from scrapy_splash import SplashRequest
class MySpider(scrapy.Spider):
start_urls = ["http://example.com", "http://example.com/foo"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url, self.parse, args={'wait': 0.5})
def parse(self, response):
# response.body is a result of render.html call; it
# contains HTML processed by a browser.
# ...
Get HTML contents and a screenshot:
import json
import base64
import scrapy
from scrapy_splash import SplashRequest
class MySpider(scrapy.Spider):
# ...
splash_args = {
'html': 1,
'png': 1,
'width': 600,
'render_all': 1,
}
yield SplashRequest(url, self.parse_result, endpoint='render.json',
args=splash_args)
# ...
def parse_result(self, response):
# magic responses are turned ON by default,
# so the result under 'html' key is available as response.body
html = response.body
# you can also query the html result as usual
title = response.css('title').extract_first()
# full decoded JSON data is available as response.data:
png_bytes = base64.b64decode(response.data['png'])
# ...
Run a simple Splash Lua Script
import json
import base64
from scrapy_splash import SplashRequest
class MySpider(scrapy.Spider):
# ...
script = """
function main(splash)
assert(splash:go(splash.args.url))
return splash:evaljs("document.title")
end
"""
yield SplashRequest(url, self.parse_result, endpoint='execute',
args={'lua_source': script})
# ...
def parse_result(self, response):
doc_title = response.body_as_unicode()
# ...
设置headers、操作cookies更多Lua脚本示例,
参见:https://github.com/scrapy-plugins/scrapy-splash
以下为我测试的一个门户网站的spider代码:
class MySpider(scrapy.Spider):
name = 'my_spider'
# 示例为一个门户网站,爬取网站的一个文章列表(不暴露具体网址了😭以免被暴力爬取)
allowed_domains = ['www.xxx.cn']
start_urls = ['http://www.xxx.cn/viewCmsCac.do?cacId=00000000361142360136385855fe2882&offset=0']
splash_args = {
'image': 0,
'wait': 0.5
}
def start_requests(self):
for url in self.start_urls:
# 使用SplashRequest
yield SplashRequest(url, self.parse, args=self.splash_args)
def parse(self, response):
# response.body is a result of render.html call; it
# contains HTML processed by a browser.
# self.logger.info(f"resp_main_text: {response.text}")
# 提取文章列表中的链接
links = response.css('td.xin2zuo1 a::attr(href)').getall()
for link_path in links:
# 将文章链接转换为SplashRequest
yield SplashRequest(response.urljoin(link_path), self.parse_detail, args=self.splash_args)
def parse_detail(self, response):
# 解析文章内容详情
title = response.css("div.newpg_con > div.newpg_son > div.newpg_tit::text").get()
publish_date = response.css("body > div.newpg_con > div.newpg_son > div.newpg_blow::text").get()
text = response.css("div.newpg_con > div.newpg_son > div.newpg_news::text").get()
# 打印文章内容
self.logger.info(f"CRAWL_HTML:\ntitle: {title}\npublish_date: {publish_date}\ntext: {text}")
部分运行日志:
2021-03-21 18:27:41 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.xxx.cn/sitegroup/root/html/00000000361142360136385855fe2882/20210317104409617.html via http://192.168.3.5:8050/render.html> (referer: None)
2021-03-21 18:27:41 [my_gov_spider] INFO: CRAWL_HTML:
title: 市中级人民法院召开全市法院优化法治化营商环境动员部署视频会议
publish_date: 发布人:lj 来源: xxx日报 时间:2021-03-17 10:43:39 浏览
text: □记者 王璐
2021-03-21 18:27:43 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.xxx.cn/sitegroup/root/html/00000000361142360136385855fe2882/20210317104539771.html via http://192.168.3.5:8050/render.html> (referer: None)
2021-03-21 18:27:43 [my_gov_spider] INFO: CRAWL_HTML:
title: 市中级人民法院召开全市法院队伍教育整顿学习教育环节推进会视频会议
publish_date: 发布人:lj 来源: xxx日报 时间:2021-03-17 10:44:42 浏览
text: □记者 王璐
2021-03-21 18:27:49 [scrapy.extensions.logstats] INFO: Crawled 27 pages (at 27 pages/min), scraped 0 items (at 0 items/min)
2021-03-21 18:27:58 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.xxx.cn/sitegroup/root/html/00000000361142360136385855fe2882/20210316092195616.html via http://192.168.3.5:8050/render.html> (referer: None)
2021-03-21 18:27:58 [my_gov_spider] INFO: CRAWL_HTML:
title: 开新局 出新彩丨村边水边尽植树 生态屏障可守护
publish_date: 发布人:lj 来源: xxx日报 时间:2021-03-16 09:20:06 浏览
text: □记者 邓娴


















 392
392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











