







相对于二分查找和差值查找,斐波那契查找的实现略显复杂。但是在明白它的主体思想之后,掌握起来也并不太难。
既然叫斐波那契查找,首先得弄明白什么是斐波那契数列。相信大家对这个著名的数列也并不陌生,无论是C语言的循环、递归,还是高数的数列,斐波那契数列都是一个重要的存在。而此处主要是用到了它的一条性质:前一个数除以相邻的后一个数,比值无限接近黄金分割。
就笔者而言,这种查找的精髓在于采用最接近查找长度的斐波那契数值来确定拆分点,初次接触的童鞋,请在读完下文后,自觉回过头来仔细体会这句话。举个例子来讲,现有长度为9的数组,要对它进行拆分,对应的斐波那契数列(长度先随便取,只要最大数大于9即可){1,1,2,3,5,8,13,21,34},不难发现,大于9且最接近9的斐波那契数值是f[6]=13,为了满足所谓的黄金分割,所以它的第一个拆分点应该就是f[6]的前一个值f[5]=8,即待查找数组array的第8个数,对应到下标就是array[7],依次类推。
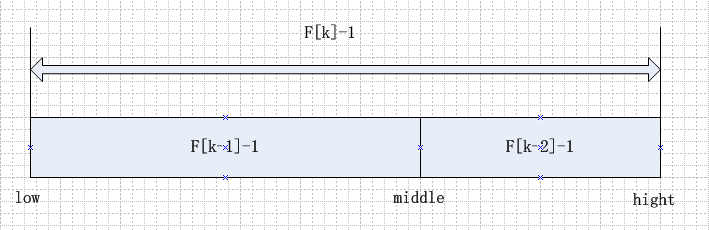
推演到一般情况,假设有待查找数组array[n]和斐波那契数组F[k],并且n满足n>=F[k]-1&&n < F[k+1]-1,则它的第一个拆分点middle=F[k]-1。
这里得注意,如果n刚好等于F[k]-1,待查找数组刚好拆成F[k-1]和F[k-2]两部分,那万事大吉你好我好;然而大多数情况并不能尽人意,n会小于F[k]-1,这时候可以拆成完整F[k-1]和残疾的F[k-2]两部分,那怎么办呢?
聪明的前辈们早已想好了解决办法,对了,就是补齐,用最大的数来填充F[k-2]的残缺部分,如果查找的位置落到补齐的部分,那就可以确定要找的那个数就是最后一个最大的了。
不妨来看张图,更清楚一点。
条件:
(1)数据必须采用顺序存储结构;(2)数据必须有序。
原理:
(1)最接近查找长度的斐波那契值来确定拆分点;(2)黄金分割。
时间复杂度:
与拆半查找一样,也是logn。不少博客说,在处理海量数据时,拆分查找的middle = (low + hight)/2,除法可能会影响效率,而斐波那契的middle = low + F[k-1] -1,纯加减计算,速度要快一些。我觉得是扯淡,因为完全可以用middle = (loe+hight)>>2来代替,要知道相比于加减乘除而言,位运算的效率可是最高的哟。
实现:
还是惯例,能上代码就不说话环节。
public class 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 170
170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









