







🧡1. 前言🧡
跟队友花了三天模拟2020C题,现在整理一下一些数据处理的代码,以及在模拟中没有解决的问题。方便以后回溯笔记。
🧡2. 数据处理🧡
2.1 导入数据,并做相关预处理
import pandas as pd
import numpy as np
import re
# import data
df1=pd.read_excel('oridata/附件1:123家有信贷记录企业的相关数据.xlsx',sheet_name='企业信息')
df2=pd.read_excel('oridata/附件1:123家有信贷记录企业的相关数据.xlsx',sheet_name='进项发票信息')
df3=pd.read_excel('oridata/附件1:123家有信贷记录企业的相关数据.xlsx',sheet_name='销项发票信息')
# 删除df2、df3重复行
duplicate_rows = df2.duplicated() # 检测重复行 从前向后查,后一个重复则true
print(duplicate_rows.sum())
df2 = df2[~duplicate_rows]
duplicate_rows = df3.duplicated() # 检测重复行 从前向后查,后一个重复则true
print(duplicate_rows.sum())
df3 = df3[~duplicate_rows]
# 处理企业代号,将 E1 ===> 数字1 使用正则表达式提取数字部分并转换为整数
df1['企业代号'] = df1['企业代号'].apply(lambda x: int(re.findall(r'\d+', x)[0]))
df2['企业代号'] = df2['企业代号'].apply(lambda x: int(re.findall(r'\d+', x)[0]))
df3['企业代号'] = df3['企业代号'].apply(lambda x: int(re.findall(r'\d+', x)[0]))
# 处理时间数据, 将 2017-1-1 ==> 年份属性2017 、 月份属性1
df2['开票日期'] = pd.to_datetime(df2['开票日期'])
df2['年份'] = df2['开票日期'].dt.year
df2['月份'] = df2['开票日期'].dt.month
df3['开票日期'] = pd.to_datetime(df3['开票日期'])
df3['年份'] = df3['开票日期'].dt.year
df3['月份'] = df3['开票日期'].dt.month
# 获取所有公司的列表 1,2,3,.....123
all_companies = df1['企业代号'].unique()
df3
2.2 信誉等级和是否违约 转成英文
"""
信誉等级和是否违约 中文转英文
"""
data0=df1.copy()
toClassNum_map1={'A': 3, 'B': 2, 'C': 1,'D':0}
data0['信誉评级'] = data0['信誉评级'].map(toClassNum_map1)
toClassNum_map2={'是': 0, '否': 1}
data0['是否违约'] = data0['是否违约'].map(toClassNum_map2)
data0=data0[['企业代号','信誉评级','是否违约']]
data0
2.3 利用groupby统计各种指标
基本原理:
2.3.1 统计三年总买入、卖出的价税合计总金额 和 各年买入、卖出的价税合计总金额
data1=df2.copy()
data2=df3.copy()
# 统计三年总买入、卖出的价税合计总金额
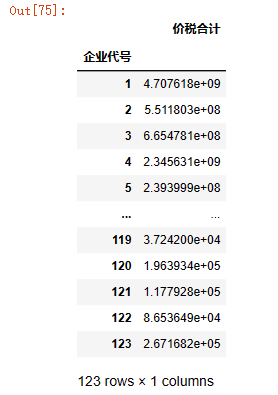
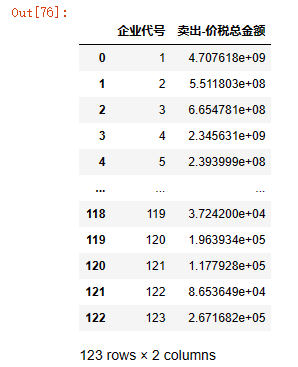
data1_totalmoney = data1.groupby('企业代号')['价税合计'].sum().reset_index(name='买入-价税总金额')
data2_totalmoney = data2.groupby('企业代号')['价税合计'].sum().reset_index(name='卖出-价税总金额')
data_totoalmoney_merge=pd.merge(data1_totalmoney,data2_totalmoney,on='企业代号')
data_totoalmoney_merge
# 各年买入、卖出的价税合计总金额
data1_yearmoney = data1.groupby(['企业代号','年份']).agg({'价税合计':'sum'})
data2_yearmoney = data2.groupby(['企业代号','年份']).agg({'价税合计':'sum'})
print(data1_yearmoney) # 查看结果只有356行 != 123*3,说明有些企业少了某些年的数据,计数为0,而grougby函数不会展示计数为0的分组,因此需要填充缺失年
mulidx=[] # 生成二维索引 (企业代号、年份)
for i in range(1,123+1): # 1-123
for j in range(2017,2019+1): # 2017、2018、2019
mulidx.append((i,j))
mulidx=pd.MultiIndex.from_tuples(mulidx,names=["企业代号", "年份"]) # 转为二维行索引,命名为("企业代号", "年份")
data1_yearmoney=data1_yearmoney.reindex(mulidx, fill_value=0)
data2_yearmoney=data2_yearmoney.reindex(mulidx, fill_value=0)
data_yearmoney_merge=pd.merge(data1_yearmoney,data2_yearmoney,left_index=True, right_index=True,suffixes=('_买入', '_卖出'))
data_yearmoney_merge
#

2.3.2 统计三年总买入、卖出的总发票数和违约发票数
"""
违约率
"""
data3=df2.copy()
data4=df3.copy()
# ===============统计三年总买入、卖出的总发票数和违约发票数=============
# 总发票个数
data3_totalPay=data3.groupby('企业代号').agg({'发票号码':'count'})
data3_totalPay=data3_totalPay.reindex(all_companies ,fill_value=0)
data3_totalPay=data3_totalPay.rename(columns={'发票号码':'买入-总发票次数'})
data4_totalPay=data4.groupby('企业代号').agg({'发票号码':'count'})
data4_totalPay=data4_totalPay.reindex(all_companies ,fill_value=0)
data4_totalPay=data4_totalPay.rename(columns={'发票号码':'卖出-总发票次数'})
data_totalPay_merge=pd.merge(data3_totalPay,data4_totalPay,on='企业代号')
data_totalPay_merge
# 违约发票个数
data3=data3[(data3['价税合计'] < 0 ) | (data3['发票状态']=='作废状态')]
data3_totalBadPay=data3.groupby('企业代号').agg({'发票号码':'count'})
data3_totalBadPay=data3_totalBadPay.reindex(all_companies ,fill_value=0)
data3_totalBadPay=data3_totalBadPay.rename(columns={'发票号码':'买入-总违约发票次数'})
data4=data4[(data4['价税合计'] < 0 ) | (data4['发票状态']=='作废状态')]
data4_totalBadPay=data4.groupby('企业代号').agg({'发票号码':'count'})
data4_totalBadPay=data4_totalBadPay.reindex(all_companies ,fill_value=0)
data4_totalBadPay=data4_totalBadPay.rename(columns={'发票号码':'卖出-总违约发票次数'})
data_totalBadPay_merge=pd.merge(data3_totalBadPay,data4_totalBadPay,on='企业代号')
data_totalBadPay_merge
2.3.3 统计各公司营业时间(月数)
"""
营业时间
"""
data5=data2.copy()
data5['年-月']= data5['开票日期'].dt.strftime('%Y-%m')
# 使用 drop_duplicates 方法按照 '企业代号' '年-月' 进行分组,并保留每个组别的第一条数据
data5 = data5.drop_duplicates(subset=['企业代号','年-月'], keep='first')
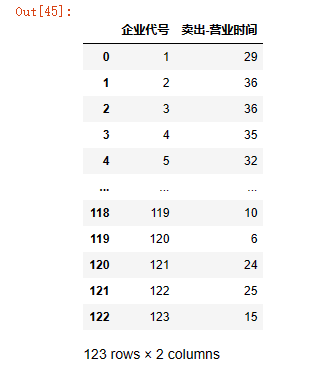
data5 = data5.groupby(['企业代号'])['年-月'].size().reset_index(name='卖出-营业时间')
data5
2.4 总结
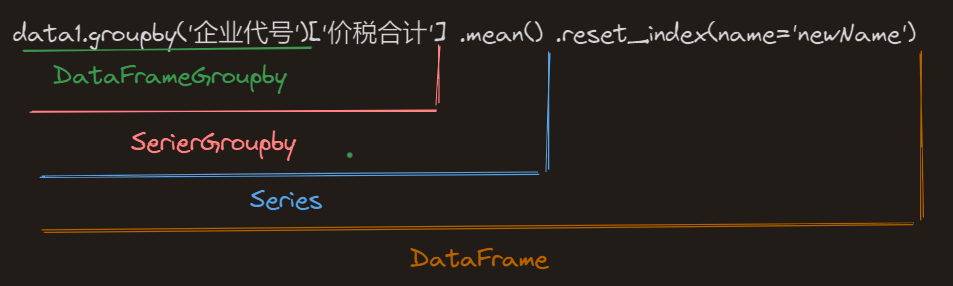
2.4.1 agg{sum}和sum区别?
- 统计个数时,data2.groupby(‘企业代号’).agg({‘价税合计’:‘sum’}) 和 **data2.groupby(‘企业代号’)[‘价税合计’].sum().reset_index(name=‘卖出-价税总金额’)**作用是否一样?
看图,差别在于:前者将企业代号(从1开始)作为行索引,后者重新生成一个(从0开始)的行索引。
前者的好处是当需要填充缺失值时,可以用reindex根据企业代号填充;后者的好处是方便pd.concat合并多个表
2.4.2 pd.concat 和 pd.merge的区别?
- pd.concat
根据轴相连
一次可以连接多个表
join:outer、inner,其中inner:上下拼接的时候,保留了共有的列信息! 左右拼接的时候保留了共有的行信息! - pd.merge
根据共有属性相连
一次只能连接两张表
join: outer、inner、left、right
on:共同属性列
2.4.3 groupby其他有用的参数
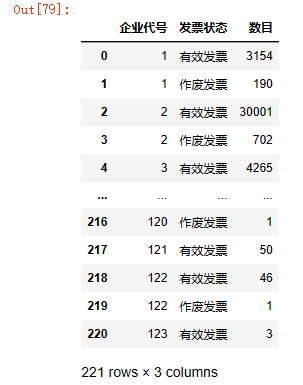
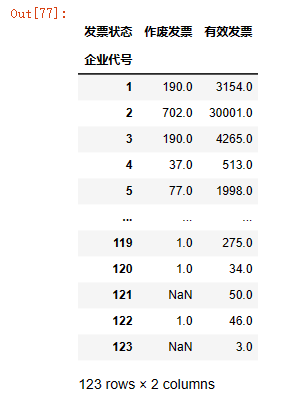
- unstack可以将分组的行索引变成列索引
test=data1.groupby('企业代号')['发票状态'].value_counts().unstack()
test
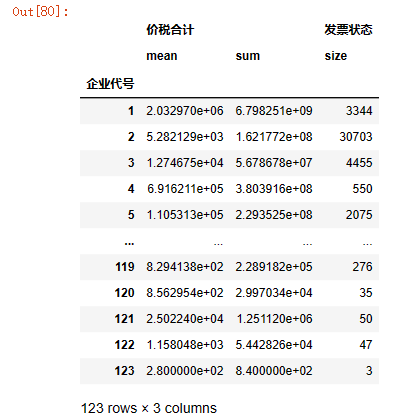
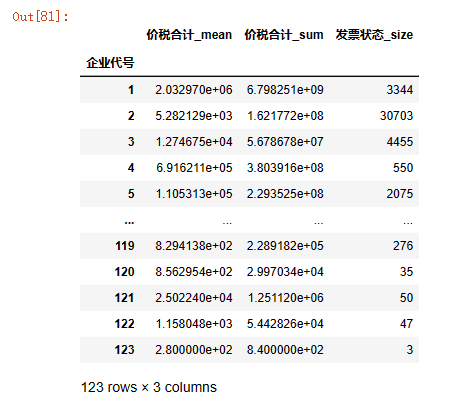
2. 当agg对多组进行多个操作后,会存在两维列索引,以下展示如何转为一维列索引
test=data1.groupby('企业代号').agg({'价税合计':['mean','sum'],'发票状态':'size'})
test.columns = ['_'.join(col).strip() for col in test.columns.values] # 合并多级列
test
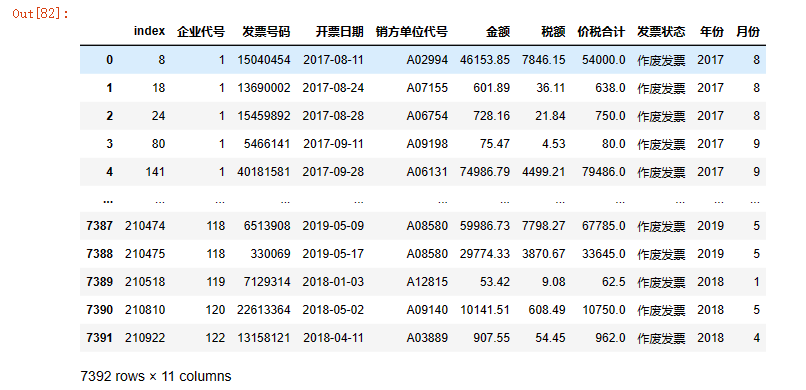
3. get_group筛选出满足特定条件的组
test=data1.groupby('发票状态').get_group('作废发票').reset_index() # 筛选出满足条件的
test
2.4.4 利用globals简化代码
如下,已经定义了10个变量,想要输出它们的长度
print(df1.count())
print(df2.count())
print(df3.count())
print(df4.count())
print(df5.count())
print(df6.count())
print(df7.count())
print(df8.count())
print(df9.count())
print(df10.count())
# gloabs()简化
for i in range(10):
print(globals()[f'df{i+1}'].count())
🧡3. 画图🧡
配色方案:红色–#d7003a,绿色–green,混淆矩阵的cmap–Greens
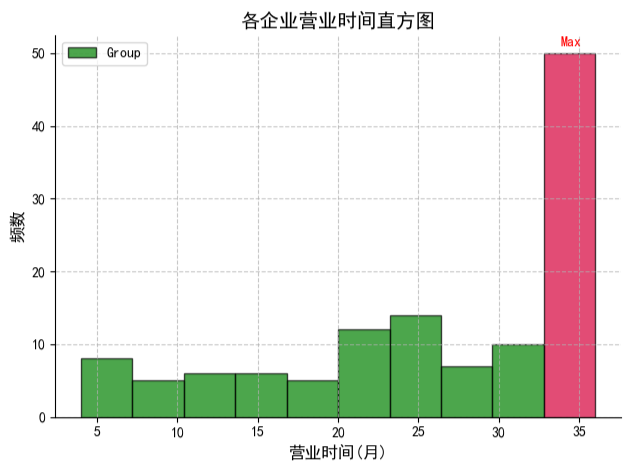
3.1 营业时间直方图
"""
主要设置:
bin 调整柱子数目
light_index 调整哪个柱子为突出色
xytext 调整位置
"""
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 为了支持中文字体
plt.rcParams['axes.unicode_minus'] = False # 上述字库没负号,因此负号不进行字体变换
data1=pd.read_excel('out/t1_123_指标.xlsx')
data1=data1['卖出-营业时间']
fig, ax = plt.subplots()
bins = 10 #直方图的柱子数目
colors = ['g']
n, bins, patches = ax.hist(data1, bins=bins, color=colors[0], alpha=0.7, label='Group', edgecolor='black')
# 设置最高利润的柱子颜色为红色
light_index=9
patches[light_index].set_facecolor('#d7003a')
# 标注最高利润的柱子
ax.annotate('Max', xy=(bins[light_index], n[light_index]), xycoords='data',
xytext=(12, 5), textcoords='offset points', color='red', weight='bold')
ax.legend()
ax.set_xlabel('营业时间(月)', fontsize=12)
ax.set_ylabel('频数', fontsize=12)
ax.set_title('各企业营业时间直方图', fontsize=14)
ax.tick_params(axis='both', which='major', labelsize=10)
ax.grid(True, linestyle='--', alpha=0.7)
# ax.set_facecolor('#f0f0f0')
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
plt.tight_layout() # 自动调整子图或图形的布局,使其适应绘图区域,避免重叠和裁剪
plt.savefig('img/营业时间.png',dpi=300) # 在plt.show()之前调用
plt.show()
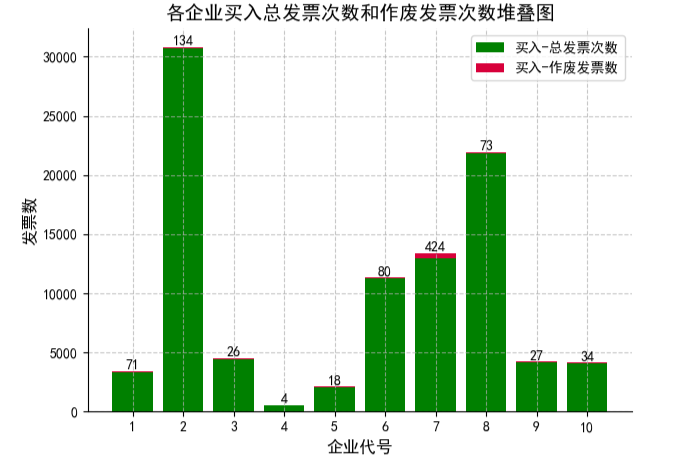
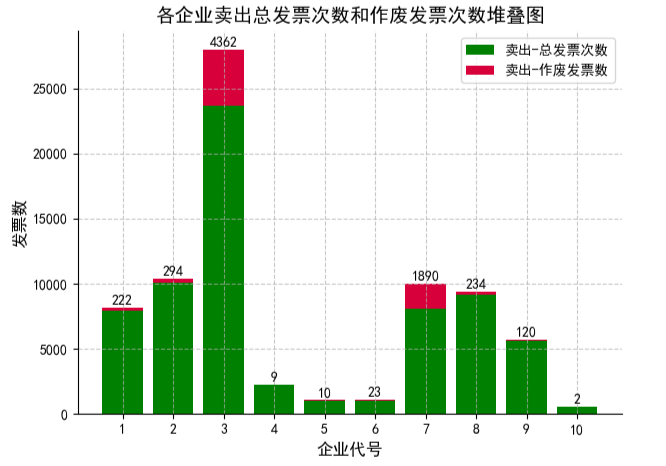
3.2 各企业买入、卖出总发票次数和作废发票次数堆叠图(前10个企业)
"""
堆叠图
主要设置:
ax.text第二个参数 根据实际数值设置文本高度
"""
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 为了支持中文字体
plt.rcParams['axes.unicode_minus'] = False # 上述字库没负号,因此负号不进行字体变换
data=pd.read_excel('out/t1_123_指标.xlsx')
data2=data['买入-作废发票数'].head(10)
data1=data['买入-总发票次数'].head(10)
x_labels=data['企业代号'].head(10)
fig, ax = plt.subplots()
# 绘制第一组数据的柱状图
bar1=ax.bar(x_labels, data1, label='买入-总发票次数',color='g')
# 绘制第二组数据的柱状图,底部从第一组数据开始
bar2=ax.bar(x_labels, data2, bottom=data1, label='买入-作废发票数',color='#d7003a')
# 在每个柱子的顶部添加文本
for rect1, rect2 in zip(bar1, bar2):
height1 = rect1.get_height()
height2 = rect2.get_height()
ax.text(rect2.get_x() + rect2.get_width() / 2, height1+height2+1000,
f'{height2}', ha='center', va='top')
ax.legend()
ax.set_xlabel('企业代号', fontsize=12)
ax.set_ylabel('发票数', fontsize=12)
ax.set_title('各企业总发票次数和作废发票次数堆叠图', fontsize=14)
ax.tick_params(axis='both', which='major', labelsize=10)
ax.grid(True, linestyle='--', alpha=0.7)
# ax.set_facecolor('#f0f0f0')
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
plt.tight_layout() # 自动调整子图或图形的布局,使其适应绘图区域,避免重叠和裁剪
plt.xticks(range(1,11), x_labels)
plt.savefig('img/总-作废1.png',dpi=300)
plt.show()
3.3 买入卖出范围频数图
"""
范围频数图
主要设置:
bins1、bins2 设置范围
data 根据print结果手动输入变量,第一列代表bins1、第二列代表bins2
width 设置柱形宽度
ax.bar 第二个参数设置与xlabels对齐
"""
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 为了支持中文字体
plt.rcParams['axes.unicode_minus'] = False # 上述字库没负号,因此负号不进行字体变换
data=pd.read_excel('out/t1_123_指标.xlsx')
# print(data.describe())
data1=data['买入-价税总金额']
data2=data['卖出-价税总金额']
# 自定义范围
bins1 = [0, 1e5, 1e6, 1e7, 1e8, 1e10] # 范围为[0, 20), [20, 40), [40, 60)
bins2 = [0, 1e5, 1e6, 1e7, 1e8, 1e10]
# 使用cut函数对数据进行划分
categories1 = pd.cut(data1, bins=bins1)
categories2 = pd.cut(data2, bins=bins1)
# 使用value_counts函数统计各范围的数据个数
count1 = categories1.value_counts()
count2 = categories2.value_counts()
print(count1)
print(count2)
# 生成示例数据
groups = ['0-1e5', '1e5-1e6', '1e6-1e7', '1e7-1e8', '1e8-1e10']
indicators = ['买入-价税总金额', '卖出-价税总金额']
data = np.array(
[
[28,11],
[31,24],
[30,34],
[31,45],
[3,9]
]
)
fig, ax = plt.subplots()
width = 0.2
colors = ['g', '#d7003a']
for i in range(len(groups)):
x = (np.arange(len(indicators)) - len(indicators)//2) * width + i # 距离
print(x)
for j in range(len(indicators)):
ax.bar(x[j]+0.1, data[i][j], width, color=colors[j], label=indicators[j] if i == 0 else '')
ax.legend(loc='upper left')
ax.set_xlabel('金额范围', fontsize=12)
ax.set_ylabel('数目', fontsize=12)
ax.set_title('买入卖出价税总金额', fontsize=14)
ax.set_xticks(np.arange(len(groups)))
ax.set_xticklabels(groups)
plt.savefig('img/买入卖出价税总金额.jpg',dpi=300)
plt.show()

暂时写这么多吧 ~ 希望以后遇到groupby等处理得心应手 ~















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









