









标签(空格分隔): hadoop
概述
首先hdfs是什么,是一个文件存储系统,框架设计上都有什么机制去保证数据的存储可靠性
角色机制介绍(什么角色,什么滴干活)
角色
datanode:存储具体数据(比如我们码农)
namenode:记录相关数据关联(类似管理层,管理但不具体参与细节)
secondary namenode:用于做namenode的镜像备份
block:数据存储单元(hdfs的存储形式)
相互关系
副本维护:datanode需要具体汇报namenode自身的block信息,因为可能存在数据丢失或者新加入节点的问题。所以namenode维持副本信息。
任务入口:如果需要存储数据,首先我们得告知namenode,之后人家会给你信息让你找对应的节点去存储。(要不然你自己也抓瞎找谁,管理层需要把控整体)
HDFS写与读流程及原理
写流程
(由于性能原因,在client和datanode传输前会有同机架优先,而副本则为了保障数据安全会挑选异步机架,后面会对如何配置机架数据进行说明,立个flag)
1.请求namenode存储,namenode返回是否可以
2.请求namenode相关副本信息,namenode返回对应数据
3.请求道datanode相关副本的节点信息,datanode会和副本建立通道,并返回给client。(ps:客户端可自定义每个block的大小,默认128M)
4.client将第一个Block传输给datanode,datanode和第二个副本datanode进行数据传输,第二个会跟第三个副本datanode传输。传输过程以package的形式传输,这样client端传完了数据之后,另外几个副本间的数据也差不多传输完成了,减少了client端与具体datanode副本间的传输时间。
5.接下来继续传输第二个副本,重复1-4的流程。
读流程
1.先以namenode为入口,获取meta信息,元数据包括相关所带的ip和存储block对应关系。(对接管理人员,管理人员分配任务数据给谁)
2.获取到数据之后,直接找对应的数据,从block1…n,挨个获取append上就是我们的要的数据了。
hdfs namenode工作机制原理
namenode和sc namenode的交互流程
概念介绍:
image:镜像文件,就是内存中的元信息的序列化
edit日志文件:是记录操作日志
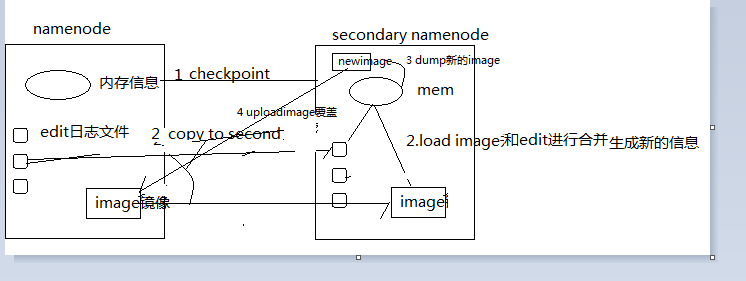
由于image的生成在数据量大的时候太过费时,所以image的生成逻辑放在sc namenode帮助执行。大体流程如下。
![image.png-20.8kB][1]
1.首先sc namenode发送请求,是否执行点,如果可以的话namenode会协助日志滚动 edit-pro…这个日志是当前最新的操作日志,为了让image生成尽可能多的数据,所以会将当前的这个数据也生成edit…number日志文件。
2.之后scnamenode会下载当前image和edit文件。
3.执行load将image和edit文件执行流程合并,生成新的image数据集。
4.将内存中的数据dump到文件中。
5.将新的image文件上传到namenode并覆盖。
namenode数据可靠性
首先呢:namenode关于为了防止磁盘损坏后的数据丢失,可以配置namenode的工作目录,配置在多块磁盘上。顺带一提namenode配置多块磁盘和datanode配置多块磁盘的效果是不一样的,namenode配置多块写多块相同数据,datanode是提高并发io的写入效率,所以写入数据是不一样的,有些数据写在a磁盘,有些数据写在b磁盘(由于本身带有备份数据所以不需要怕损坏)
[1]: http://static.zybuluo.com/luochengyue/57iduh2lehv5isa12nlorgmd/image.png

















 2438
2438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}