







文章目录
Hadoop原理
备注:以上资料来自黑马线下培训班,文章末尾有黑马2024版python+大数据线下面授班课程,配套课件资料齐全,可联系博主领取!
1、HDFS
hdfs默认文件配置:https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
1.1 块和副本
为什么需要将大文件分成不同的block分散到多台服务器上进行存储?因为有如下的优点
1- 避免单台服务器存储空间不够的情况
2- 能够同时利用多台服务器的性能,例如:磁盘读写速度等
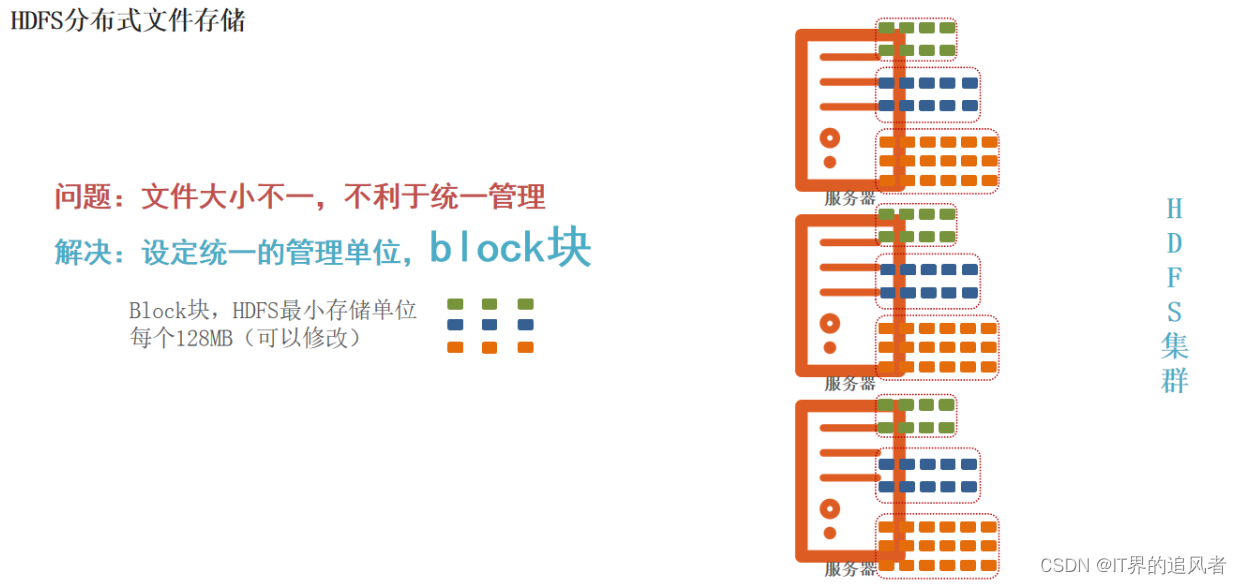
block块: HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件拆分成一系列的数据块进行存储,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。
block 块大小默认: 128M(134217728字节) 注意: 块同样大小方便统一管理
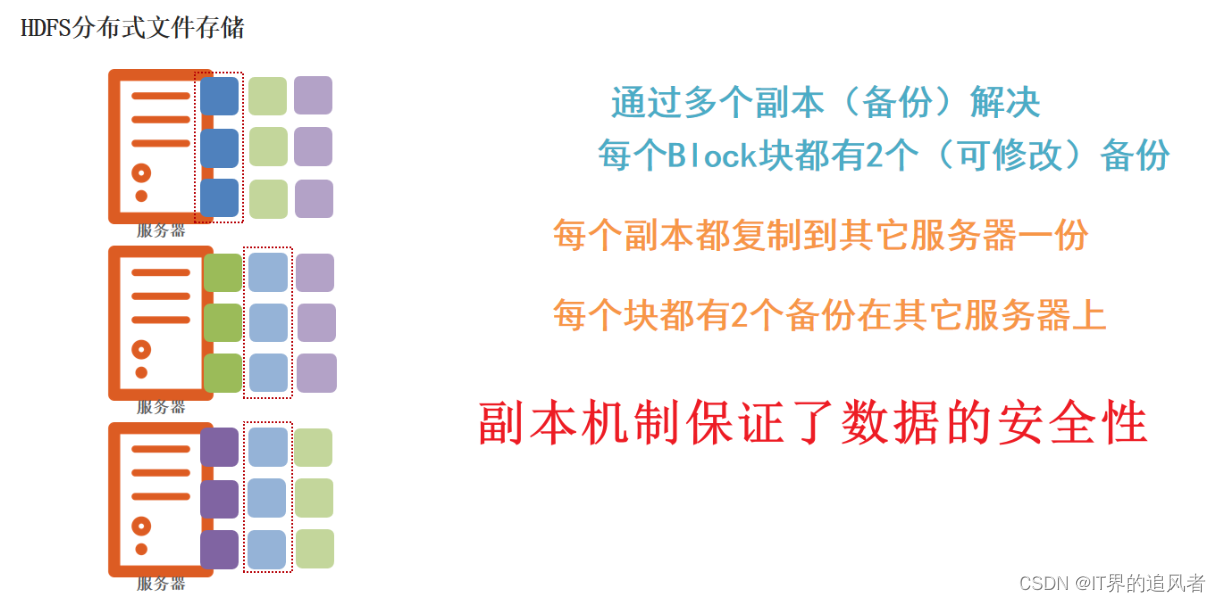
注意: 为了容错,文件的所有block都会有副本。每个文件的数据块大小和副本系数都是可配置的。
副本系数默认: 3个 副本好处: 副本为了保证数据安全(用消耗存储资源方式保证安全,导致了大数据瓶颈是数据存储)
hdfs默认文件配置:https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
如何修改块大小和副本数量呢?可以在hdfs-site.xml中配置如下属性:
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
<description>设置HDFS块大小,单位是b</description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
图解:
块 :默认统一大小128m : 为了方便统一管理
副本: 默认3个的原因: 为了保证数据的安全性
1.2 三大机制
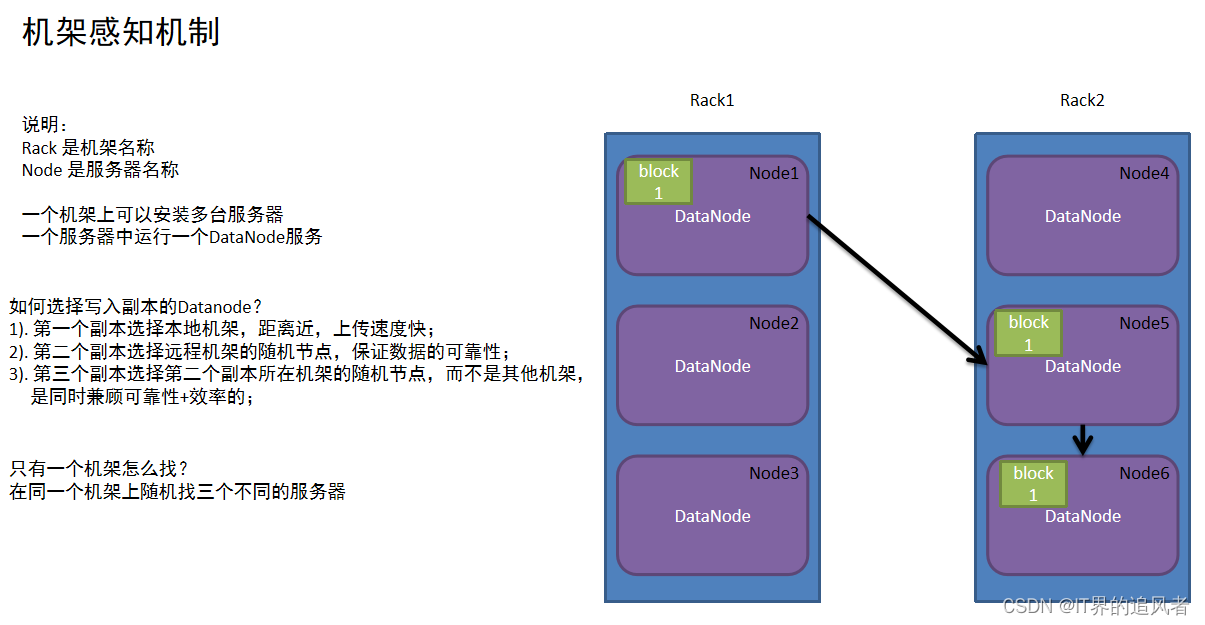
副本机制: 为了保证数据安全和效率,block块信息存储多个副本,第一副本保存在客户端所在服务器,第二副本保存在和第一副本不同机架服务器上,第三副本保存在和第二副本相同机架不同服务器
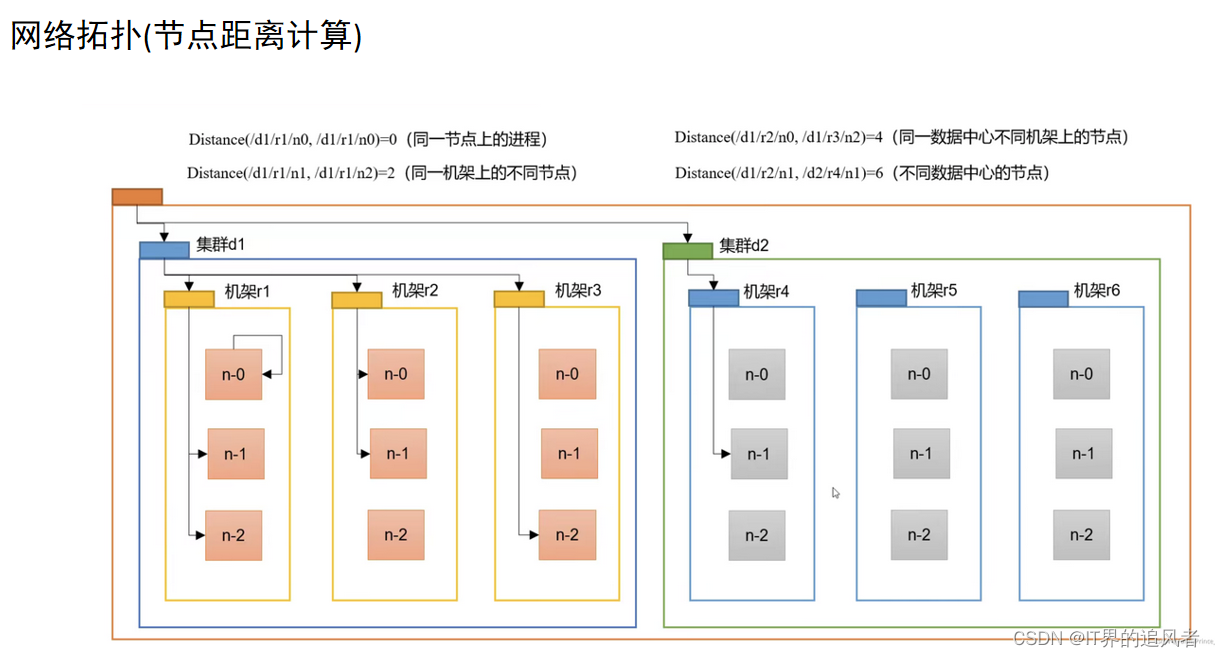
负载均衡机制: namenode为了保证不同的datanode中block块信息大体一样,分配存储任务的时候会优先保存在距离近且余量比较大的datanaode上
心跳机制: datanode每隔3秒钟向namenode汇报自己的状态信息,如果某个时刻,datanode连续10次不汇报了,namenode会认为datanode有可能宕机了,namenode就会每5分钟(300000毫秒)发送一次确认消息,连续2次没有收到回复,就认定datanode此时一定宕机了(确认datanode宕机总时间3*10+5*2*60=630秒)。观察地址http://node3:9864/datanode.html
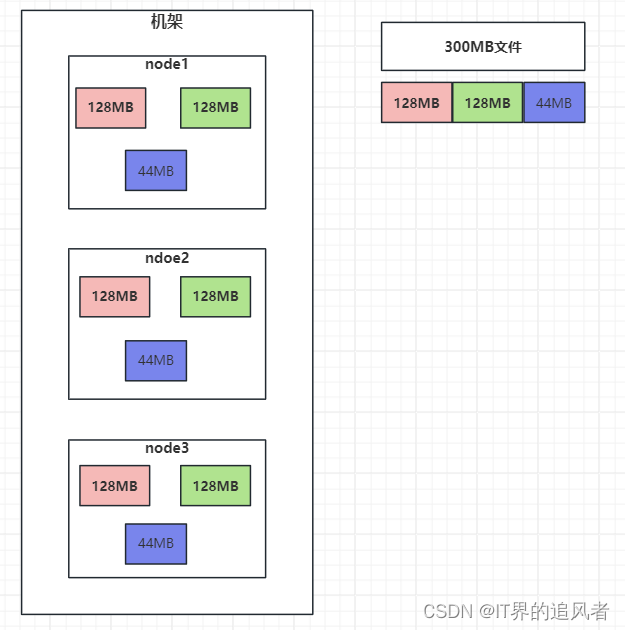
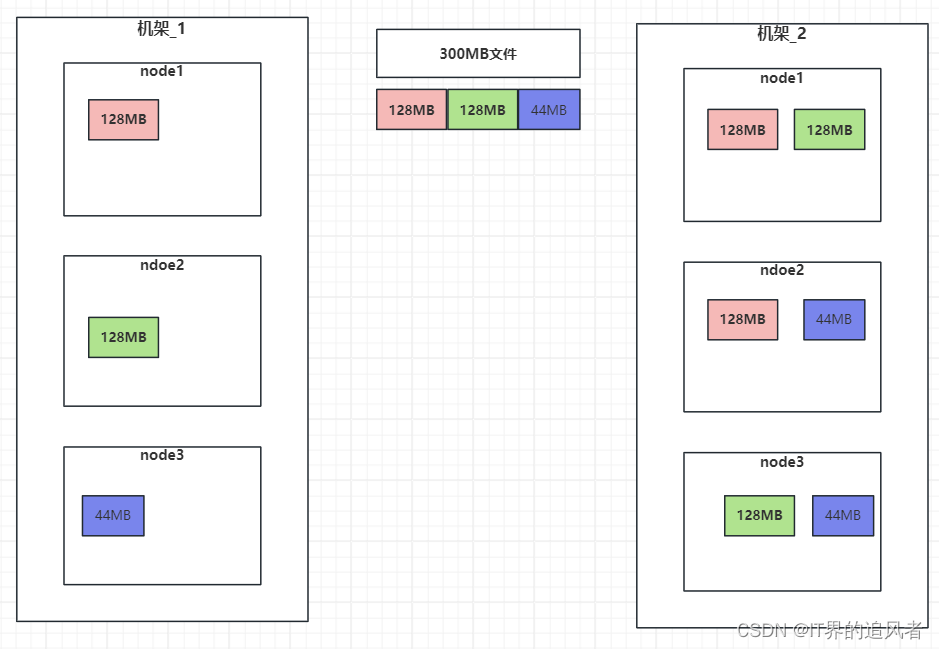
1.3 写入数据原理[面试]
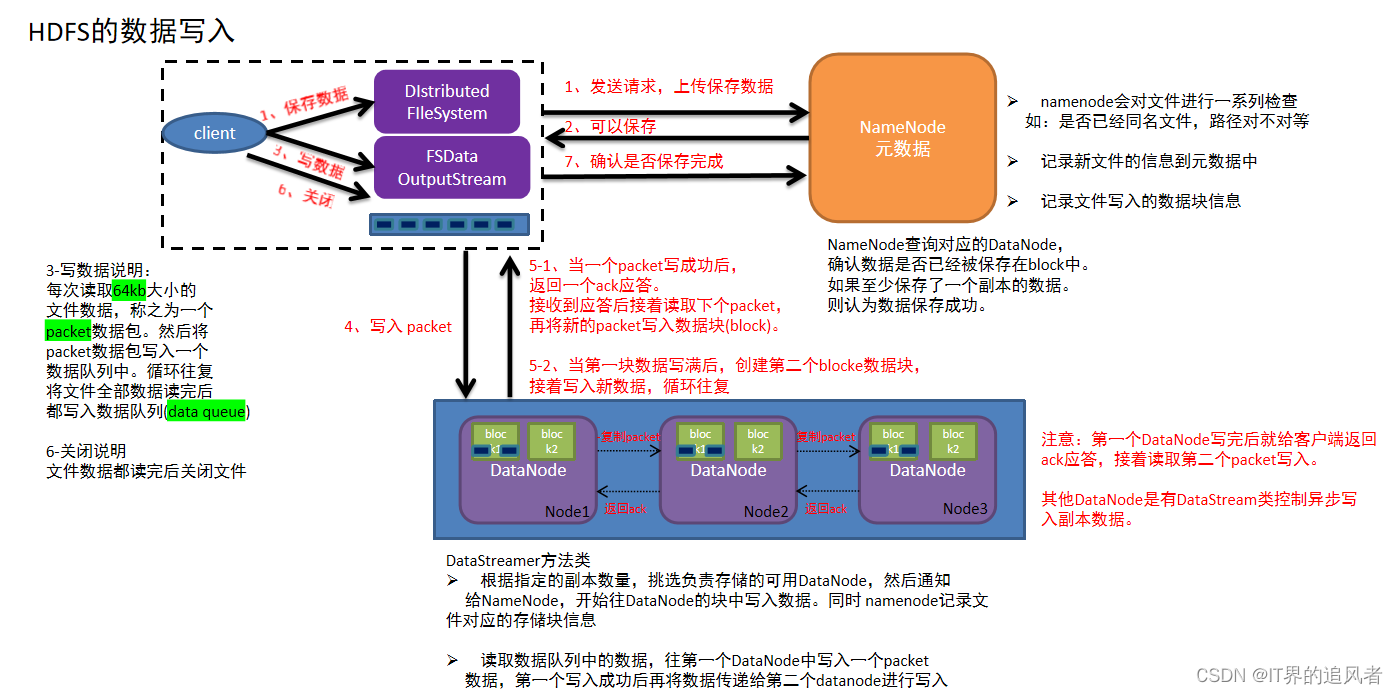
1.客户端发起写入数据的请求给namenode
2.namenode接收到客户端请求,开始校验(是否有权限,路径是否存在,文件是否存在等),如果校验没问题,就告知客户端可以写入
3.客户端收到消息,开始把文件数据分割成默认的128m大小的的block块,并且把block块数据拆分成64kb的packet数据包,放入传输序列
4.客户端携带block块信息再次向namenode发送请求,获取能够存储block块数据的datanode列表
5.namenode查看当前距离上传位置较近且不忙的datanode,放入列表中返回给客户端
6.客户端连接datanode,开始发送packet数据包,第一个datanode接收完后就给客户端ack应答(客户端就可以传入下一个packet数据包),同时第一个datanode开始复制刚才接收到的数据包给node2,node2接收到数据包也复制给node3(复制成功也需要返回ack应答),最终建立了pipeline传输通道以及ack应答通道
7.其他packet数据根据第一个packet数据包经过的传输通道和应答通道,循环传入packet,直到当前block块数据传输完成(存储了block信息的datanode需要把已经存储的块信息定期的同步给namenode)
8.其他block块数据存储,循环执行上述4-7步,直到所有block块传输完成,意味着文件数据被写入成功(namenode把该文件的元数据保存上)
9.最后客户端和namenode互相确认文件数据已经保存完成(也会汇报不能使用的datanode)
注意: 不要死记硬背,要结合自己的理解,转换为自己的话术,用于面试
1.4 读取数据原理[面试]
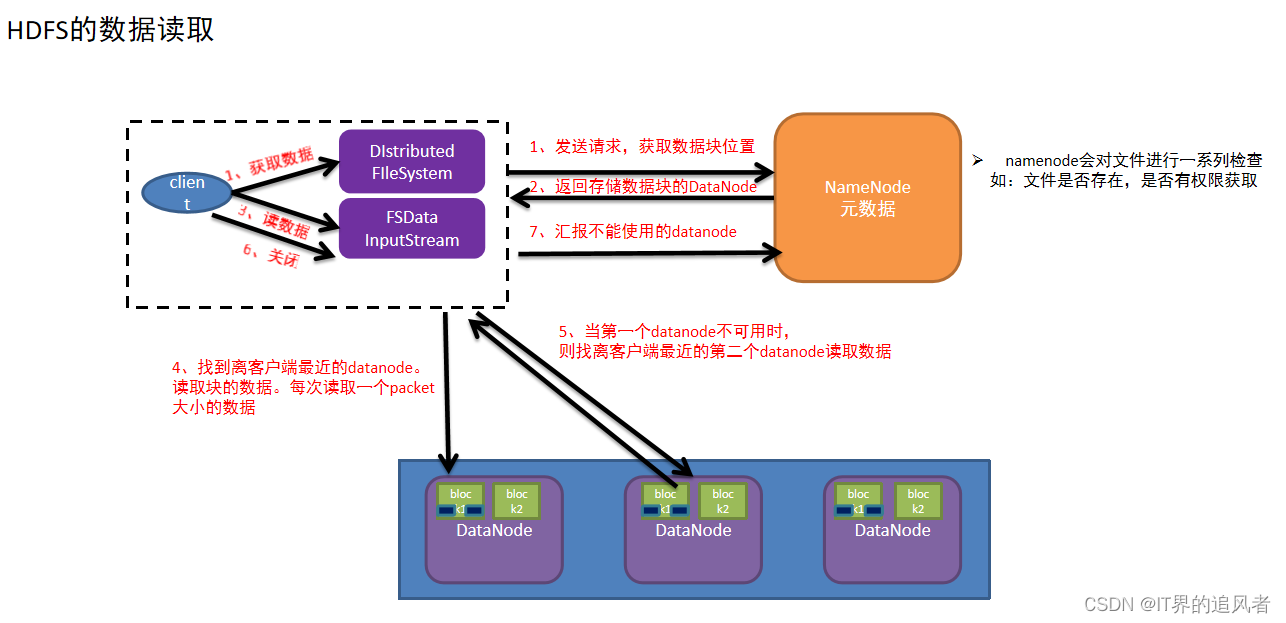
1.客户端发送读取文件请求给namenode
2.namdnode接收到请求,然后进行一系列校验(路径是否存在,文件是否存在,是否有权限等),如果没有问题,就告知可以读取
3.客户端需要再次和namenode确认当前文件在哪些datanode中存储
4.namenode查看当前距离下载位置较近且不忙的datanode,放入列表中返回给客户端
5.客户端找到最近的datanode开始读取文件对应的block块信息(每次传输是以64kb的packet数据包),放到内存缓冲区中
6.接着读取其他block块信息,循环上述3-5步,直到所有block块读取完毕(根据块编号拼接成完整数据)
7.最后从内存缓冲区把数据通过流写入到目标文件中
8.最后客户端和namenode互相确认文件数据已经读取完成(也会汇报不能使用的datanode)
注意: 不要死记硬背,要结合自己的理解,转换为自己的话术,用于面试
1.5 edits和fsimage文件
namenode管理元数据: 基于edits和fsimage的配合,完成整个文件系统文件的管理。每次对HDFS的操作,均被edits文件记录, edits达到大小上限后,开启新的edits记录,定期进行edits的合并操作
如当前没有fsimage文件, 将全部edits合并为第一个fsimage文件
如当前已存在fsimage文件,将全部edits和已存在的fsimage进行合并,形成新的fsimage
edits编辑文件: 记录hdfs每次操作(namenode接收处理的每次客户端请求)
fsimage镜像文件: 记录某一个时间节点前的当前文件系统全部文件的状态和信息(namenode所管理的文件系统的一个镜像)
SecondaryNameNode辅助合并元数据: SecondaryNameNode会定期从NameNode拉取数据(edits和fsimage)然后合并完成后提供给NameNode使用。
对于元数据的合并,是一个定时过程,基于两个条件,下面的两个条件只需要满足其中一个都会触发:
dfs.namenode.checkpoint.period:默认3600(秒)即1小时
dfs.namenode.checkpoint.txns: 默认1000000,即100W次事务
dfs.namenode.checkpoint.check.period: 检查是否达到上述两个条件,默认60秒检查一次,只要有一个达到条件就执行拉取合并
1.6 内存/文件元数据
namenode和secondarynamenode: 配合完成对元数据的保存
元数据: 内存元数据 和 文件元数据 两种分别在内存和磁盘上
内存元数据: namnode运行过程中产生的元数据会先保存在内存中,再保存到文件元数据中。
内存元数据优缺点: 优点: 因为内存处理数据的速度要比磁盘快。 缺点: 内存一断电,数据全部丢失
文件元数据: Edits 编辑日志文件和fsimage 镜像文件
Edits编辑日志文件: 存放的是Hadoop文件系统的所有更改操作(文件创建,删除或修改)的日志,文件系统客户端执行的更改操作首先会被记录到edits文件中
Fsimage镜像文件: 是元数据的一个持久化的检查点,包含Hadoop文件系统中的所有目录和文件元数据信息,但不包含文件块位置的信息。文件块位置信息只存储在内存中,是在 datanode加入集群的时候,namenode询问datanode得到的,并且不间断的更新
fsimage和edits关系: 两个文件都是经过序列化的,只有在NameNode启动的时候才会将fsimage文件中的内容加载到内存中,之后NameNode把增删改查等操作记录同步到edits文件中.使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作,也是最完整的元数据。
1.6.1 图解
edits和fsimage文件所在的位置:namenode运行所在机器的/export/data/hadoop/dfs/name/current
secondaryNameNode对应的目录:/export/data/hadoop/dfs/namesecondary/current
注意:千万不要随便去修改/删除这些文件
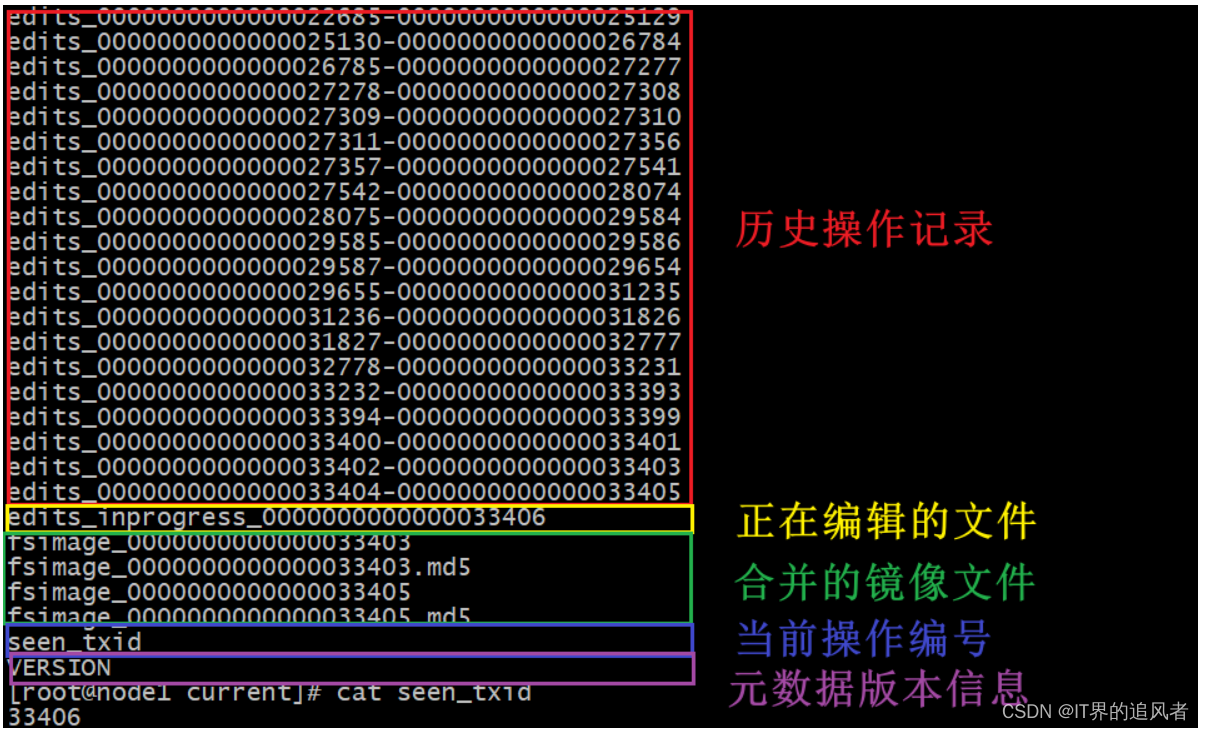
1.6.2 查看历史编辑文件
命令: hdfs oev -i edits文件名 -o 自定义文件名.xml
[root@node1 current]# cd /export/data/hadoop/dfs/name/current
[root@node1 current]# hdfs oev -i edits_0000000000000039578-0000000000000039647 -o /home/39647.xml
[root@node1 current]# cat /home/39647.xml
1.6.3 查看镜像文件
命令: hdfs oiv -i fsimage文件名 -p XML -o 自定义文件名.xml
[root@node1 current]# cd /export/data/hadoop/dfs/name/current
[root@node1 current]# hdfs oiv -i fsimage_0000000000000033405 -p XML -o /home/405_fsimage.xml
[root@node1 current]# cat /home/405_fsimage.xml
1.7 元数据存储的原理[高频面试点]
注意: 第一次启动namenode的时候是没有编辑日志文件和镜像文件的,下图主要介绍的是第二次及以后访问的时候情况流程
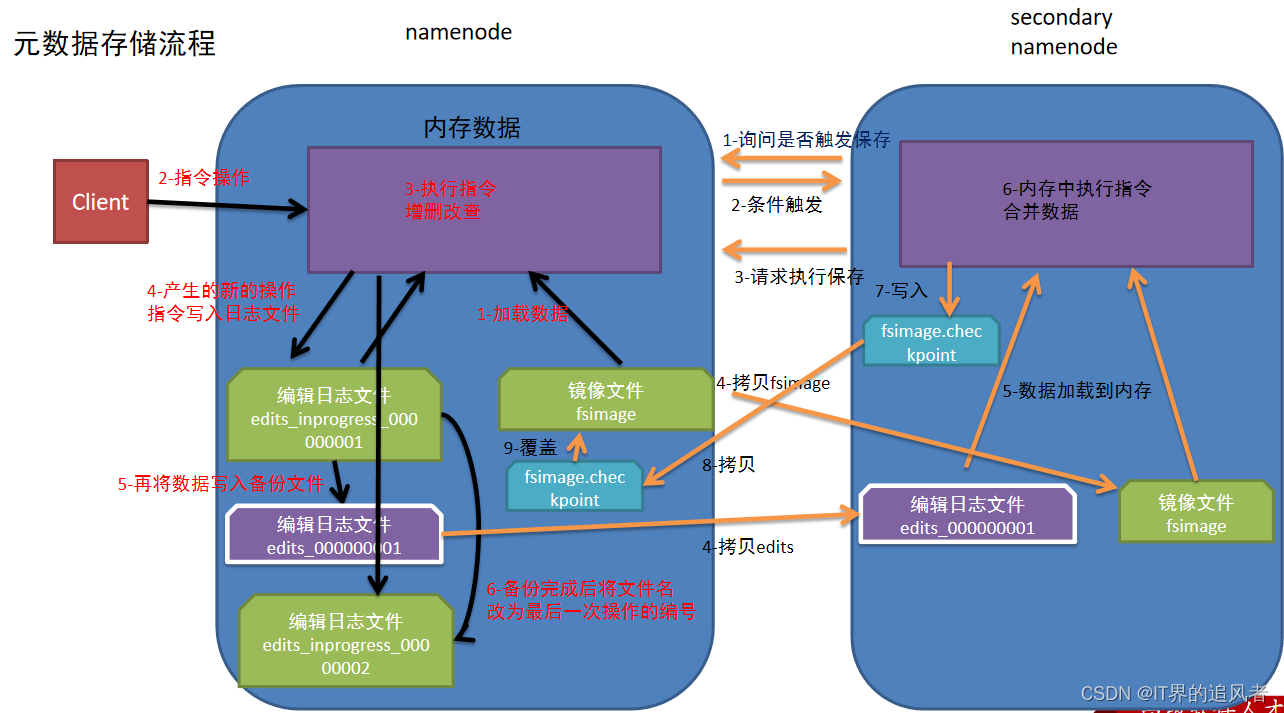
1.namenode第一次启动的时候先把最新的fsimage文件中内容加载到内存中,同时把edits文件中内容也加载到内存中
2.客户端发起指令(增删改查等操作),namenode接收到客户端指令把每次产生的新的指令操作先放到内存中
3.然后把刚才内存中新的指令操作写入到edits_inprogress文件中
4.edits_inprogress文件中数据到了一定阈值的时候,把文件中历史操作记录写入到序列化的edits备份文件中
5.namenode就在上述2-4步中循环操作...
6.当secondarynamenode检测到自己距离上一次检查点(checkpoint)已经1小时或者事务数达到100w,就触发secondarynamenode询问namenode是否对edits文件和fsimage文件进行合并操作
7.namenode告知可以进行合并
8.secondarynamenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行合并(这个过程称checkpoint)
9.secondarynamenode把刚才合并后的fsimage.checkpoint文件拷贝给namenode
10.namenode把拷贝过来的最新的fsimage.checkpoint文件,重命名为fsimage,覆盖原来的文件
注意: 不要死记硬背,要结合自己的理解,转换为自己的话术,用于面试
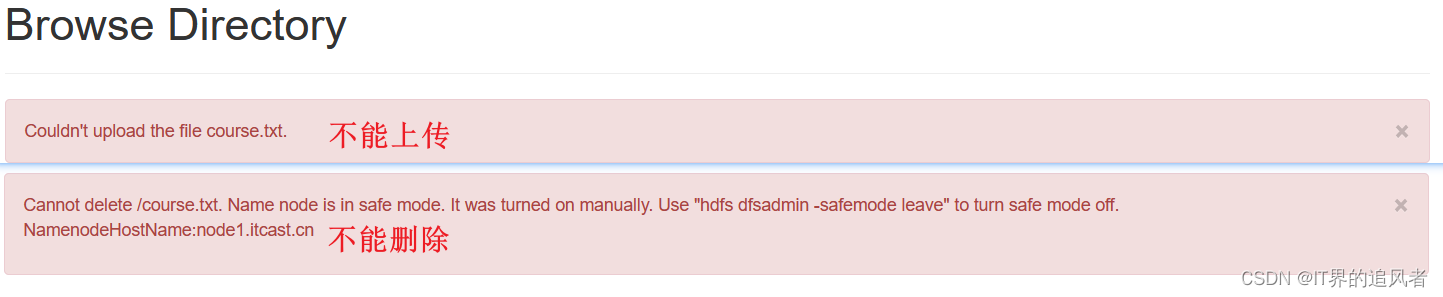
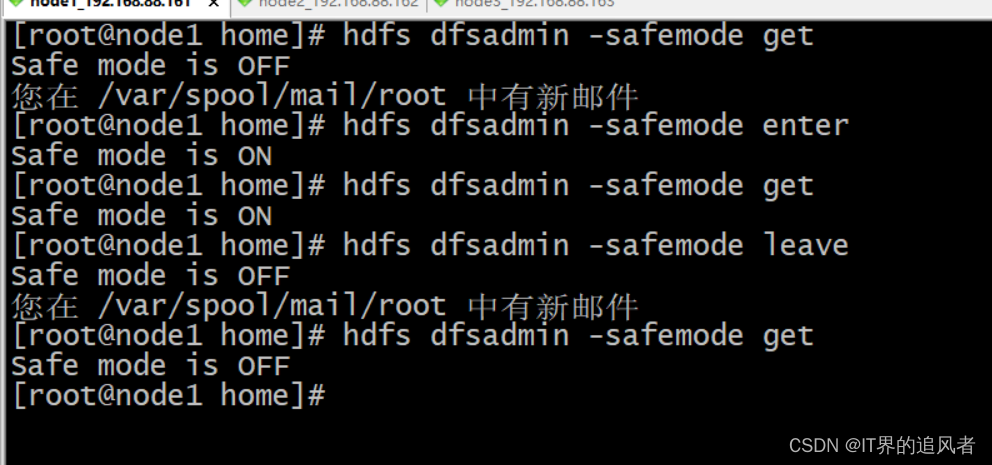
1.8 安全模式
安全模式: 是namenode的自我保护。不允许HDFS客户端进行任何修改文件的操作,包括上传文件,删除文件等操作。
…
1.9 归档机制
归档原因: 每个小文件单独存放到hdfs中(占用一个block块),那么hdfs就需要依次存储每个小文件的元数据信息,相对来说浪费资源。和压缩文件一样,也就是将多个小文件压缩到一起。小文件了个数过多,会导致map程序过多,这样会占用过多的Yarn集群资源
归档格式: hadoop archive -archiveName 归档名.har -p 原始文件的目录 归档文件的存储目录
准备工作: HDFS上准备一个目录binzi,里面存储三个文件 1.txt 2.txt 3.txt …
[root@node1 /]# hadoop archive -archiveName dir.har -p /dir /
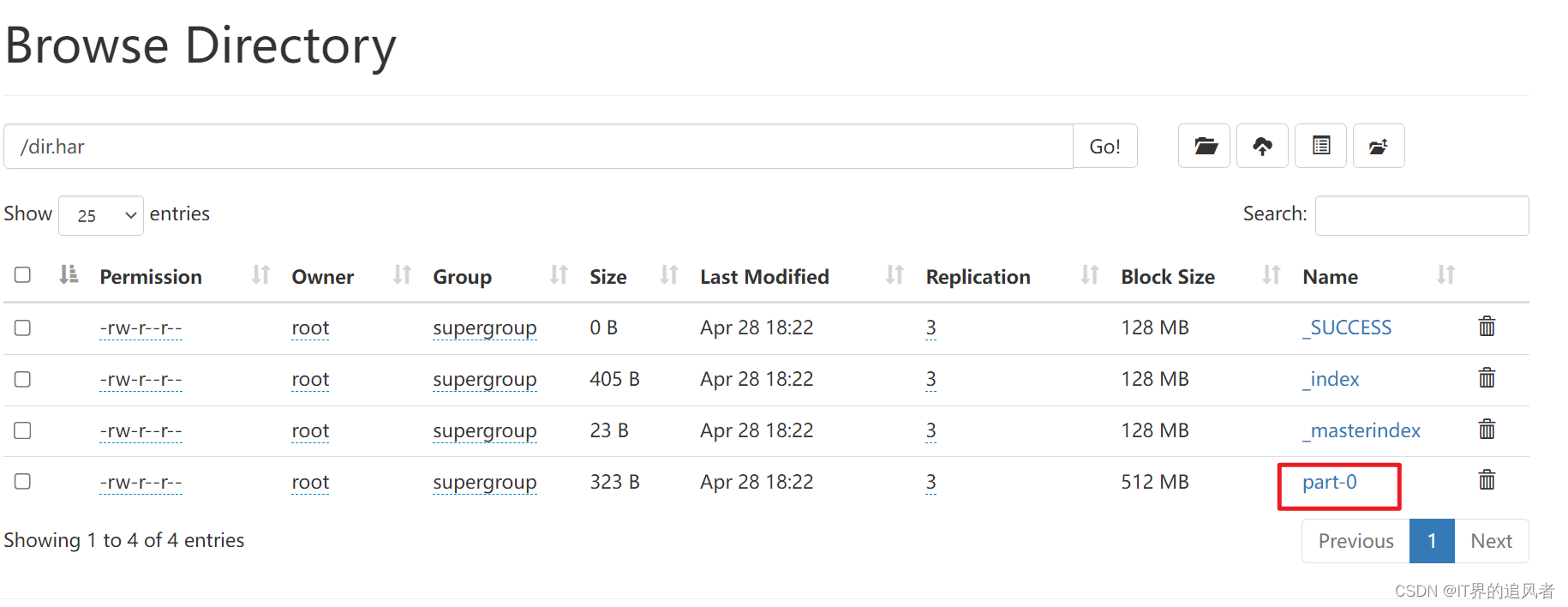
归档特性:
Hadoop Archives的URI是:har://scheme-hostname:port/路径/归档名.har
scheme-hostname格式为hdfs-域名:端口
如果没有提供scheme-hostname,它会使用默认的文件系统: har:///路径/归档名.har
[root@node1 home]# hdfs dfs -cat /dir.har/part-0
512 霸王防脱 20 200
513 蓝月亮洗衣液 10 15
514 心心相印抽纸 18 10
515 雕牌洗洁精 8 104151 耳机 40 1
4152 霸王防脱 28 1
4153 衣架 12 1
511 飘柔洗发水 15 2
512 霸王防脱 20 1
513 蓝月亮洗衣液 10 1
514 心心相印抽纸 18 1521 牙刷套装 15 2
522 小米手机壳 20 1
[root@node1 home]# hdfs dfs -cat har:///dir.har/part-0
cat: `har:///dir.har/part-0': No such file or directory
[root@node1 home]# hdfs dfs -cat har:///dir.har/*
512 霸王防脱 20 200
513 蓝月亮洗衣液 10 15
514 心心相印抽纸 18 10
515 雕牌洗洁精 8 104151 耳机 40 1
4152 霸王防脱 28 1
4153 衣架 12 1
511 飘柔洗发水 15 2
512 霸王防脱 20 1
513 蓝月亮洗衣液 10 1
514 心心相印抽纸 18 1521 牙刷套装 15 2
522 小米手机壳 20 1
您在 /var/spool/mail/root 中有新邮件
[root@node1 home]#
1.10 垃圾桶机制
在虚拟机中rm命令删除文件,默认是永久删除
在虚拟机中需要手动设置才能使用垃圾桶回收: 把删除的内容放到: /user/root/.Trash/Current/
先关闭服务: 在 node1 中执行 stop-all.sh 新版本不关闭服务也没有问题
再修改文件 core-site.xml : 进入/export/server/hadoop-3.3.0/etc/hadoop目录下进行修改<property> <name>fs.trash.interval</name> <value>1440</value> </property>其中,1440 表示 1440分钟,也就是 24小时,一天的时间。
设置了垃圾桶机制好处: 文件不会立刻消失,可以去垃圾桶里把文件恢复,继续使用
# 没有开启垃圾桶效果
[root@node1 hadoop]# hdfs dfs -rm /binzi/hello.txt
Deleted /binzi/hello.txt
# 开启垃圾桶
[root@node1 ~]#cd /export/server/hadoop-3.3.0/etc/hadoop
[root@node1 hadoop]# vim core-site.xml
# 注意: 放到<configuration>内容</configuration>中间
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
# 开启垃圾桶效果
[root@node1 hadoop]# hdfs dfs -rm -r /test1.har
2023-05-24 15:07:33,470 INFO fs.TrashPolicyDefault: Moved: 'hdfs://node1.itcast.cn:8020/test1.har' to trash at: hdfs://node1.itcast.cn:8020/user/root/.Trash/Current/test1.har
# 开启垃圾桶后并没有真正删除,还可以恢复
[root@node1 hadoop]# hdfs dfs -mv /user/root/.Trash/Current/test1.har /
2、MapReduce
2.1 单词统计流程
已知文件内容:
hadoop hive hadoop spark hive
flink hive linux hive mysql
input结果:
k1(行偏移量) v1(每行文本内容)
0 hadoop hive hadoop spark hive
30 flink hive linux hive mysql
map结果:
k2(split切割后的单词) v2(拼接1)
hadoop 1
hive 1
hadoop 1
spark 1
hive 1
flink 1
hive 1
linu 1
hive 1
mysql 1
分区/排序/规约/分组结果:
k2(排序分组后的单词) v2(每个单词数量的集合)
flink [1]
hadoop [1,1]
hive [1,1,1,1]
linux [1]
mysql [1]
spark [1]
reduce结果:
k3(排序分组后的单词) v3(聚合后的单词数量)
flink 1
hadoop 2
hive 4
linux 1
mysql 1
spark 1
output结果: 注意: 输出目录一定不要存在,否则报错
flink 1
hadoop 2
hive 4
linux 1
mysql 1
spark 1
2.2 MR底层原理[高频面试点]
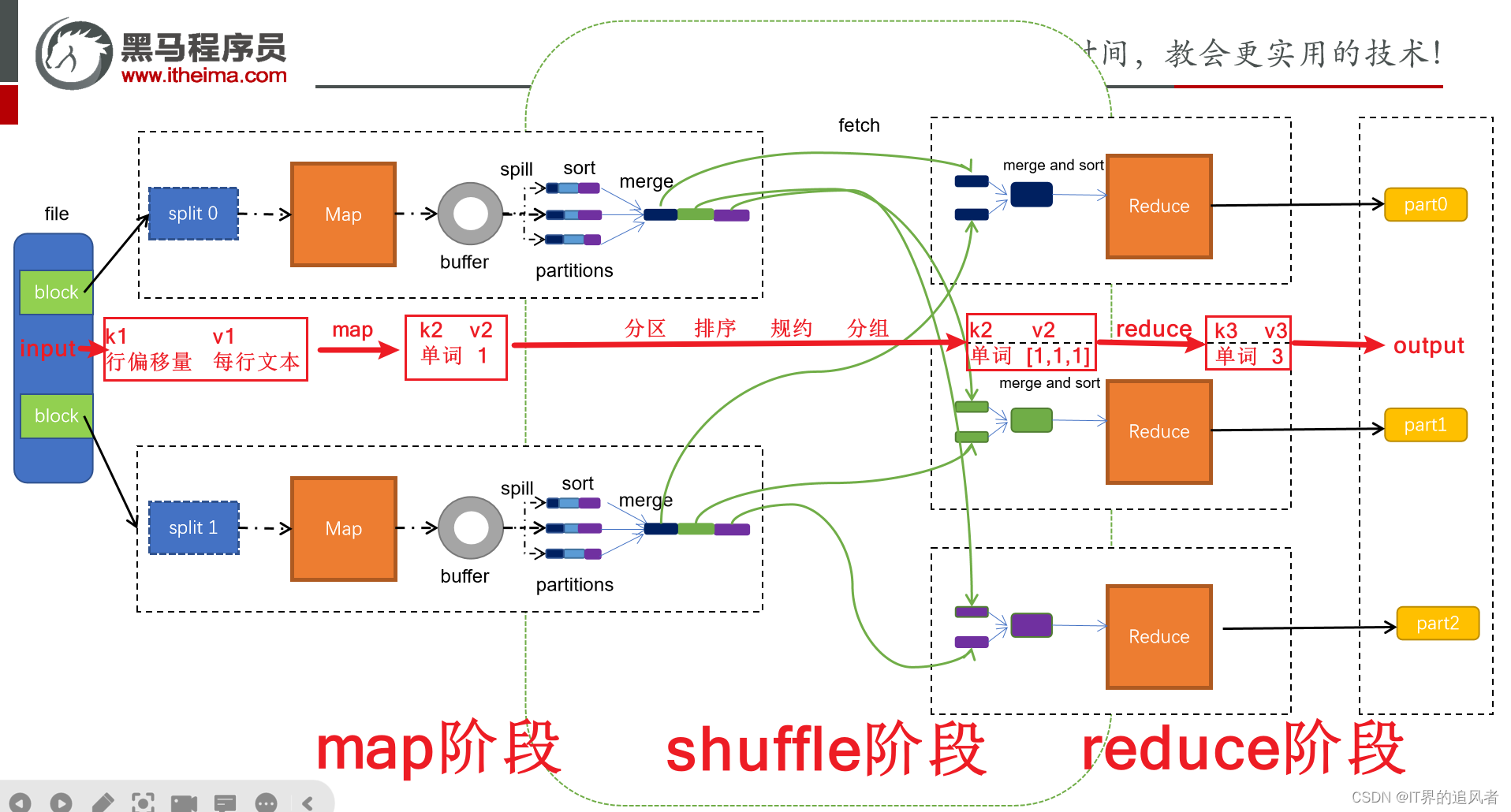
2.2.1 map阶段
第一阶段是把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下Split size 等于 Block size。每一个切片由一个MapTask处理(当然也可以通过参数单独修改split大小)
第二阶段是对切片中的数据按照一定的规则解析成对。默认规则是把每一行文本内容解析成键值对。key是每一行的起始位置(单位是字节),value是本行的文本内容。(TextInputFormat)
第三阶段是调用Mapper类中的map方法。上阶段中每解析出来的一个,调用一次map方法。每次调用map方法会输出零个或多个键值对
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。
如果有第六阶段,那么进入第六阶段;如果没有,直接输出到文件中
第六阶段是对数据进行局部聚合处理,也就是combiner处理。键相等的键值对会调用一次reduce方法。经过这一阶段,数据量会减少。本阶段默认是没有的。
注意: 不要死记硬背,要结合自己的理解,转换为自己的话术,用于面试
2.2.2 shuffle阶段
shuffle是Mapreduce的核心,它分布在Mapreduce的map阶段和reduce阶段。一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。
Collect阶段:将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value,Partition分区信息等
Spill阶段:当内存中的数据量达到一定的阀值(80%)的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序
Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件
Copy阶段: ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上
Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可。
注意: 不要死记硬背,要结合自己的理解,转换为自己的话术,用于面试
2.2.3 reduce阶段
第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中。
注意: 不要死记硬背,要结合自己的理解,转换为自己的话术,用于面试
行合并操作。
Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可。
注意: 不要死记硬背,要结合自己的理解,转换为自己的话术,用于面试
#### 2.2.3 reduce阶段
```properties
第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中。
注意: 不要死记硬背,要结合自己的理解,转换为自己的话术,用于面试
备注:
黑马2024版python+大数据线下面授班课程,配套课件齐全。需要联系我拿详细资料。
✔2024最新资料
✔目前本人正在学习中,资料实时更新
✔如果需要其他资料,可联系代拿
✔目前离线数仓项目已更新为生鲜项目,具备强大竞争力(全国第二个教这个项目的班级)
✔可直接联系本人交流QQ:943131870















 1041
1041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











