







 本文介绍了深度学习基础知识,重点讲解了卷积神经网络(CNN)的基本结构和优势。从感知机和多层感知机出发,详细阐述了卷积层、池化层、填充和步长的概念,探讨了卷积学习的原理和CNN在图像特征提取方面的优势。
本文介绍了深度学习基础知识,重点讲解了卷积神经网络(CNN)的基本结构和优势。从感知机和多层感知机出发,详细阐述了卷积层、池化层、填充和步长的概念,探讨了卷积学习的原理和CNN在图像特征提取方面的优势。

1. 感知机
感知机通常情况下指单层的人工神经网络,其结构与 MP 模型类似(按照生物神经元的结构和工作原理造出来的一个抽象和简化了模型,也称为神经网络的一个处理单元)
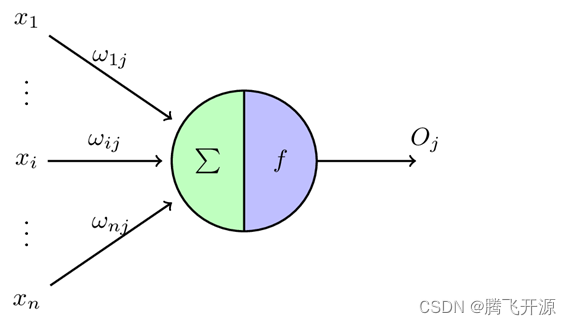
假设由一个 n 维的单层感知机,则:
- x 1 x_1 x1 至 x n x_n xn 为 n 维输入向量的各个分量
- w 1 j w_{1j} w1j 至 w n j w_{nj} wnj 为各个输入分类连接感知机的权重(权值), ∑ \sum ∑ 为阈值
- f 为激活函数(激励函数或传递函数),O 为标量输出
- 理想的函数为阶跃函数或 Sigmoid 函数,目标是通过输入向量 x 与权重向量 w 求得内积后,通过激活函数 f 所得的标量
2. 多层感知机与反向传播
在多层感知机中使用 BP 算法(由信号的正向传播和误差的反向传播两个过程组成,由于多层前馈网络的训练,经常采用误差反向传播算法),采用 Sigmoid (生物学中的常见的 S 型函数,也成为 S 型生长曲线)进行非线性映射,解决了非线性分类和学习的问题
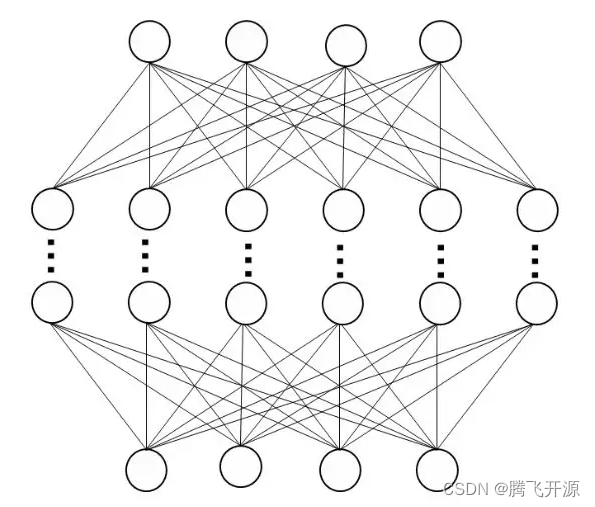
多层感知机是单层感知机的推广,最主要的特点是有多个神经元层。
- 将 MLP 的第一层称为输入层,中间成为隐藏层(隐含层),最后一层为输出层,对于隐藏层和输出层中每层神经元的个数也没有限制
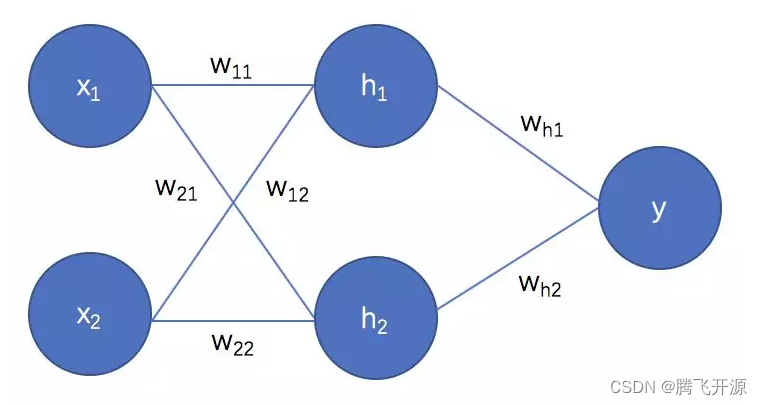
- 输出为 y,损失函数为 E
y = h 1 w h 1 + h 2 w h 2 = x 1 w 11 + x 2 w 12 + x 1 w 21 + x 2 w 22 y=h_1w_{h1}+h_2w_{h2}=x_1w_{11}+x_2w_{12}+x_1w_{21}+x_2w_{22} y=h1wh1+h2wh2=x1w11+x2w12+x1w21+x2w22
E = 1 2 ( y − t ) 2 E=\frac{1}{2}(y-t)^{2} E=21(y−t)2
- 假如某一时刻值如下:
x 1 = 1 , x 2 = − 1 , w 11 = 0.1 , w 21 = − 0.1 , w 12 = − 0.1 , w 22 = 0.1 , w h 1 = 0.8 , w h 2 = 0.9 , t = 0 x_1=1,x_2=-1,w_{11}=0.1,w_{21}=-0.1,w_{12}=-0.1,w_{22}=0.1,w_{h1}=0.8,w_{h2}=0.9,t=0 x1=1,x2=−1,w11=0.1,w21=−0.1,w12=−0.1,w22=0.1,wh1=0.8,wh2=0.9,t=0
h 1 = w 11 x 1 + w 12 x 2 = 0.2 h_1=w_{11}x_1+w_{12}x_2=0.2 h1=w11x1+w12x2=0.2
h 2 = w 21 x 1 + w 22 x 2 = − 0.2 h_2=w_{21}x_1+w_{22}x_2=-0.2 h2=w21x1+w22x2=−0.2
y = h 1 w h 1 + h 2 w h 2 = − 0.02 y=h_1w_{h1}+h_2w_{h2}=-0.02 y=h1wh1+h2wh2=−0.02
- 那么我们可以计算 E 对 W h 1 W_{h1} Wh1 的误差传播值为:
∂ E ∂ w h 1 = ∂ E ∂ y ∂ y ∂ w h 1 = ( y − t ) h 1 = − 0.004 \frac{\partial E}{\partial w_{h1}}=\frac{\partial E}{\partial_y}\frac{\partial_y}{\partial w_{h1}}=(y-t)h_1=-0.004 ∂wh1∂E=∂y∂E∂wh1∂y=(y−t)h1=−0.004
- 下次更新 W H 1 W_{H1} WH1 这个参数的时候就可以采用:
w h 1 = w h 1 − η ∂ E ∂ w h 1 w_{h1}=w_{h1}- \eta \frac{\partial E}{\partial w_{h1}} wh1=wh1−η∂wh1∂E
- η \eta η 就是学习率了,原理就是这样来的
3. 卷积神经网络的基本网络层
卷积神经网络简称 CNN,主要包括卷积层、池化层、全连接层
- 卷积层:用于对图像进行特征提取操作,其卷积核权重是共享权值的,对应的相关概念还包括步长,填充。
- 池化层:用于降低特征图大小,降低后续操作的计算量和参数量
- 全连接层:最终进行分类输出使用,本质就是多层感知机
3.1 什么是卷积
在信号处理领域中,任意一个线性系统的输出,就是输入信号和系统激励函数的卷积。放到数字图像处理领域,卷积操作一般指图像领域的二维卷积。
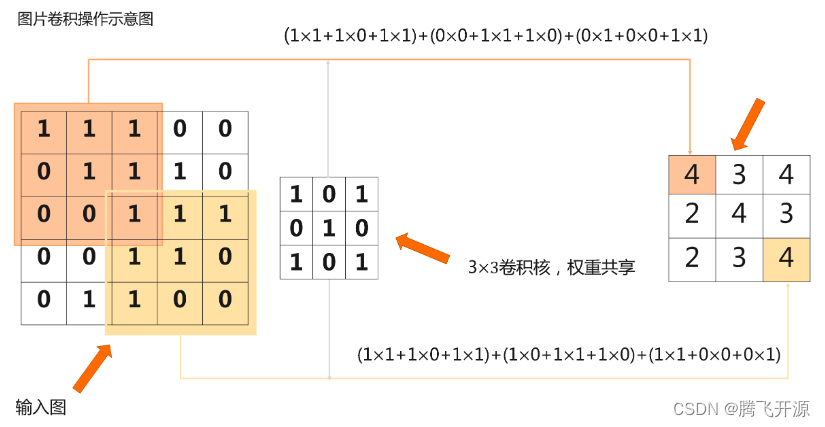
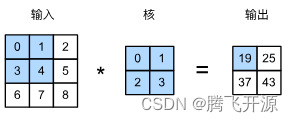
一个二维卷积的案例如上,在图像上滑动,取与卷积核大小相等的区域,逐像素做乘法然后相加。
卷积就是:一个核矩阵在一个原始矩阵上从上往下、从左往右扫描,每次扫描都得到一个结果,将所有结果组合到一起得到一个新的结果矩阵
例如:
import torch
from torch import nn
def corr2d(X, K): # X 是输入,K是卷积核
h, w = K.shape # 获取卷积核的大小
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i: i + h, j: j + w] * K).sum() # 累加
return Y
X = torch.tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]]) # 模拟一个输入
K = torch.tensor([[0, 1], [2, 3]]) # 模拟一个卷积核
corr2d(X, K)
tensor([[19., 25.],
[37., 43.]])
下图就是上面程序的模拟图
3.2 填充
填充的目的:
- 使卷积后图像分辨率不变,方便计算特征值图尺寸的变化
- 弥补边界信息“丢失”
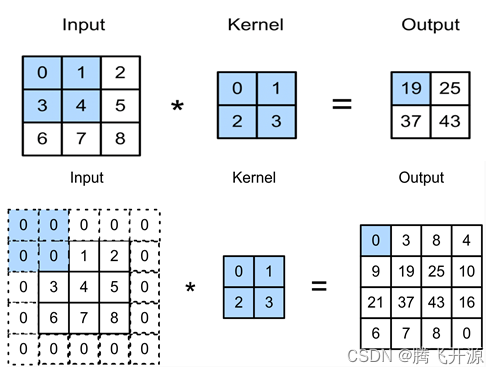
填充(padding)是指在输入高和宽的两侧填充元素(通常是0元素)。下图我们在原输入高和宽的两侧分别添加了值为0的元素,使得输入高和宽从3变成了5,并导致输出高和宽由2增加到4。下面阴影部分为第一个输出元素及其计算所使用的输入和核数组元素:0x0+1x1+3x2+4x3=19。
3.3 步长
卷积窗口从输入数组的最左上方开始,按从左往右、从上往下的顺序,依次在输入数组上滑动。我们将每次滑动的行数和列数称为步幅或步长(stride)
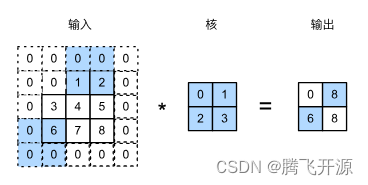
下图展示了在高上步幅为3、在宽上步幅为2的卷积运算。可以看到,输出第一列第二个元素时,卷积窗口向下滑动了3行,而在输出第一行第二个元素时卷积窗口向右滑动了2列。当卷积窗口在输入上再向右滑动2列时,由于输入元素无法填满窗口,无结果输出。下图阴影部分为输出元素及其计算所使用的输入和核数组元素:0×0+0×1+1×2+2×3=8、0×0+6×1+0×2+0×3=6。
3.4 池化
对图像进行下采样,降低图像分辨率。
池化层的作用:使特征图变小,简化网络计算复杂度;压缩特征,提取主要特征
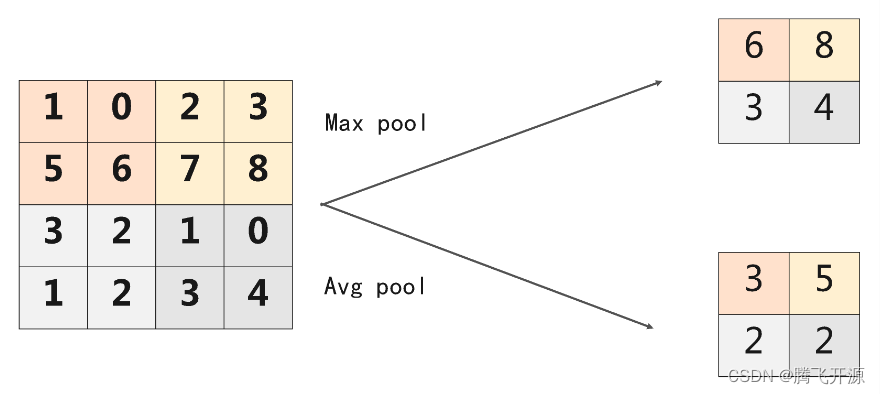
常见的池化操作可以分为:最大池化(Max Pool)、平均池化(Avg Pool),示意图如下:
3.5 卷积和池化输出尺寸计算
假设输入图片的高和宽一致,卷积核的宽和高一致,那么输入图像的尺寸与输出图像的尺寸有如下关系:
其中, F i n F_{in} Fin 是输入图像、k 是卷积核的大小、p 是图像填充的大小、s 是卷积核的步幅、 F o F_o Fo 是输出、 ⌊ 6.6 ⌋ \lfloor 6.6 \rfloor ⌊6.6⌋ 是向下取整的意思,比如结果是 6.6,那么向下取整就是 6
F o = ⌊ F i n − k + 2 p s ⌋ + 1 F_o=\lfloor \frac{F_{in}-k+2p}{s} \rfloor + 1 Fo=⌊sFin−k+2p⌋+1
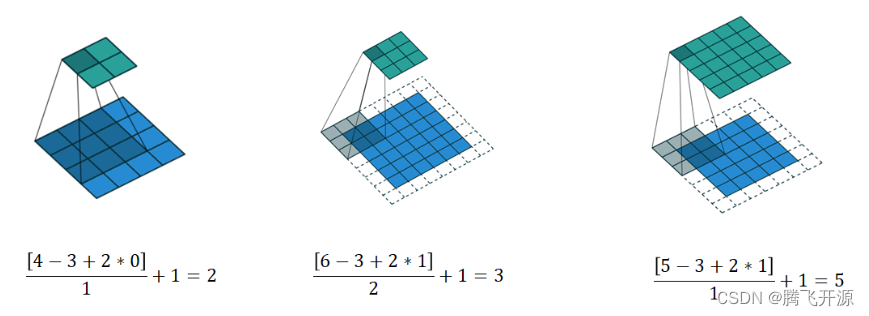
3.6 为什么要用卷积来学习呢?
图像都是用方形矩阵来表达的,学习的本质就是要抽象出特征,以边缘检测为例。它就是识别数字图像中亮度变化明显的点,这些点连接起来往往是物体的边缘。
传统的边缘检测常用的方法包括一阶和二阶导数法,本质上都是利用一个卷积核在原图上进行滑动,只是其中各个位置的系数不同,比如3×3的sobel算子计算x方向的梯度幅度,使用的就是下面的卷积核算子。
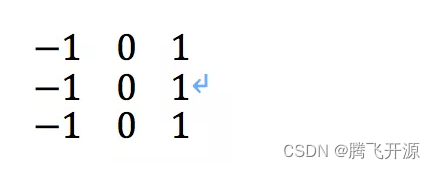
如果要用sobel算子完成一次完整的边缘检测,就要同时检测x方向和y方向,然后进行融合。这就是两个通道的卷积,先用两个卷积核进行通道内的信息提取,再进行通道间的信息融合。 这就是卷积提取特征的本质,而所有基于卷积神经网络来学习的图像算法,都是通过不断的卷积来进行特征的抽象,直到实现网络的目标。
3.7 卷积神经网络的优势在哪?
3.7.1 学习原理上的改进
卷积神经网络不再是有监督学习了,不需要从图像中提取特征,而是直接从原始图像数据进行学习,这样可以最大程度的防止信息在还没有进入网络之前就丢失。
3.7.2 学习方式的改进
前面说了全连接神经网络一层的结果是与上一层的节点全部连接的,100×100的图像,如果隐藏层也是同样大小(100×100个)的神经元,光是一层网络,就已经有 10^8 个参数。要优化和存储这样的参数量,是无法想象的,所以经典的神经网络,基本上隐藏层在一两层左右。而卷积神经网络某一层的结点,只与上一层的一个图像块相连。
用于产生同一个图像中各个空间位置像素的卷积核是同一个,这就是所谓的权值共享。对于与全连接层同样多的隐藏层,假如每个神经元只和输入10×10的局部patch相连接,且卷积核移动步长为10,则参数为:100×100×10×10,降低了2个数量级。 又能更好的学习,参数又低,卷积神经网络当然是可以成功了。

















 1513
1513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











