







目录
一、数据集
1.1 ExpW表情数据集
备用数据集,爬虫爬取的,原数据集并没有将人脸提取出来
数据预处理:
- 人脸倾斜(对齐)
- 无关数据(不是人脸)
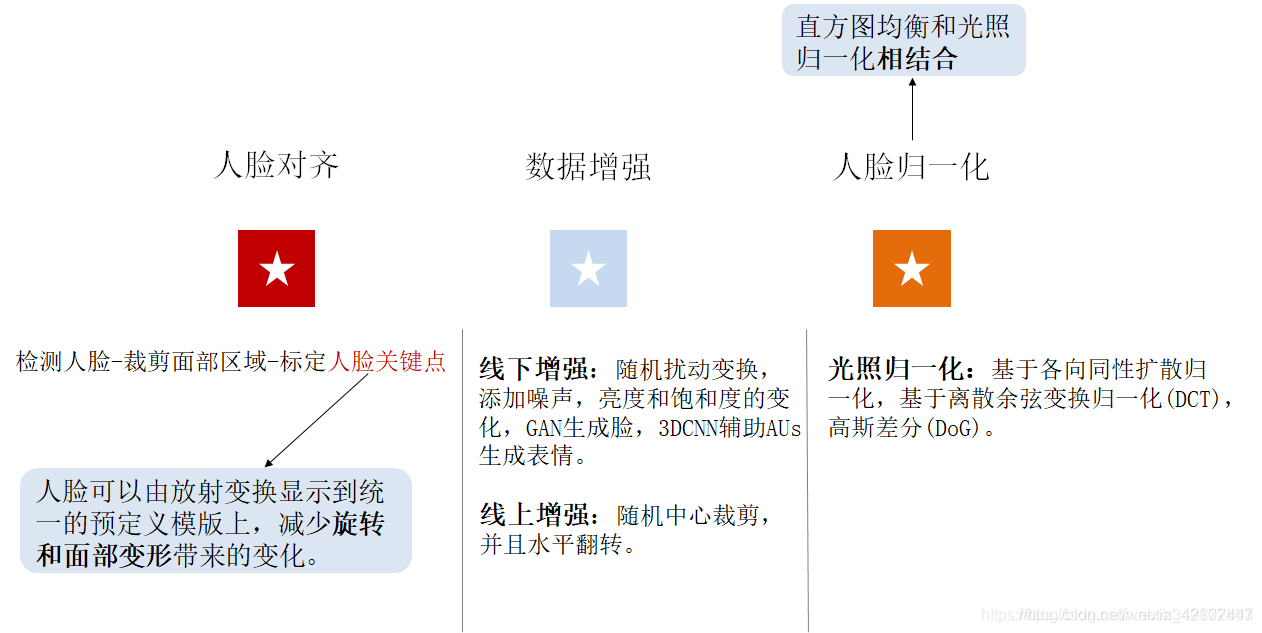
表情识别/情绪识别:ExpW表情数据集
表情识别/情绪识别:ExpW表情数据集
《Deep Facial Expression Recognition:A Survey》论文笔记
1.2 人脸表情数据集-fer2013
由35886张人脸表情图片组成:
测试:28708张
公共验证图:3589
私有验证图:3589
48×48的灰度图像
共7种表情:
0 anger 生气
1 disgust 厌恶
2 fear 恐惧
3 happy 开心
4 sad 伤心
5 surprised 惊讶
6 normal 中性
处理完了才发现fer2013有了微软更正标注版本的fer+…(难受)
1.3 FERPlus
FER2013和FERPlus是常用的表情识别训练集。
https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data
FERPlus可以下载:
https://www.worldlink.com.cn/osdir/ferplus.html
fer2013人脸表情识别案例
Tensorflow读取fer2013
pytorch人脸表情识别实验——fer2013
1.3.1 数据集读取
data = pd.read_csv('../input/fer2013.csv')
1.4 数据集预处理
Deep Facial Expression Recognition: A Survey笔记

再开始识别表情之前得先对齐脸
参考代码文章
也可以直接使用第三方库 face_recognition
- face_recognition是基于dlib的深度学习人脸识别库,在LFW上的准确率达到了99.38%
- face_recognition包括人脸检测、人脸关键点检测、人脸识别等接口
- 人脸检测:返回的结构是一个list,每个人脸是一个tuple存储,分别代表框住人脸的矩形中左上角和右下角的坐标(x1,y1,x2,y2)
- 人脸关键点检测:得到人脸特征点list,每个人脸是一个字典,包括nose_bridge、right_eyebrow、right_eye、chine、left_eyebrow、bottom_lip、nose_tip、top_lip、left_eye几个部分,每个部分包含若干个特征点(x,y),总共有68个特征点。
import face_recognition
import matplotlib.pyplot as plt
import cv2
import numpy as np
image = face_recognition.load_image_file("1.png")
# 载入图像
face_locations = face_recognition.face_locations(image)
# 寻找脸部
top, right, bottom, left = face_locations[0]
# 将脸部框起来
face_image = image[top:bottom, left:right]
face_image = cv2.resize(face_image, (48,48))
face_image = cv2.cvtColor(face_image, cv2.COLOR_BGR2GRAY)
face_image = np.reshape(face_image, [face_image.shape[0], face_image.shape[1],1])
# 调整到可以进入该模型输入的大小
# show
plt.imshow(face_image) # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()
# save
# 适用于保存任何 matplotlib 画出的图像,相当于一个 screencapture
plt.savefig('2.png')
1.5 爬虫爬取表情包(测试集)
#test_爬取来自www.doutula.com的表情包
from urllib import request
from urllib import parse
import urllib
import re
import sys
import os
import time
page=1
x=0
totolnum=0
sys.stdin.encoding
def filename(keyword):
path=os.path.abspath('.')
newpath=path+'\\img\\'+keyword
if(os.path.exists(newpath)==False):
os.makedirs(path+'\\img\\'+keyword)
return newpath
def link(keyword,pagenum):
qkeyword=urllib.parse.quote(keyword)
page="&page="+str(pagenum)
search='search?type=photo&more=1&keyword='
url="http://www.doutula.com/"
link=url+search+qkeyword+page
req=request.Request(link)
req.add_header('user-agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36')
text=request.urlopen(req).read()
text=text.decode('utf-8')
return text
def content(keyword,pagenum):
text=link(keyword,pagenum)
pattern1='data-original="(http|https):(/|\w|\.)+(gif|jpg|png)"'
match=re.finditer(pattern1,text)
return match
keyword=input("请输入想要爬取的表情包的名字 ")
page=int(input("请输入爬取页数 "))
newpath=filename(keyword)
if os.path.exists('match.txt')==True:
os.remove('match.txt')
for pagei in range(1,page+1):
match=content(keyword,pagei)
f=open('match.txt','a+')
f.write('\n')
for i in match:
f.write(i.group())
f.write('\n')
totolnum+=1
f.close()
f=open('match.txt','r+')
str=f.read()
pattern2='(http|https):(/|\w|\.)+(gif|jpg|png)'
src=re.finditer(pattern2,str)
for i in src:
urllib.request.urlretrieve(i.group(),newpath+'\\'+'%s.jpg' %(x+1))
x+=1
print('正在爬取%d/%d' %(x,totolnum))
time.sleep(0.8)
f.close()
if totolnum==0:
print('对不起,找不到关于%s的表情包,请重新输入' %keyword)
else:
print('爬取完成,爬取%d个文件\n保存在%s' %(totolnum,newpath))
二、表情识别模型
2.1 模型输入需求
三、微博爬取评论
python爬虫之爬取手机微博评论(图文并排,炒鸡详细!!!)
python爬取微博评论及评论中的图片
NLP之情感分析:基于python编程(jieba库)实现中文文本情感分析(得到的是情感评分)
深度学习网络图画图工具
使用表情生成新的图片
PyTorch实现"StarGAN:使用单一模型执行多个域的图像转换"。
表情识别之scn
认识了一个新的库:Hugging Face
Hugging face快速入门:是Transformers的库















 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











