







 本文分析了Stable Diffusion模型的计算量,主要包括TextEncoder、UNet2DCondition、VAE Encoder+Decoder。UNet2DCondition是图像生成的主要部分,参数量大,卷积和矩阵计算各占约一半运算量。VAE的Encoder和Decoder以卷积为主,运算量巨大。建议通过降低输出分辨率并结合超分辨率网络提高图像质量,而非直接增大模型分辨率。
本文分析了Stable Diffusion模型的计算量,主要包括TextEncoder、UNet2DCondition、VAE Encoder+Decoder。UNet2DCondition是图像生成的主要部分,参数量大,卷积和矩阵计算各占约一半运算量。VAE的Encoder和Decoder以卷积为主,运算量巨大。建议通过降低输出分辨率并结合超分辨率网络提高图像质量,而非直接增大模型分辨率。
准备
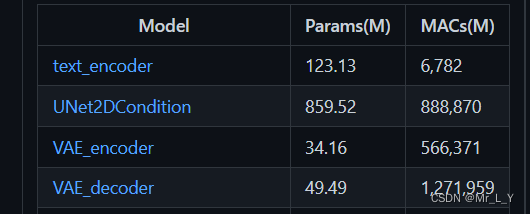
模型的参数量和计算量参考: ThanatosShinji/onnx-tool: ONNX model's shape inference and MACs(FLOPs) counting. (github.com)这四个模型就是Stable Diffusion 1.4 最主要的4个onnx模型:
github中的百度网盘可以下载带中间tensor shape的模型. 比如:
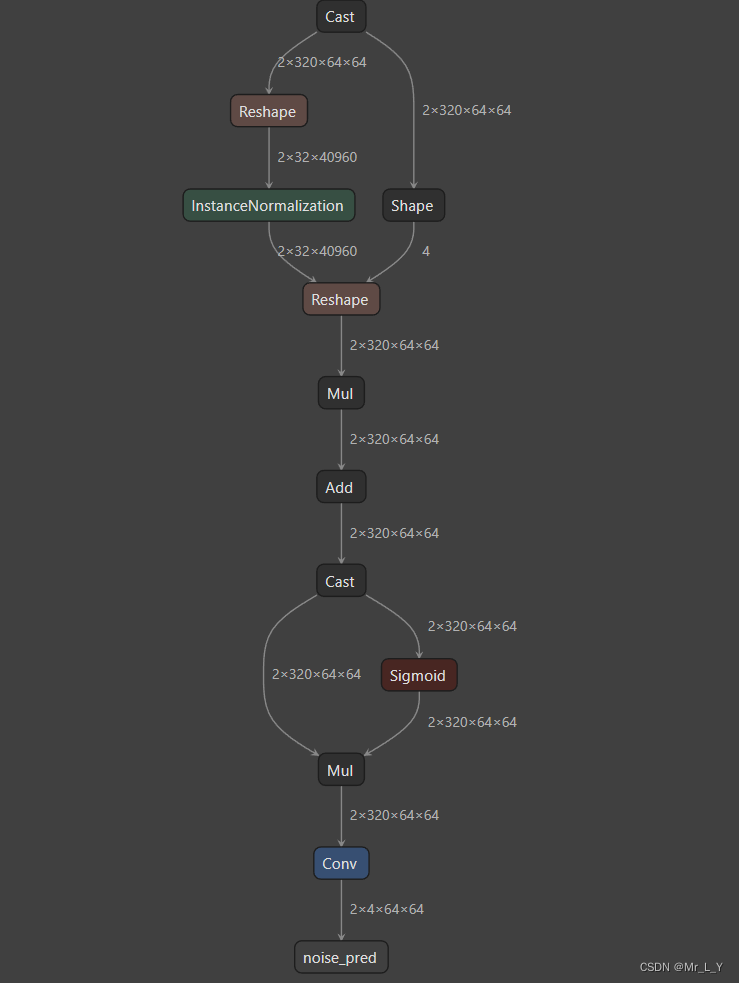
TextEncoder
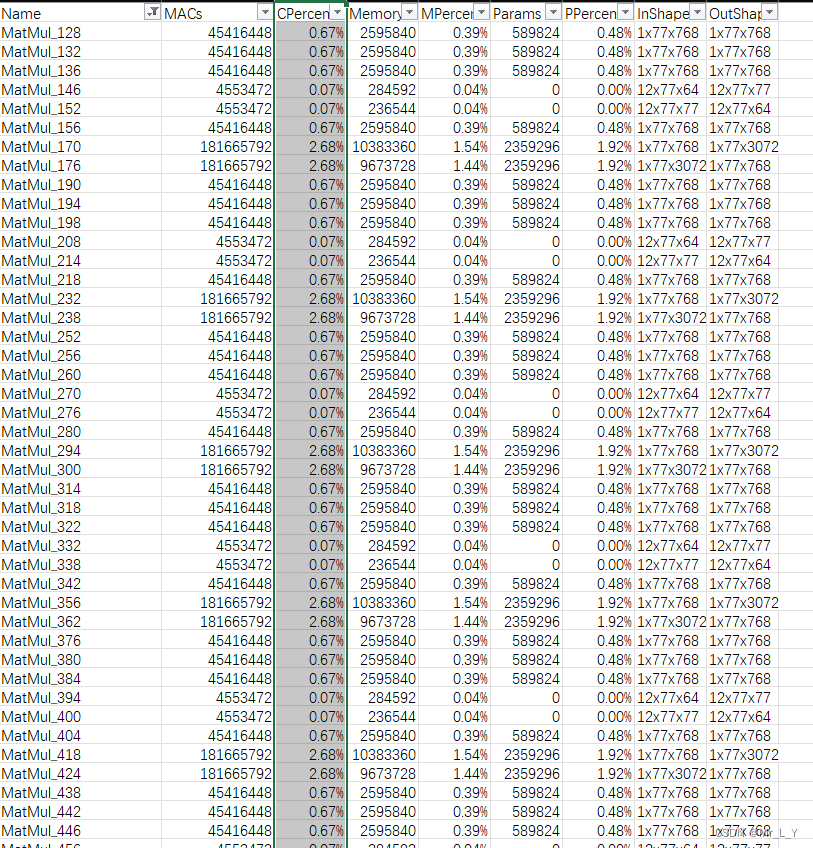
这个模型很像BERT, 12 layers的Bert Base. 运算量6.7GMACs.
和 BertBase一样, 运算量98%都集中在MatMul上面.
这个token生成了1x77x768的hidden state需要送给UNetCondition.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2580
2580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









