






非计算机专业,对爬虫比较感兴趣,最近又在学爬虫相关的知识,自己写了点实战的练习项目,在CSDN上展示一下,一方面是记录一下自己学习成果和代码,另一方面,自己从CSDN上学到了不少,把自己写的一些东西展示出来,希望也可以帮到别人。
首先,导入需要的库
import urllib.request
import lxml.html输入目标网页和构造请求头
baidu_rul='https://top.baidu.com/board?tab=realtime'
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.58',
'Referer': 'http://baidu.com',
}User-agent是本机信息,若不定义,会被服务器认出来是机器访问,具体值可以在F12开发者工具-网络(network)中查看;Referer是访问来源,这里不是必须的。
使用urllib构造访问请求并进行访问获取响应
req=urllib.request.Request(baidu_rul,headers=headers)
resp=urllib.request.urlopen(req)使用lxml库解析网络节点
html=lxml.html.parse(resp)
hot_index=html.xpath('//*[@class="hot-index_1Bl1a"]/text()')#热力指数
hot_name=html.xpath('//*[@class="c-single-text-ellipsis"]/text()')#热搜标题
hot_url=html.xpath('//*[@class="title_dIF3B "]/@href')#热搜网址这里以热搜标题为例对XPath进行解释,“//”代表相对路径,表示选择任意(所有)位置的节点,“*”表示未知元素,“[@class="c-single-text-ellipsis"]"表示class为“c-single-text-ellipsis”的节点,“text()”表示选取该节点内的文本。
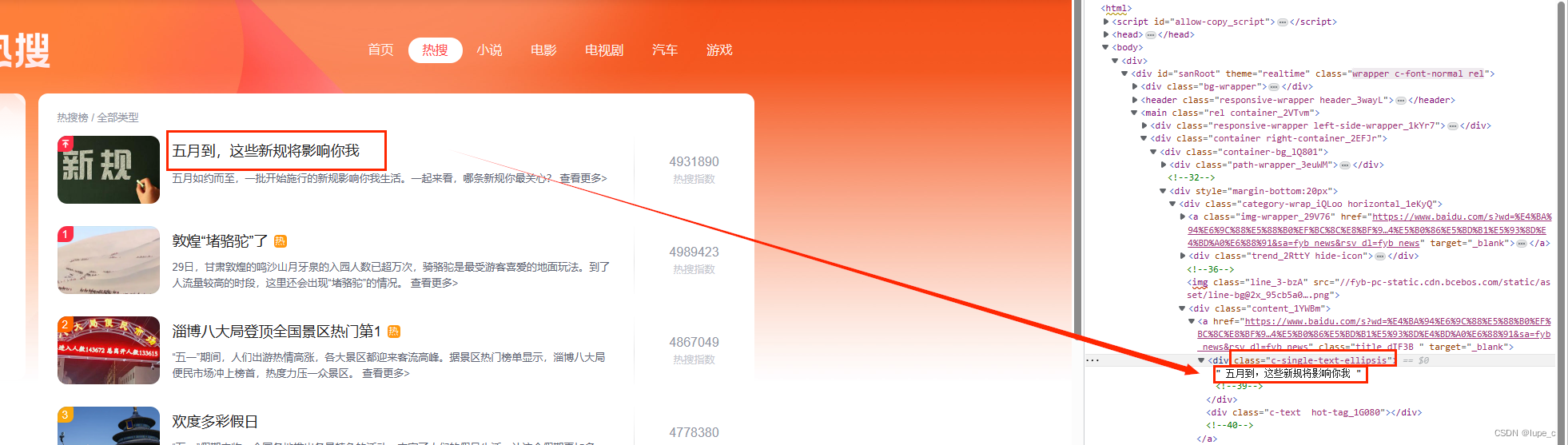
再对爬取结果进行打印
l=len(hot_index)
print(l)
for i in range(l):
print("热搜名称"+str(i)+":"+hot_name[i]+" 热力指数:"+hot_index[i]+" 网址:"+hot_url[i])爬取结果如下

源码如下
import urllib.request
import lxml.html
baidu_rul='https://top.baidu.com/board?tab=realtime'
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.58',
'Referer': 'http://baidu.com',
}
req=urllib.request.Request(baidu_rul,headers=headers)
resp=urllib.request.urlopen(req)
html=lxml.html.parse(resp)
hot_index=html.xpath('//*[@class="hot-index_1Bl1a"]/text()')
hot_name=html.xpath('//*[@class="c-single-text-ellipsis"]/text()')
hot_url=html.xpath('//*[@class="title_dIF3B "]/@href')
l=len(hot_index)
print(l)
for i in range(l):
print("热搜名称"+str(i)+":"+hot_name[i]+" 热力指数:"+hot_index[i]+" 网址:"+hot_url[i])













 1973
1973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









