







因为关于policytree的分析资料比较少,所以以下是我对charm源码中policytree和属性基加密的粗浅理解。有任何问题欢迎指正。
属性基加密
如下是维基关于属性基加密的定义。
Attribute-based encryption is a type of public-key encryption in which the secret key of a user and the ciphertext are dependent upon attributes (e.g. the country in which they live, or the kind of subscription they have). In such a system, the decryption of a ciphertext is possible only if the set of attributes of the user key matches the attributes of the ciphertext.
Attribute-based encryption - Wikipedia
但这样可能仍然不够清晰,我们以paper “Ciphertext-Policy Attribute-Based Encryption” 中提出的CP-ABE方案为例。在论文摘要中,作者提出CP-ABE技术是类似于角色访问控制。
Previous Attribute-Based Encryption systems used attributes to describe the encrypted data and built policies into user’s keys; while in our system attributes are used to describe a user’s credentials, and a party encrypting data determines a policy for who can decrypt. Thus, our methods are conceptually closer to traditional access control methods such as Role-Based Access Control (RBAC).
根据论文,CP-ABE大致可以分为如下几个部分(详细请阅读上述论文)该算法的实现在charm的schemes的属性基加密模块。
-
S
e
t
u
p
Setup
Setup. The setup algorithm takes no input other than the implicit security parameter. It outputs the public parameters
P
K
PK
PK and a master
key MK. - E n c r y p t ( P K , M , A ) Encrypt(PK, M, \mathbb{A}) Encrypt(PK,M,A). The encryption algorithm takes as input the public parameters PK, a message M, and an access structure A \mathbb{A} A over the universe of attributes. The algorithm will encrypt M and produce a ciphertext CT such that only a user that possesses a set of attributes that satisfies the access structure will be able to decrypt the message. We will assume that the ciphertext implicitly contains A \mathbb{A} A.
- K e y G e n e r a t i o n ( M K , S ) Key Generation(MK, S) KeyGeneration(MK,S). The key generation algorithm takes as input the master key MK and a set of attributes S that describe the key. It outputs a private key SK.
- D e c r y p t ( P K , C T , S K ) Decrypt(PK, CT, SK) Decrypt(PK,CT,SK). The decryption algorithm takes as input the public parameters PK, a ciphertext CT, which contains an access policy A \mathbb{A} A, and a private key SK, which is a private key for a set S of attributes. If the set S of attributes satisfies the access structure A \mathbb{A} A then the algorithm will decrypt the ciphertext and return a message M.
- D e l e g a t e ( S K , S ~ ) Delegate(SK, \widetilde{S}) Delegate(SK,S ). The delegate algorithm takes as input a secret key SK for some set of attributes S and a set S ~ ⊆ S \widetilde{S} \subseteq S S ⊆S. It output a secret key SK for the set of attributes S ~ \widetilde{S} S .
在加密过程中, E n c r y p t ( P K , M , A ) Encrypt(PK, M, \mathbb{A}) Encrypt(PK,M,A) 需要输入访问结构 A \mathbb{A} A(policy tree T \mathcal{T} T 便是其中一种结构),并在产生的 C T CT CT 密文中包含。而 K e y G e n e r a t i o n ( M K , S ) KeyGeneration(MK, S) KeyGeneration(MK,S) 则需要根据属性生成。解密过程 D e c r y p t ( P K , C T , S K ) Decrypt(PK, CT, SK) Decrypt(PK,CT,SK) 利用密文和私钥解开。
例子
为了更好地阐释如何通过这样的方式实现字段级的访问控制,我们通过一个简单的例子进行分析。考虑这样的情况,在教务系统中(education),对于数学成绩(math),老师(teacher)可以查看完整的表格如下表所示。
number name score
1 bob 99
2 charles 98
3 david 96
4 emily 100
而学生(student)则只能查看number字段和score字段,无法看到name字段,查看效果如下表所示,***表示密文。
number name score
1 *** 99
2 *** 98
3 *** 96
4 *** 100
为了实现上述的访问控制,我们的方案是,两个数据密钥dk,一个针对name字段,名为 d k n a m e dk_{name} dkname,一个针对score,为 d k s c o r e dk_{score} dkscore。而数据密钥 dk 的加密则通过属性基加密。假设 alice 是老师,我们就可以认为 alice 具有属性 teacher,而 bob 是学生,即具有student 属性。
对于
d
k
n
a
m
e
dk_{name}
dkname ,我们的策略(访问控制结构)应该是 “具有属性teacher 或者 既具有属性teacher 又具有属性student”,这里我们假设存在既是老师又是学生的情况(目的是为了使接下来介绍policy tree的policy更复杂些);而对于
d
k
s
c
o
r
e
dk_{score}
dkscore ,我们的策略是“具有属性teacher 或者 student”。
结合CP-ABE方案的特点,在密文中添加访问控制结构(policy tree),用户的 SK 通过属性集 S 制定。以字段 name 为例,密文中的 policy tree 是 “具有属性teacher 或者 既具有属性teacher 又具有属性student” 。对于 alice ,SK 中包含的属性是 teacher,因此它可以通过访问控制,解开密文,而对于 bob ,SK 中包含的属性是 student,因此它不能通过访问控制,无法解开密文。
这就是整个访问控制的过程,关于为啥用这样的形式进行访问控制,我们考虑这样的情况。假定,信息(name字段)需要传递给 n 个老师,如果采用传统的公钥算法,那么就需要用所有老师的公钥加密生成密文,也就会产生 n 份密文。这就是 CP-ABE 解决的问题。
Bethencourt J, Sahai A, Waters B. Ciphertext-policy attribute-based encryption[C]//2007 IEEE symposium on security and privacy (SP’07). IEEE, 2007: 321-334.
policy tree的分析
JHUISI/charm: Charm: A Framework for Rapidly Prototyping Cryptosystems
对于上述论文的代码实现,主要参考的是charm的schemes中的实现。在charm中 policytree 是二叉树。为了理解属性集加密的policy设置,我们把 policytree.py 从charm中单独提取出来,位置是charm/charm/toolbox/。
我们发现在prune函数中,主要调用的函数是 requiredAttributes,如下。它是一个递归的函数。主要有三种情况,一种是 AND 一种是 OR 一种是 ATTR。先从叶子节点,ATTR情况出发。当叶子节点的属性位于属性列表中时,返回 true 和树。
OR和AND都需要得到sendthis和result。但它们得到两者的计算方式不同,参考代码即可。
def requiredAttributes(self, tree, attrList):
""" determines the required attributes to satisfy policy tree and returns a list of BinNode
objects."""
if tree == None: return 0
Left = tree.getLeft()
Right = tree.getRight()
if Left: resultLeft, leftAttr = self.requiredAttributes(Left, attrList)
if Right: resultRight, rightAttr = self.requiredAttributes(Right, attrList)
if(tree.getNodeType() == OpType.OR):
# never return both attributes, basically the first one that matches from left to right
if resultLeft: sendThis = leftAttr
elif resultRight: sendThis = rightAttr
else: sendThis = None
result = (resultLeft or resultRight)
if result == False: return (False, sendThis)
return (True, sendThis)
if(tree.getNodeType() == OpType.AND):
if resultLeft and resultRight: sendThis = leftAttr + rightAttr
elif resultLeft: sendThis = leftAttr
elif resultRight: sendThis = rightAttr
else: sendThis = None
result = (resultLeft and resultRight)
if result == False: return (False, sendThis)
return (True, sendThis)
elif(tree.getNodeType() == OpType.ATTR):
if(tree.getAttribute() in attrList):
return (True, [tree])
else:
return (False, None)
return
运行其中的测试函数,结果如下。
Attrs in user set: ['1', '3']
case 1: ((1 or 2) and (2 and 3)) , pruned: False
case 2: (1 or (2 and 3)) , pruned: [1]
case 3: ((1 or 2) and (4 or 3)) , pruned: [1, 3]
形成的二叉树如下。
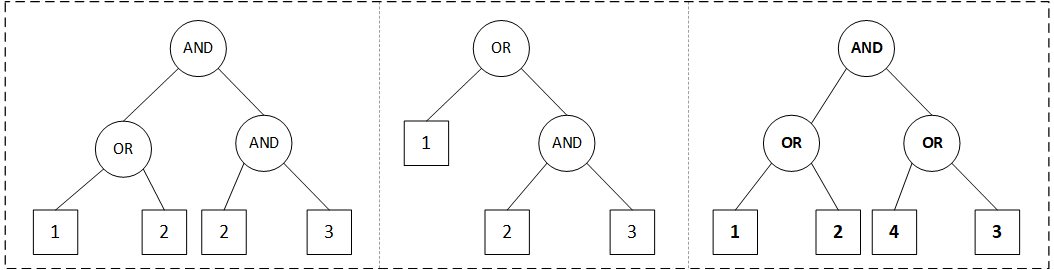
分析case 1,从左至右:
(1 OR 2),1属于attrList[1, 3](即意味sendThis=1,result=1),因此sendThis=1,result=1(True);
(2 AND 3),2不属于(即意味着sendThis=None,result=0),3属于,故sendThis=3,result=0;
((1 or 2) and (2 and 3)),因此sendThis=1,result=0。故返回False无法通过。
分析case 2,从左至右:
(2 and 3),2不属于,3属于,故sendThis=3,result=0;
(1 or (2 and 3)),1属于,故sendThis=1,result=1。故返回 [1]。
分析case 3,从左至右:
(1 or 2),1属于,2不属于,故sendThis=1,result=1;
(4 or 3),4不属于,3属于,故sendThis=3,result=1;
((1 or 2) and (4 or 3)),sendThis=[1,3],result=1。故返回[1,3]
实验验证
回到刚才那个例子,根据policytree的性质,我们对于
d
k
n
a
m
e
dk_{name}
dkname 和
d
k
s
c
o
r
e
dk_{score}
dkscore 的策略分别如下:
d
k
n
a
m
e
dk_{name}
dkname ((STUDENT and TEACHER) or TEACHER)
d
k
s
c
o
r
e
dk_{score}
dkscore (STUDENT or TEACHER)
通过如下代码进行实验验证,如果前面所述均正确,那么预测结果(代码注释部分)相符。
parser = PolicyParser()
attrs1 = ['TEACHER']
attrs2 = ['STUDENT']
tree1 = parser.parse("((STUDENT and TEACHER) or TEACHER)") # for name
tree2 = parser.parse("(STUDENT or TEACHER)") # for score
# for teacher
print("alice with attributes 'TEACHER':")
print(tree1, ", pruned: ", parser.prune(tree1, attrs1)) # True
print(tree2, ", pruned: ", parser.prune(tree2, attrs1)) # True
# for student
print("\n")
print("bob with attributes 'STUDENT':")
print(tree1, ", pruned: ", parser.prune(tree1, attrs2)) # False
print(tree2, ", pruned: ", parser.prune(tree2, attrs2)) # True
运行结果如下:alice的两个均通过。
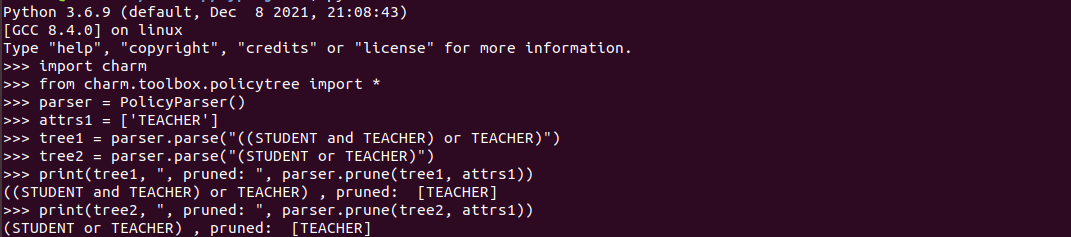
bob的则第一个无法通过。符合实验预测。

到此就基本完成,然后最后看下,最终访问控制的效果图。对于alice而言,可以看到所有的信息。

对于bob而言,中间的name信息则是加密的。


















 427
427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









