






目录
1.循环神经网络与NLP
1.1 序列模型
1.1.1 分类问题与预测问题
图像分类:当前输入->当前输出
时间序列预测:当前+过去输入->当前输出
自回归模型:保留一些对过去观测的总结ℎ𝑡, 并且同时更新预测。
1.2 数据预处理
1.2.1 特征编码
由于机器学习算法都是在矩阵上执行线性代数计算,所以参加计算的特征必须是数值型的,对于非数值型的特征需要进行编码处理。对于离散型数据的编码,我们通常会使用两种方式来实现,分别是标签编码和独热编码
标签编码:将类别型特征从字符串转换为数字
特点:解决了分类编码的问题,可以自由定义量化数字数值本身没有任何含义,仅是标识或者排序的作用可解释性比较差
适用范围:对于定序类型的数据,使用标签编码更好,虽然定序类型也属于分类,但是其有排序逻辑对数值大小不敏感的模型(如树模型),建议使用标签编码。
独热编码:采用 N NN 位状态寄存器来对 N NN 个可能的取值进行编码,每个状态都由独立的寄存器来表示,并且在任意时刻只有其中一位有效
特点:解决了分类器不好处理分类变量的问题,同时也可以扩展特征编码后的属性是稀疏的,存在大量的零元分量。当类别非常多时,特征空间会非常大,容易导致维度灾难的问题
适用范围:适用于定类类型的数据,该类型数据是纯分类,不进行排序,互相之间也没有逻辑关系
对数值大小敏感的模型,必须使用独热编码。
1.2.2 文本处理
按单词处理:文本切分 (tokenization)
1.3 文本预处理与词嵌入
1.3.1 文本预处理
一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。 我们将解析文本的常见预处理步骤。 这些步骤通常包括:
- 将文本作为字符串加载到内存中。
- 将字符串切分为词元(如单词和字符)。
- 建立一个字典,将拆分的词元映射到数字索引。
- 将文本转换为数字索引序列,方便模型操作。
文本预处理实例: IMDB影评数据集
IMDB影评数据集
- 5万条电影评论
- 每条评论可分为正面或负面
- 是一个二分类问题
- 2.5万条训练数据, 2.5万条测试数据
1.3.2 文本嵌入
词嵌入(word embedding),将独热向量映射为低维向量。
- 原始向量: 𝑣维;
- 映射后: 𝑑维, 𝑑 ≪ 𝑣;
- 映射矩阵: 𝑑 × 𝑣, 根据训练数据学习得
1.4 RNN模型
如何建模序列数据?图像分类中使用: 1对1模型输入和输出维度:固定
文本处理中:输入维度不定(可能一直有单词输入);输出维度不定或者是1(直接最终理解结果)
随着输入的增加,会产生“遗忘”问题
RNN误差反传
神经网络的训练目标,是最小化网络的代价函数E。为了找到使E取得最小值时的参数值,会使用梯度下降算法。而运行梯度下降算法,就需要计算出E关于网络中各个参数w和b的偏导数:
2 生成对抗网络
2.1 GAN
GAN是一类神经网络,可以像人类一样生成图像、音乐、语音或文本等素材。 GANs是近年来一个活跃的研究课题。 Facebook的人工智能研究主管Yann,LeCun称对抗式训练是机器学习领域“过去10年中最有趣的想法”。
AN是一种机器学习系统,可以学习模仿给定的数据分布。深度学习专家
Ian Goodfellow等在2014年的NeurIPS论文中首次提出了这一观点。GANs由两个神经网络组成,一个用于生成数据,另一个用于区分虚假数据和真实数据。目前典型的应用包括:
- 使用CycleGan进行风格转换
- 使用Deepfacelab生成人脸
2.1.1 判别模型
在训练过程中,将使用算法调整模型的参数。目标是最小化损失函数,以使模型学习在给定输入时的输出概率分布。在训练阶段之后,使用该模型通过估计输入对应的最可能的数字对手写数字图像进行分类
2.1.2 生成模型
然而,像GANs这样的生成模型经过训练,可以用概率模型来描述数据集是如何生成的。通过从生成模型中采样,您可以生成新数据。判别模型用于监督学习,而生成模型通常用于未标记的数据集,可以看作是一种无监督学习。了输出新的样本,生成模型通常考虑一个随机元素影响模型生成的样本。用于驱动生成器的随机样本来自一个隐空间,其中的向量代表了生成样本的一种压缩形式。与判别性模型不同,生成性模型学习输入数据x的概率P(x),通过掌握输入数据的分布,它们能够生成新的数据实例。
2.2 GAN架构
生成式对抗网络由两个神经网络组成,即生成器和判别器。生成器的作用是估计真实样本的概率分布,以便提供与真实数据相似的生成样本。判别器被训练来估计一个给定样本来自真实数据而不是由生成器提供的概率。这些结构被称为生成式对抗网络,因为生成器和鉴别器被训练成相互竞争:生成器试图更好地欺骗鉴别器,而鉴别器则试图更好地识别生成的样本。
为了理解GAN训练的工作原理,考虑一个由二维样本(𝑥1, 𝑥2)组成的数据集的简单例子, 在0到2𝜋的区间内, 𝑥₂ = sin(𝑥1) ,如下图所示。
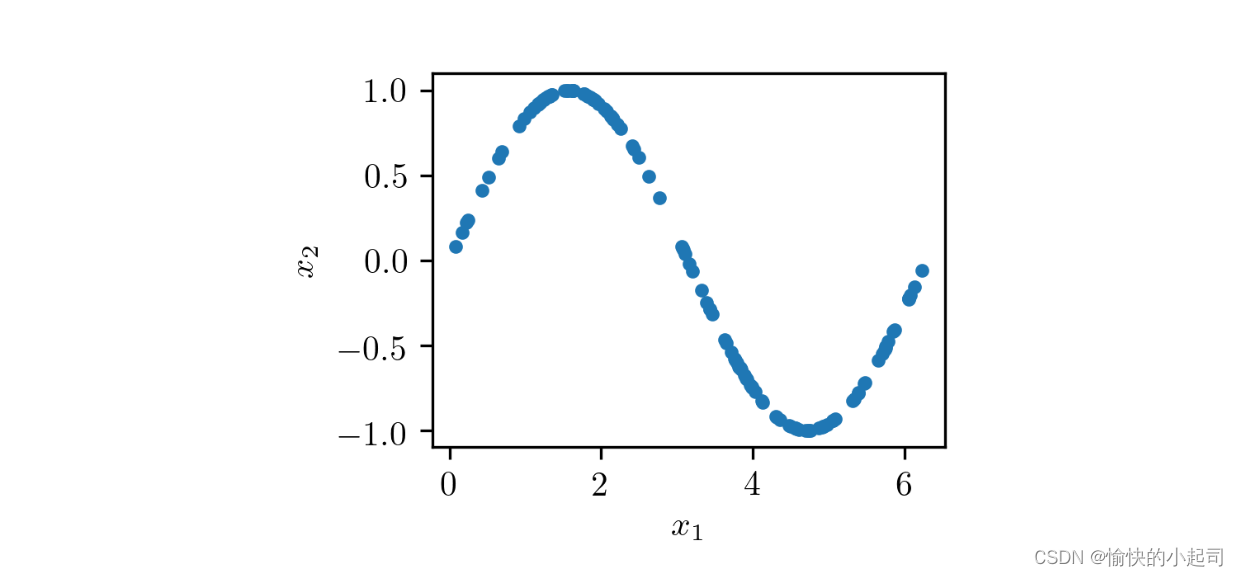
正如你所看到的,这个数据集由位于正弦曲线上的点(𝑥1, 𝑥2)组成,有一个非常特殊的分布。一个生成类似于数据集样本的GAN的整体结构。
- 生成器 𝐺 输入为隐空间的随机数据,它的作用是生成类似于真实样本的数据。在这个例子中,你有一个二维的隐空间,因此生成器被输入随机的(𝑧1, 𝑧2)对,并对它们进行转换,使它们与真实样本相似。
- 𝐺的结构可以是任意的,可使用多层感知器(MLP)、卷积神经网络(CNN)或任何其他结构,只要输入和输出的尺寸与隐空间和真实数据的维数相匹配
- 鉴别器𝐷接收来自训练数据集的真实样本或G提供的生成样本,其作用是估计输入属于真实数据集的概率。输入来自真实样本时输出1,来自生成样本时输出0。
- 鉴别器𝐷 同样可选择任意的神经网络结构。在本例中,输入是二维的,输出
- 可以是从0到1的标量。
- GAN训练过程由两人minimax博弈组成,其中D用于最小化真实样本和生成样本之间的识别误差, G用于最大化D出错的概率。虽然包含真实数据的数据集没有标记,但D和G的训练过程是以有监督的方式执行的
- 在训练的每个步骤中, 𝐷和𝐺都会更新其参数。在最初的GAN方案中, 𝐷的参数被更新𝑘次,而𝐺的参数对于每个训练步骤只更新一次。本例中,为了使训练更简单,考虑𝑘等于1。
为了训练𝐷,在每次迭代中,将从训练数据中获取的真实样本标记为1,将提供的一些生成样本标记为0。这样,可以使用传统的监督训练框架来更新𝐷的参数,以最小化损失函数
3 Transformer
3.1 定义
Transformer是什么?将Transformer模型看成是一个黑箱操作。在机器翻译中,就是输入一种语言,输出另一种语言。
Transformer由编码组件、解码组件和它们之间的连接组成。
3.2 组件部分
3.2.1 编码器
编码组件部分由6个编码器(encoder)叠在一起构成。解码组件部分也是由相同数量的解码器(decoder)组成的。所有的编码器在结构上都是相同的,但它们没有共享参数。每个解码器都可以分解成两个子层.
3.2.2 解码器
解码器中也有编码器的自注意力层和前馈层。除此之外,这两个层之间还有一个注意力层,用来关注输入句子的相关部分
3.3 编码
3.3.1 词嵌入
在NLP中,将每个输入单词通过词嵌入算法转换为词向量。每个单词都被嵌入为512维的向量,我们使用方框格子来表示这些向量。
3.3.2 编码
编码器接收向量列表作为输入,接着将向量列表中的向量传递到自注意力层进行处理,然后传递到前馈神经网络层中,将输出结果传递到下一个编码器中。
3.4 注意力机制
3.4.1 如何使用向量计算注意力
查询、键与值向量:计算自注意力的第一步就是从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量、一个键向量和一个值向量。这三个向量是通过词嵌入与三个权重矩阵后相乘创建的。计算自注意力的第二步是计算得分。为这个例子中的第一个词“Thinking”计算自注意力向量,需要拿输入句子中的每个单词对“Thinking”打分。这些分数决定了在编码单词“Thinking”的过程中有多重视句子的其它部分。第五步是将每个值向量乘以softmax分数(为了准备之后求和)。这里的直觉是希望关注语义上相关的单词,并弱化不相关的单词(例如,让它们乘以0.001这样的小数)。
3.4.2 多头注意力机制
增加 “多头”注意力机制,在两方面提高了注意力层性能,扩展了模型专注于不同位置的能力。,给出了注意力层的多个“表示子空间”。需八次不同的权重矩阵运算,我们就会得到八个不同的Z矩阵。
3.5 训练与输出
3.5.1 模型训练
单词翻译:比如说我们正在训练模型——把“merci”翻译为“thanks”。这意味着我们想要一个表示单词“thanks”概率分布的输出。但是因为这个模型还没被训练好,所以不太可能现在就出现这个结果。
句子输出:输入“je suis étudiant”
4 NeRF
4.1 三维重构网络
NeRF(Neural Radiance Fields)最早在2020年ECCV会议上发表,作为Best Paper,其将隐式表达推上了一个新的高度,仅用 2D 的 posed images 作为监督,即可表示复杂的三维场景。 NeRF迅速发展起来,被应用到多个技术方向上,例如新视点合成、三维重建等等,并取得非常好的效果.NeRF其输入稀疏的多角度带pose的图像训练得到一个神经辐射场模型,根据这个模型可以渲染出任意视角下的清晰的照片,也可以简要概括为用一个MLP神经网络去隐式地学习一个三维场景.
5 大语言模型
大语言模型是深度学习的分支。深度学习是机器学习的分支,大语言模型是深度学习的分支。
大语言模型是深度学习的应用之一,尤其在自然语言处理(NLP)领域。这些模型的目标是理解和生成人类语言。为了实现这个目标,模型需要在大量文本数据上进行训练,以学习语言的各种模式和结构。如 ChatGPT,就是一个大语言模型的例子。被训练来理解和生成人类语言,以便进行有效的对话和解答各种问题。
大语言模型和生成式 AI 存在交集
大型语言模型被训练来解决通用(常见)的语言问题,如文本分类、问答、文档总结和文本生成等。
(1)文本分类:大型语言模型可以通过对输入文本进行分析和学习,将其归类到一个或多个预定义的类别中。例如,可以使用大型语言模型来分类电子邮件是否为垃圾邮件,或将推文归类为积极、消极或中立。
(2)问答:大型语言模型可以回答用户提出的自然语言问题。例如,可以使用大型语言模型来回答搜索引擎中的用户查询,或者回答智能助手中的用户问题。
(3)文档总结:大型语言模型可以自动提取文本中的主要信息,以生成文档摘要或摘录。例如,可以使用大型语言模型来生成新闻文章的概要,或从长篇小说中提取关键情节和事件。
(4)文本生成:大型语言模型可以使用先前学习的模式和结构来生成新的文本。例如,可以使用大型语言模型来生成诗歌、短故事、或者以特定主题的文章
6.语言-图像模型
6.1 Segment anything
- 在多模态异常检测的背景下对GPT-4V进行了彻底的评估
- 考虑四个模式:图像、视频、点云和时间序列
- 探索九项特定任务,包括工业图像异常检测/定位、点云异常检测、医学图像异常检测/定位,逻辑异常检测,行人异常检测、交通异常检测和时间序列异常检测。 评估包括15个数据集的多样性。
仅作交流学习,如有错误,敬请批评指正!














 331
331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









