







原文地址https://www.analyticsvidhya.com/blog/2016/04/complete-tutorial-tree-based-modeling-scratch-in-python/
翻译自analyticsvidhya
基于树的学习算法被认为是最好的和最常用的监督学习(supervised learning)方法之一。基于树的方法赋予预测模型高精度,稳定性和易于解释的能力。 与线性模型不同,它们非常好地映射非线性关系。 它们适应于解决手头的任何问题(分类或回归)。
决策树,随机森林,梯度提升等方法被广泛用于各种数据科学问题。 因此,对于每个分析师(新手也是一样)来说,重要的是学习这些算法并将其用于建模。
本教程旨在帮助初学者从头开始学习基于树的建模。 成功完成本教程之后,人们期望熟练使用基于树的算法和构建预测模型。
注意:本教程不需要机器学习的先验知识。 然而,R或Python的基本知识将是有帮助的。 在开始本教程前你可以从头开始学习Python或者R语言。
- 什么是决策树? 它是如何工作的 ?
决策树是一种主要用于分类问题的监督学习算法(具有预先定义的目标变量)。 它适用于分类变量和连续型的输入输出变量。 在这种技术中,我们基于输入变量中最重要的分割器/微分器将总体或样本分成两个或更多个同质集合(或子集群)。

dt.png
例子:
假设我们有30个学生的样本,有三个变量:性别(boy/girl),班级(IX / X)和身高(5到6英尺)。 30名孩子中间有15个在业余时间打板球。 现在,我想创建一个模型来预测谁将在业余时间玩板球? 在这个问题中,我们需要根据所有三个中最重要的输入变量来区分在休闲时间玩板球的学生。
这是决策树最有用的地方,它将基于三个变量的所有值划分学生,并识别变量,这创建了最好的同质学生集合(彼此是异质的)。 在下面的截图中,您可以看到变量Gender与其他两个变量相比能够最好的识别同类集。

Test-1024x249.png
如上所述,决策树识别最重要的变量,它是给出最佳同质集合的值。 现在的问题是,它如何识别变量和分裂? 为此,决策树使用了各种算法,我们将在下一节中讨论。
决策树的类型
决策树的类型是由我们所拥有的目标变量的类型决定的。它可以有两种类型:
分类变量决策树:目标变量是分类变量的决策树被称为分类变量决策树。示例: 在上述的学生问题当中,目标变量是“学生将打板球”,即YES或NO。
连续变量决策树:决策树具有连续型的目标变量,则称为连续变量决策树。假设我们有一个问题来预测客户是否会向保险公司支付续保费(是/否)。 在这里,我们知道客户的收入是一个重要的变量,但保险公司没有所有客户的收入明细。 现在,我们知道这是一个重要的变量,那么我们可以构建一个决策树,根据职业,产品和各种其他变量来预测客户收入。 在这种情况下,我们预测连续变量的值。
与决策树相关的重要术语(important terminology)
让我们来看看决策树使用的基本术语:
根节点(root node):它代表整个群体或样本,并且会进一步被划分为两个或更多个同质集合。
分裂(splitting):这是将节点划分为两个或更多个子节点的过程。
决策节点(decision node):当子节点拆分为更多的子节点时,称为决策节点。
叶/终端节点(leaf/terminal node):节点不分裂称为叶节点或终端节点。
修剪(prunning):当我们删除决策节点的子节点时,这个过程称为修剪。 你可以说分裂的相反过程。
分支/子树(branch/sub-tree):整个树的子部分称为分支或子树。
父子节点(parent and child node):被划分为子节点的节点被称为子节点的父节点,其中子节点是父节点的子节点。

Decision_Tree_2.png
以上这些都是通常用于决策树的术语。我们知道每个算法都有优缺点,下面是我们应该知道的重要因素。
优点
容易理解(Easy to Understand):决策树输出非常容易理解,即使对于非分析背景的人。它不需要任何统计知识来阅读和解释它们。它的图形表示非常直观,用户可以很容易联系到他们的假设。
在数据探索中有用(Useful in Data Exploration):决策树是识别最重要变量和两个或更多变量之间关系的最快方法之一。在决策树的帮助下,我们可以创建具有更好的预测目标变量的能力的新变量/特征。你可以参考这篇文章(Trick to enhance power of Regression model)。它也可以用于数据探索阶段。例如,我们正在处理一个问题,其中我们有数百个变量,决策树将有助于识别出其中最重要的变量。
更少的数据清理(Less data cleaning required):与其他一些建模技术相比,它需要更少的数据清理。它一定程度上不受异常值和错误值的影响。
数据类型不是约束(Data type is not a constraint):它可以处理数值和分类变量。
非参数方法(Non Parametric Method):决策树被认为是一个非参数方法。这意味着决策树没有关于空间分布和分类器结构的假设。
缺点
过拟合(Over fitting):过拟合是决策树模型最实际的困难之一。 通过设置模型参数和修剪的约束(下面将详细讨论)解决这个问题。
不适合连续变量(Not fit for continuous variables):当使用连续数值变量时,决策树在将变量分类到不同类别时会丢失信息。
2.回归树和分类树
我们都知道终端节点(或叶)位于决策树的底部。 这意味着决策树通常被倒置地绘制,使得叶子是底部和根部是顶部(如下所示)。

111.png
两个树的工作模式几乎相似,让我们看看分类树和回归树之间的主要差异和相似性:
当因变量(dependent variables)是连续变量时,使用回归树。当因变量是分类变量时,使用分类树。
在回归树的情况下,由训练数据中的终端节点获得的值是落在该区域中的观测值的平均响应。因此,如果一个不可见的数据观测值属于该区域,我们将用平均值进行预测。
在分类树的情况下,终端节点在训练数据中获得的值(类)是落在该区域中的众数。因此,如果一个不可见的数据观测值落在该区域,我们将使用众数值进行预测。
这两棵树将预测变量空间(自变量)划分为不同的和非重叠的区域。为了简单起见,您可以将这些区域视为高维盒子或箱子。
两个树都遵循称为递归二进制分裂的自上而下的贪婪方法。我们将其称为“自上而下”,因为当所有观察结果在单个区域中可用时,它从树的顶部开始,并且连续地将预测器空间分割成树中的两个新分支。它被称为“贪婪”,因为,算法仅仅关心(寻找最佳可用变量)关于当前的分裂,而不是关于未来分裂(而这将导致更好的树)。
该分裂过程继续,直到达到用户定义的停止标准。例如:一旦每个节点的观测数量小于50,我们就可以告诉算法停止。
在这两种情况下,分裂过程导致完全生长的树,直到达到停止标准。但是,完全生长的树可能过度拟合数据,导致未知数据的准确性差。这带来了“修剪”。修剪是使用滑轮过度配合的技术之一。我们将在下一节中详细了解它。
3.树如何决定在哪里分裂?
树的分裂策略严重影响树的准确性。分类树和回归树的决策标准是不同的。
决策树使用多个算法来决定将一个节点分裂成两个或更多个子节点。子节点的创建增加了所得到的子节点的同质性。 换句话说,我们可以说,节点的纯度相对于目标变量增加。 决策树分裂所有可用变量上的节点,然后选择导致最一致子节点的分裂。
算法选择也基于目标变量的类型。 让我们来看看决策树中最常用的四种算法:
吉尼指数(Gini Index)
吉尼指数指出,如果我们从一个群体中随机选择两个项目,而且它们必须是相同的类别,如果群体是单一的,那么概率为1。
它的分类目标变量只能是“成功”或“失败”
它只执行二进制拆分
Gini的值越高,同质性越高。
CART(分类和回归树)使用Gini方法创建二进制拆分。
计算分裂的Gini指数的步骤:
计算子节点的吉尼指数(成功和失败概率的平方和,
p
2
+
q
2
p2+q2
p2+q2)
使用该分割的每个节点的加权Gini分数计算分割的Gini指数
例子
参考上面使用的示例,其中我们想基于目标变量(玩或不玩板球)来划分学生。 在下面的快照中,我们使用两个输入变量Gender和Class来拆分总体。 现在,我想确定哪个拆分使用Gini指数能够生成更均匀的子节点。

Decision_Tree_Algorithm1.png
基于性别分裂:
子节点Female的Gini指数 =(0.2)(0.2)+(0.8)(0.8)= 0.68
子节点Male的Gini指数 =(0.65)(0.65)+(0.35)(0.35)= 0.55
计算基于性别分裂的加权Gini指数=(10/30)* 0.68 +(20/30)* 0.55 = 0.59
相似地,基于年级的分裂:
子节点类IX的Gini指数 =(0.43)(0.43)+(0.57)(0.57)= 0.51
子节点类X的Gini指数=(0.56)(0.56)+(0.44)(0.44)= 0.51
计算基于年级分裂的加权Gini指数=(14/30)* 0.51 +(16/30)* 0.51 = 0.51
在上面,您可以看到,“Gender”的Gini分数高于“Class”的分数,因此,节点拆分将在“Gender”上进行。
卡方(Chi-Square)
它是一种计算子节点和父节点之间的差异的统计显著性的算法。 我们通过目标变量的观测频率和预期频率之间的标准差的平方和来测量。
它的分类目标变量只能是“成功”或“失败”
它可以执行两个或多个拆分。
Chi-Square的值越高,子节点和父节点之间的差异的统计显著性就越高。
每个节点的卡方使用公式计算
ξ
=
(
A
c
t
u
a
l
–
E
x
p
e
c
t
e
d
)
2
E
x
p
e
c
t
e
d
\xi = \sqrt[]{(Actual – Expected)^2 \over Expected}
ξ=Expected(Actual–Expected)2
它产生的树称为CHAID(卡方自动交互检测器)
计算分裂的卡方值的步骤:
通过计算成功和失败的偏差计算个体节点的卡方
使用分割的每个节点的成功和失败的所有卡方的和计算分裂的卡方值
例子
我们依然使用上面计算吉尼指数的例子
基于性别的分裂:
首先我们填写节点Female的值,填入“Play Cricket”和“Not Play Cricket”的实际值,这里分别是2和8。
计算“Play Cricket”和“Not Play Cricket”的期望值,因为父节点具有50%的概率,我们对女性计数(10)应用相同的概率。
使用公式计算偏差,
A
c
t
u
a
l
−
e
x
p
e
c
t
e
d
Actual - expected
Actual−expected。 它们分别是“Play Cricket”(2 - 5 = -3)和“Not Play Cricket”(8 - 5 = 3)。
使用公式
ξ
=
(
A
c
t
u
a
l
–
E
x
p
e
c
t
e
d
)
2
E
x
p
e
c
t
e
d
\xi = \sqrt[]{(Actual – Expected)^2 \over Expected}
ξ=Expected(Actual–Expected)2计算“Play Cricket”和“Not Play Cricket”的节点的卡方值。 您可以参考下表进行计算。
按照类似的步骤计算Male节点的卡方值。
最后将所有的卡方值加起来计算出基于性别节点分裂的卡方值。

Decision_Tree_Chi_Square1.png
基于年级的分裂
步骤类似于上面基于性别的分类,详见下表

Decision_Tree_Chi_Square_2.png
上面,你可以看到,卡方值也识别出性别分裂比类别更显著。
信息增益(Information Gain)
观察下面的图像,并指出哪个节点可以很容易地描述。 我相信,你的答案是C,因为它需要较少的信息,因为所有的值都是类似的。 另一方面,B需要更多的信息来描述它,A需要最大的信息。 换句话说,我们可以说C是一个纯节点,B是不纯,A是更不纯。

Information_Gain_Decision_Tree2.png
现在,我们可以得出一个结论,一个样本拥有越少的不纯节点,描述这个样本所需的信息越少。而更多的不纯节点则需要更多的信息来描述。 信息论(Information Theory)采用“熵(Entropy)”来衡量一个系统的紊乱程度。如果样本完全均匀,则熵为零,如果样本是等分的(50%-50%),则熵为1。
熵的计算公式:
E
n
t
r
o
p
y
=
p
log
2
p
−
q
log
2
q
Entropy = p\log_2p-q\log_2q
Entropy=plog2p−qlog2q
这里p和q分别是该节点的成功和失败的概率。 熵也与分类目标变量一起使用。 它选择与父节点和其他分裂相比具有最低熵的分裂。 熵越小,它越好。
计算分割的熵的步骤:
计算父节点的熵
计算分割的每个单独节点的熵,并计算分割中可用的所有子节点的加权平均值。
例子
让我们使用这个方法来识别学生示例的最佳分裂。
父节点的熵=
15
30
log
2
15
30
−
15
30
log
2
15
30
=
1
{15\over30}\log_2{15\over30} - {15\over30}\log_2{15\over30}= 1
3015log23015−3015log23015=1.这里1示出它是不纯节点。
Female节点的熵为
2
10
log
2
2
10
−
8
10
log
2
8
10
=
0.72
{2\over10}\log_2{2\over10} - {8\over10}\log_2{8\over10}= 0.72
102log2102−108log2108=0.72,
对于Male节点,
13
20
log
2
13
20
–
7
20
log
2
7
20
=
0.93
{13\over20}\log_2{13\over20} – {7\over20}\log_2 {7\over20} = 0.93
2013log22013–207log2207=0.93
基于性别分割的熵=子节点的加权熵=
(
10
/
30
)
∗
0.72
+
(
20
/
30
)
∗
0.93
=
0.86
(10/30)* 0.72 +(20/30)* 0.93 = 0.86
(10/30)∗0.72+(20/30)∗0.93=0.86
"Class IX"节点的熵
6
14
log
2
6
14
−
8
14
log
2
8
14
=
0.99
{6\over14}\log_2{6\over14} - {8\over14}\log_2{8\over14}= 0.99
146log2146−148log2148=0.99,
对于"Class X"节点,
9
16
log
2
9
16
−
7
16
log
2
7
16
=
0.99
{9\over16}\log_2{9\over16} - {7\over16}\log_2{7\over16}= 0.99
169log2169−167log2167=0.99。
基于年级分裂的熵=子节点的加权熵=
(
14
/
30
)
∗
0.99
+
(
16
/
30
)
∗
0.99
=
0.99
(14/30)* 0.99 +(16/30)* 0.99 = 0.99
(14/30)∗0.99+(16/30)∗0.99=0.99
上面,你可以看到,在性别上分割的熵是最低的,所以树将在性别上分裂。 我们可以从熵中获取信息增益为1-熵。
方差缩减(Reduction in Variance)
到目前为止,我们已经讨论了分类目标变量的算法。 方差的减少是用于连续目标变量(回归问题)的算法。 该算法使用标准方差公式选择最佳分割。 选择具有较低方差的分割作为分割总体的标准:
方差公式
s
2
=
1
n
∑
i
=
1
n
(
x
i
−
x
‾
)
2
s2={\frac1n}\sum_{i=1}n(x_i-\overline{x})^2
s2=n1i=1∑n(xi−x)2
计算方差的步骤:
计算每个节点的方差。
每个节点方差的加权平均值作为分裂的方差值。
例子
我们把打板球赋值为1,不打板球赋值为0。 现在按照步骤确定正确的分割:
根节点的方差,这里的平均值是
(
15
∗
1
+
15
∗
0
)
/
30
=
0.5
(15 * 1 + 15 * 0)/ 30 = 0.5
(15∗1+15∗0)/30=0.5,我们有15个和15个零。现在方差将是
(
(
1
−
0.5
)
2
+
(
1
−
0.5
)
2
+
.
.
.
.
15
倍
+
(
0
−
0.5
)
2
+
(
0
−
0.5
)
2
+
.
.
.
15
倍
)
/
30
((1-0.5)^ 2 +(1-0.5)^ 2 + ... .15倍+(0-0.5)^ 2 +(0-0.5)^ 2 + ... 15倍)/ 30
((1−0.5)2+(1−0.5)2+....15倍+(0−0.5)2+(0−0.5)2+...15倍)/30, 被写为
(
15
∗
(
1
−
0.5
)
2
+
15
∗
(
0
−
0.5
)
2
)
/
30
=
0.25
(15 *(1-0.5)^ 2 + 15 *(0-0.5)^ 2)/ 30 = 0.25
(15∗(1−0.5)2+15∗(0−0.5)2)/30=0.25
女性节点的平均值为
(
2
∗
1
+
8
∗
0
)
/
10
=
0.2
(2 * 1 + 8 * 0)/10=0.2
(2∗1+8∗0)/10=0.2,方差为
(
2
∗
(
1
−
0.2
)
2
+
8
∗
(
0
−
0.2
)
2
)
/
10
=
0.16
(2 *(1-0.2)^ 2 + 8 *(0-0.2)^ 2)/ 10 = 0.16
(2∗(1−0.2)2+8∗(0−0.2)2)/10=0.16
男性节点的均值为
(
13
∗
1
+
7
∗
0
)
/
20
=
0.65
(13 * 1 + 7 * 0)/20=0.65
(13∗1+7∗0)/20=0.65,方差为
(
13
∗
(
1
−
0.65
)
2
+
7
∗
(
0
−
0.65
)
2
)
/
20
=
0.23
(13 *(1-0.65)^ 2 + 7 *(0-0.65)^ 2)/ 20 = 0.23
(13∗(1−0.65)2+7∗(0−0.65)2)/20=0.23
基于性别分裂的方差=子节点的加权方差=
(
10
/
30
)
∗
0.16
+
(
20
/
30
)
∗
0.23
=
0.21
(10/30)* 0.16 +(20/30)* 0.23 = 0.21
(10/30)∗0.16+(20/30)∗0.23=0.21
年级IX节点的平均值为
(
6
∗
1
+
8
∗
0
)
/
14
=
0.43
(6 * 1 + 8 * 0)/14=0.43
(6∗1+8∗0)/14=0.43,方差为
(
6
∗
(
1
−
0.43
)
2
+
8
∗
(
0
−
0.43
)
2
)
/
14
=
0.24
(6 *(1-0.43)^ 2 + 8 *(0-0.43)^ 2)/ 14 = 0.24
(6∗(1−0.43)2+8∗(0−0.43)2)/14=0.24
年级X节点的均值为
(
9
∗
1
+
7
∗
0
)
/
16
=
0.56
(9 * 1 + 7 * 0)/16=0.56
(9∗1+7∗0)/16=0.56且方差为
(
9
∗
(
1
−
0.56
)
2
+
7
∗
(
0
−
0.56
)
2
)
/
16
=
0.25
(9 *(1-0.56)^ 2 + 7 *(0-0.56)^ 2)/ 16 = 0.25
(9∗(1−0.56)2+7∗(0−0.56)2)/16=0.25
基于年级分裂的方差为
(
14
/
30
)
∗
0.24
+
(
16
/
30
)
∗
0.25
=
0.25
(14/30)* 0.24 +(16/30)* 0.25 = 0.25
(14/30)∗0.24+(16/30)∗0.25=0.25
上面,您可以看到,与父节点相比,性别拆分具有更低的方差,因此拆分将在Gender变量上进行。
在此之前,我们了解了决策树的基础知识,以及决策过程涉及在构建树模型中选择最佳分割。 正如我所说,决策树可以应用于回归和分类问题。 让我们来详细了解这些方面。
4.树模型的关键参数是什么?我们如何避免过度拟合的决策树?
过度拟合是决策树建模时面临的关键挑战之一。 如果没有决策树的限制集,它将给你100%的训练集精度,因为在最坏的情况下,它将最终为每个观察生成1个叶子节点。 因此,防止过拟合在对决策树建模时是关键的,并且可以以两种方式来完成:
设置树大小的约束
树修剪
让我们简要讨论这两个。
在树的大小上设置约束
这可以通过使用用于定义树的各种参数来完成。 首先,让我们看看决策树的一般结构:

tree-infographic.png
下面进一步解释用于定义树的参数。 以下描述的参数与工具无关。 重要的是要了解树模型中使用的参数的作用。 这些参数在R&Python中可用。
- 节点分割的最小样本(Minimum samples for a node split)
定义在要考虑分裂的节点中需要的样本(或观测)的最小数量。
用于控制过度拟合。较高的值会阻止模型学习可能对于为树选择的特定样本高度特别明确的关系。
太高的值可能导致欠拟合,因此应使用CV(变异系数)进行调整。 - 终端节点(叶)的最小样本(Minimum samples for a terminal node (leaf))
定义终端节点或叶子所需的最小样本(或观测值)。
用于控制过拟合,类似于min_samples_split。
通常,对于不平衡类问题应选择较低的值,因为其中少数类将在大多数地区将是非常小的。 - 树的最大深度(垂直深度)(Maximum depth of tree (vertical depth))
树的最大深度。
用于控制过拟合,因为较高的深度将允许模型学习对于特定样品的特定关系。
应使用CV调整。 - 终端节点的最大数量(Maximum number of terminal nodes)
树中的终端节点或叶子节点的最大数量。
可以定义为代替max_depth。由于创建了二叉树,因此深度“n”将产生最多 2 n 2 ^ n 2n个叶。 - 要考虑拆分的最大特征数(Maximum features to consider for split)
在搜索最佳分割时要考虑的要素数。这些将随机选择。
作为拇指规则,特征总数的平方根很好,但我们应该检查到特征总数的30-40%。
较高的值可能导致过拟合,但取决于具体情况。
树的修剪
如前所述,设置约束的技术是贪婪方法。 换句话说,它将立即检查最佳分离并向前移动,直到达到指定的停止条件之一。 让我们考虑以下情况当你开车:

graphic-1024x317.png
这里2个车道:
汽车以80公里/小时的速度行驶
卡车以30公里/小时的速度行驶的车道
在这个时刻,你是黄色的车,你有两个选择:
左转,快速超过其他2辆车
继续在当前车道移动
让我们分析这些选择。 在前一种选择中,您将立即超车,然后到达卡车后面,以30公里/小时的速度开始移动,寻找机会向右移动。 原来在你身后的所有车辆同时向前移动。 这将是最佳的选择,如果你的目标是在下一个10秒覆盖最大的距离。 在后面一个 选择中,你以相同的速度前行,赶上卡车,然后超过,可能取决于前面的情况。 你好贪心!
这正是正常决策树和修剪之间的区别。具有约束的决策树将不会看到前面的卡车,并采取贪婪的方法左转。 另一方面,如果我们使用修剪,我们实际上会看前面几步,并做出选择。
所以我们知道修剪是更好的。 但是如何在决策树中实现它呢? 这个想法很简单。
我们首先将决策树做得很深。
然后我们从底部开始,并开始删除那些和顶部相比给我们负回报的叶子。
假设一次分裂给我们一个增益-10(损失10),然后下一个分裂给我们一个增益20.一个简单的决策树将停止在步骤1,但在修剪,我们将看到整体 增益是+10并保留两个叶。
注意sklearn的决策树分类器目前不支持修剪。 高级包像xgboost在它们的功能中已经采用了树修剪。 但是R中rpart包,提供了一个修剪的函数。 对于R用户自然是极好的!
5. 基于树的模型是否比线性模型好?
“如果我可以对分类问题使用逻辑回归和对回归问题使用线性回归,为什么要使用树”? 我们许多人都有这个问题。 而且,这也是一个有效的问题。
实际上,你可以使用任何算法。 它取决于你解决的问题的类型。 让我们来看看一些关键因素,它们将帮助你决定使用哪种算法:
如果因变量和自变量之间的关系通过线性模型很好地近似,则线性回归将优于基于树的模型。
如果因变量和自变量之间存在高的非线性和复杂关系,则树模型将优于经典的回归方法。
如果你需要构建一个易于向人们解释的模型,那么决策树模型将总是比线性模型更好。 决策树模型甚至比线性回归更容易解释!
6. 在R和Python中实现决策树算法
对于R用户和Python用户,决策树很容易实现。 让我们快速看看可以让你开始使用这个算法的代码集。 为了便于使用,我共享了标准代码,您需要替换您的数据集名称和变量以开始使用。
对于R用户,有多个包可用于实现决策树,如ctree,rpart,tree等。

在上面的代码中:
y_train - 表示因变量。
x_train - 表示自变量
x - 表示训练数据。
对于Python用户,下面是代码:
7. 什么是基于树建模的集成方法(Ensemble methods)?
词语“ensemble”的文学意义是群体。 集成方法涉及预测模型组,以实现更好的准确性和模型稳定性。 已知集成方法对基于树的模型赋予了极大的提升。
像所有其他模型一样,基于树的模型也遭受偏差和方差的影响。 偏差意味着“预测值与实际值存在多大程度的差异”。方差意味着,如果不同的样本是从同一个总体中获取的,模型的预测值与总体存在多大差异。
你建立一个小树,你会得到一个低方差和高偏差的模型。 你如何设法找到偏差和方差之间的折衷方案?
通常,当您增加模型的复杂性时,由于模型中的偏差较小,您将看到预测误差的减少。 随着你继续让你的模型更复杂,你最终会过度拟合你的模型,你的模型将开始遭受高方差。
一个冠军模型应该保持这两种类型的错误之间的平衡。 这被称为偏差方差误差的权衡管理。 集成学习是执行这种权衡分析的一种方式。

model_complexity.png
一些常用的集成方法包括:装袋,拉动和堆积(Bagging, Boosting and Stacking)。 在本教程中,我们将详细介绍Bagging和Boosting。
8. 什么是Bagging? 它是如何工作的?
Bagging是一种用于通过组合对相同数据集的不同子样本建模的多个分类器的结果来减少我们的预测的方差的技术。 下图将使其更清楚:

bagging.png
装袋中的步骤是:
创建多个DataSet:
通过对原始数据进行替换来完成采样,并形成新的数据集。
新数据集可以具有列的一部分列以及行,其在装袋模型中通常是超参数
取的行和列的级分小于1有助于使可靠的模型,不易发生过度拟合
构建多个分类器:
分类器建立在每个数据集上。
通常,对每个数据集建模相同的分类器,并进行预测。
组合分类器:
所有的分类器的预测是根据手头问题使用的均值,中位数或众数值相结合。
组合值通常比单个模型更鲁棒。
注意,这里建立的模型数量不是超参数。 较高数量的模型总是更好,或者可以给出与较低数字类似的性能。 在理论上可以表明,在某些假设下,组合预测的方差减小到原始方差的1 / n(n:分类器的数量)。
装袋模型有各种实现。 随机森林是其中之一,我们将在下面讨论它。
9. 什么是随机森林? 它是如何工作的?
随机森林被认为是所有数据科学问题的灵丹妙药。 在一个有趣的信条,当你想不出任何算法(不论任何情况),使用随机森林!
随机森林是一种多功能机器学习方法,能够执行回归和分类任务。 它还采用降维方法,处理缺失值,异常值和数据探索的其他必要步骤,并且做得相当不错。 它是一种集成学习方法,一组弱模型组合形成一个强大的模型。
它是如何工作的
在随机森林中,我们在CART模型中生成多棵树,而不是单棵树(参见CART和Random Forest之间的比较,第1部分和第2部分)。 为了基于属性对新对象进行分类,每个树给出一个分类,并且我们说给该树的“投票”。 森林选择具有最多票数(在森林中的所有树上)的分类,并且在回归的情况下,它取不同树的输出的平均值。
它以以下方式工作。 每棵树种植和种植如下:
假设在训练集中样本的数量为N.然后,这N个样本中下,随机取样(可放回)。 该样本将是用于生长树的训练集。
如果存在M个输入变量,则指定数目m <M,使得在每个节点处,从M中随机选择m个变量。m个变量中最佳的分裂将用于分裂节点。当森林成长时,m的值保持不变。
如果存在M个输入变量,则指定数目m <M,使得在每个节点处,从M中随机选择m个变量。m个变量中最佳的分裂将用于分裂节点。当森林成长时,m的值保持不变。
每棵树都生长到尽可能最大的程度,没有修剪。
通过聚合n棵树的预测值(即,用于分类的多数票,平均值用于回归)来预测新数据。


all-data-set-850x751.jpg
要了解更多关于此算法使用案例研究,请阅读这篇文章随机森林简介 - 简化。
随机森林的优点
这种算法可以解决两种类型的问题,即分类和回归,并在两个方面做出合理的估计。
随机森林一个这让我兴奋的好处就是,具有较高的维度设置处理大量数据的能力。它可以处理数千个输入变量并识别最重要的变量,因此它被认为是降维方法之一。 此外,模型输出变量的重要性,其可以是非常方便的特征(在一些随机数据集上)。
它具有估计丢失数据的有效方法,并且当大部分数据丢失时保持精度。
它具有用于平衡类不平衡的数据集中的错误的方法。
上述的能力可以扩展到未标记的数据,导致无监督的聚类,数据视图和异常值检测。
随机森林涉及对输入数据的采样,称为自举采样。 这里三分之一的数据不用于训练,可用于测试。 这些称为袋外取样。 对这些出袋样本估计的误差被称为出袋误差。 通过Out of bag进行误差估计的研究,证明了out-of-bag估计与使用与训练集相同大小的测试集是准确的。 因此,使用袋外误差估计消除了对预留测试集的需要。

Variable_Important.png
随机森林的缺点
它确实在分类方面做得很好,但不如回归问题好,因为它不提供精确的连续自然预测。 在回归的情况下,它不预测超出在训练数据的范围内的数据,并且它们会对噪声特别大的数据集产生过拟合。
随机森林可以觉得自己像一个黑盒子的方法进行统计建模 - 您对模型做什么很难控制。 你最好能 - 尝试不同的参数和随机种子!
Python&R实现
随机森林通常在R包和Python scikit-learn中的实现。 让我们看看下面的R和Python中加载随机森林模型的代码:
Python

R Code
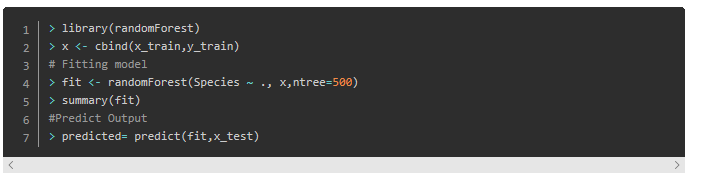
10.什么是Boosting? 它是如何工作的?
定义:术语“Boosting”是指将弱学习者转化为强大学习者的算法家族。
让我们通过解决垃圾邮件识别问题来详细了解这个定义:
您如何将电子邮件分类为垃圾邮件? 和其他人一样,我们的初始方法是使用以下标准来识别“垃圾邮件”和“非垃圾邮件”电子邮件。 如果:
电子邮件只有一个图片文件(促销图片),这是一个垃圾邮件
电子邮件只有链接,这是一个垃圾邮件
电子邮件正文包括“你赢得$ xxxxxx的奖金”这句话,这是一个垃圾邮件
电子邮件从我们的官方域“Analyticsvidhya.com”,而不是垃圾邮件
电子邮件来自已知来源,不是垃圾邮件
以上,我们定义了多个规则,将电子邮件分为“垃圾邮件”或“非垃圾邮件”。 但是,你认为这些规则是否足够强大以成功分类电子邮件? 没有。
个别地,这些规则不足以将电子邮件分类为“垃圾邮件”或“非垃圾邮件”。 因此,这些规则被称为弱学习者。
为了将弱学习者转换为强学习者,我们将使用以下方法来组合每个弱学习者的预测:
使用平均/加权平均
考虑有更高投票的预测
例如:上面,我们定义了5个弱学习者。 在这5个中,3个被表决为“垃圾邮件”,2个被表决为“不是垃圾邮件”。 在这种情况下,默认情况下,我们会将电子邮件视为垃圾邮件,因为我们对“垃圾邮件”投票较高(3)。
它是如何工作的?
现在我们知道,“Boosting"结合弱学习者和基础学习者形成一个强大的规则。 在你心目中应该浮现的一个直接的问题是,“Boosting是如何识别弱规则的?”
为了找到弱规则,我们应用具有不同分布的基础学习(ML)算法。每应用一次基础学习算法,它就会生成新的弱预测规则。 这是一个迭代过程。 在许多迭代之后,增强算法将这些弱规则组合成单个强预测规则。
另一个可能困扰你的问题是,“我们如何为每轮选择不同的分布?”
为了选择正确的分布,请执行以下步骤:
步骤1:基础学习者获取所有分布,并给每个观察分配相等的权重或关注。
步骤2:如果存在由第一个基础学习算法引起的任何预测误差,则我们更加注意具有预测误差的观测。 然后,我们应用下一个基本学习算法。
步骤3:迭代步骤2,直到达到基础学习算法的极限或达到更高的精度。
最后,它结合了弱学习者的输出,并创建了一个强大的学习者,最终提高了模型的预测能力。 Boosting通过前面的弱规则更加关注错误分类或具有更高错误的示例。
有许多增强算法给予模型的精度额外的提升。 在本教程中,我们将了解两种最常用的算法,即Gradient Boosting(GBM)和XGboost。
11. 哪个更强大:GBM或Xgboost?
我一直很欣赏的xgboost算法增强能力。有时,我发现它比起GBM实现了较好的效果,但有时,你可能会发现,收益只是微不足道的。 当我探索更多关于它的性能和科学背后的高精确度后,我发现了Xgboost相比GBM的更多优点:
正则化:
标准的GBM算法没有像XGBoost那样实现正则化,因此其也有助于减少过度拟合。
事实上,XGBoost也被称为“正则化提升”技术。
并行处理:
XGBoost能够实现并行处理,并且比GBM快得多。
但需要强调的是,我们知道,Boosting是一个连续的过程,那么怎么才能实现并行呢? 我们知道每个树只能在前一个树之后才能构建,所以是什么阻止了我们使用所有的核心生成树?我希望你能得到我来自的地方。 检查此链接,进一步探索。
XGBoost还支持在Hadoop上实现。
高灵活性
XGBoost允许用户定义自定义优化目标和评估标准。
这为模型增加了一个全新的维度,我们可以做的没有限制。
处理缺少的值
XGBoost有一个内置的程序来处理缺失值。
用户需要提供与其他观测值不同的值,并将其作为参数传递。 XGBoost尝试不同的东西,因为它遇到每个节点上的缺失值,并了解将来丢失值采用哪个路径。
修剪树:
当分裂中遇到负损失时,GBM将停止分裂节点。 因此,它更多是贪婪算法。
另一方面,XGBoost将秩序分裂直到达到max_depth,然后开始向后修剪树,并删除没有正增益的分裂。
另一个优点是有时负损失为-2的分裂可能跟随着正损失为+10的分裂。 GBM将在遇到-2时停止。 但XGBoost会更深入,因为它会看到两者的组合效果产生的+8的分裂。
内置交叉验证
XGBoost允许用户在Boosting过程的每次迭代时运行交叉验证,因此很容易在单次运行中获得精确的最佳Boosting迭代次数。
这不像GBM,我们必须运行网格搜索,只有有限的值可以测试。
在现有模型上继续运行
用户可以从上次运行的最后一次迭代开始训练XGBoost模型。 这在某些特定应用中会是特别显著的优点。
sklearn中的GBM实现了这个功能,所以在这一点上他们是相同的。
12. 在R和Python中使用GBM
在我们开始工作之前,让我们快速了解这个算法的重要参数和工作原理。 这将有助于R和Python用户。 下面是GBM算法的2个类的总体伪代码:
- Initialize the outcome
- Iterate from 1 to total number of trees
2.1 Update the weights for targets based on previous run (higher for the ones mis-classified)
2.2 Fit the model on selected subsample of data
2.3 Make predictions on the full set of observations
2.4 Update the output with current results taking into account the learning rate - Return the final output.
这是一个非常简化(可能天真)的GBM的工作原理的解释。 但是,它将帮助每个初学者了解这种算法。
让我们考虑用来改进Python中模型性能的重要GBM参数:
learning_rate
这决定了每棵树对最终结果的影响(步骤2.4)。 GBM从使用每个树的输出更新的初始估计开始工作。 学习参数控制估计中的这种变化的大小。
较低的值通常是优选的,因为它们使模型稳健树的具体特征,从而允许它概括很好。
较低的值将需要较大数量的树来建模所有关系,并且计算上将是昂贵的。
n_estimators
要建模的顺序树的数量(步骤2)
虽然GBM在较高数量的树木是相当健壮,但它仍然可以在一个点过度拟合。 因此,这应该使用CV对特定的学习率进行调整。
subsample
要为每个树选择的观测值的分数。 通过随机抽样进行选择。
小于1的值通过减少方差使模型鲁棒。
典型值〜0.8通常工作正常,但可以进一步微调。
除此之外,还有一些影响整体功能的杂项参数:
loss
它指的是在每个分裂中最小化的损失函数。
它可以具有用于分类和回归情况的各种值。一般默认值工作正常。只有在您了解其对模型的影响时,才应选择其他值。
init
这会影响输出的初始化。
如果我们制定了另一个模型,其结果将被用作GBM的初始估计,则可以使用该模型。
random_state
随机数种子,使得每次都生成相同的随机数。
这对于参数调整很重要。如果我们不固定随机数,则对于相同参数的后续运行时,我们将会看到不同的结果,使得模型变得难以比较。
它可能潜在地使一个所选择的特定随机样本产生过拟合。我们可以尝试运行不同随机样本的模型,这是计算昂贵的,通常不使用。
verbose
当模型拟合时要打印的输出类型。不同的值可以是:
0:无输出生成(默认)
1:以一定间隔为树生成的输出
1:为所有树生成输出
warm_start
这个参数有一个有趣的应用程序,可以帮助很多,如果使用得当。
使用这个,我们可以在模型的先前拟合中拟合额外的树。它可以节省大量的时间,你应该为高级应用程序探索这个选项
presort
选择是否预分类数据以实现更快的分割。
默认情况下会自动进行选择,但如果需要可以更改。
我知道它的一个长列表的参数,但我已经简化了它在一个excel文件,你可以从这个GitHub存储库下载。
对于R用户,使用caret包,有3个主要调整参数:
n.trees
它指的是迭代次数,即将用来生长树的树
interaction.depth
它确定树的复杂性,即它必须在树上执行的分割的总数(从单个节点开始)
shrinkage
指学习率。这类似于python中的learning_rate(如上所示)。
n.minobsinnode
它指的是节点执行拆分所需的训练样本的最小数量
R中的GBM(带交叉验证)
我已经共享了R和Python中的标准代码。 最后,您需要更改下面代码中使用的因变量和数据集名称的值。 考虑到在R中实现GBM的容易性,可以容易地执行诸如交叉验证和网格搜索这样的任务。
library(caret)
fitControl <- trainControl(method = “cv”,
number = 10, #5folds)
tune_Grid <- expand.grid(interaction.depth = 2,
n.trees = 500,
shrinkage = 0.1,
n.minobsinnode = 10)
set.seed(825)
fit <- train(y_train ~ ., data = train,
method = “gbm”,
trControl = fitControl,
verbose = FALSE,
tuneGrid = gbmGrid)
predicted= predict(fit,test,type= “prob”)[,2]
GBM in Python
#import libraries
from sklearn.ensemble import GradientBoostingClassifier #For Classification
from sklearn.ensemble import GradientBoostingRegressor #For Regression
#use GBM function
clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1)
clf.fit(X_train, y_train)
- 在R和Python中使用XGBoost
XGBoost(eXtreme Gradient Boosting)是梯度提升算法的高级实现。 它的功能是实现并行计算,使其至少比现有的梯度提升实现快10倍。 它支持多种目标函数,包括回归,分类和排名。
R教程:对于R用户,这是一个完整的教程XGboost,解释参数和代码在R.检查教程。
Python教程:对于Python用户,这是一个关于XGBoost的综合教程,很好地帮助您入门。 检查教程。
14.在哪里练习?
实践是掌握任何概念的一个真正的方法。 因此,如果你想掌握这些算法,你需要开始练习。
到这里,你已经获得了有关树基模型的重要知识以及这些实际实现。 现在是时候开始工作。 这里是开放的练习问题,你可以参加和检查您的排行榜上的实时排名:
回归:大市场销售预测
分类:贷款预测
结束注释
基于树的算法对于每个数据科学家都很重要。 事实上,已知树模型在整个机器学习算法族中提供最好的模型性能。 在本教程中,我们学会了直到GBM和XGBoost。 有了这个,我们来到本教程的结尾。
我们讨论了从头开始的基于树的建模。 我们学习了决策树的重要性,以及如何使用这种简单化的概念来提升算法。 为了更好地理解,我建议你继续实践这些算法。 此外,请记住与提升算法相关的参数。 我希望这个教程将丰富你有关树基建模的完整知识。
您觉得本教程很有用吗? 如果你有经验,你使用树的模型最好的技巧是什么? 请随时在下面的评论部分分享您的技巧,建议和意见。
作者:珞珈村下山
链接:https://www.jianshu.com/p/ff9b7b031fed
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。















 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









