







 日志管理类的后台线程分布式存储系统除了要保证客户端写请求流程的正确性,节点可能会非正常宕机或者需要重启,在启动的时候必须要能够正常地加载/恢复已有的数据,日志管理类在创建的时候要加载已有的所有日志文件,这和创建Log时要加载所有的Segment是类似的。LogManager的logDirs参数对应了log.dirs配置项,每个TopicPartition文件夹都对应一个Log实例,所有的Parti...
日志管理类的后台线程分布式存储系统除了要保证客户端写请求流程的正确性,节点可能会非正常宕机或者需要重启,在启动的时候必须要能够正常地加载/恢复已有的数据,日志管理类在创建的时候要加载已有的所有日志文件,这和创建Log时要加载所有的Segment是类似的。LogManager的logDirs参数对应了log.dirs配置项,每个TopicPartition文件夹都对应一个Log实例,所有的Parti...
日志管理类的后台线程
分布式存储系统除了要保证客户端写请求流程的正确性,节点可能会非正常宕机或者需要重启,在启动的时候必须要能够正常地加载/恢复已有的数据,日志管理类在创建的时候要加载已有的所有日志文件,这和创建Log时要加载所有的Segment是类似的。LogManager的logDirs参数对应了log.dirs配置项,每个TopicPartition文件夹都对应一个Log实例,所有的Partition文件夹都在日志目录下,当成功加载完所有的Log实例后logs才可以被日志管理类真正地用在战场上。
假设logDirs=/tmp/kafka_logs1,/tmp/kafka_logs2,logs1下有[t0-0,t0-1,t1-2],logs2下有[t0-2,t1-0,t1-1],图3-26的logDir指的是Log对象的dir,和log.dirs是不同的概念,可以认为所有Log的dir都是在每个log.dirs下,如果把Log.dir叫做Partition级别的文件夹,则checkpoint文件和Partition文件夹是同一层级。
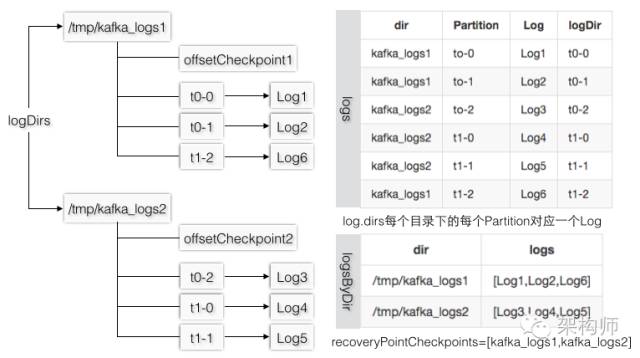
图3-26 日志的组织方式和对应的数据结构
class LogManager(val logDirs: Array[File]){
val logs = new Pool[TopicAndPartition, Log]()
val recoveryPointCheckpoints=logDirs.map((_,new OffsetCheckpoint(new File(_,"checkpoint"))))
loadLogs() //启动LogManager实例时,如果已经存在日志文件,要把它们加载到内存中
private def loadLogs(): Unit = {
val threadPools = mutable.ArrayBuffer.empty[ExecutorService]
for (dir <- this.logDirs) { //按照log.dirs创建线程池,如果只配置一个目录就只有一个线程池
val pool = Executors.newFixedThreadPool(ioThreads)
threadPools.append(pool)
/eckpoint文件一个日志目录只有一个,并不是每个Partition级别!
//既然所有Partition公共一个checkpoint文件,那么文件内容当然要有Partition信息
var recoveryPoints:Map[TopicAndPartition,Long]=recoveryPointCheckpoints(dir).read
val jobsForDir = for {
dirContent <- Option(dir.listFiles).toList //日志目录下的所有文件/文件夹
logDir <- dirContent if logDir.isDirectory //Partition文件夹,忽略日志目录下的文件
} yield {
CoreUtils.runnable { //每个Partition文件夹创建一个线程,由线程池执行
val topicPartition = Log.parseTopicPartitionName(logDir)
val config = topicConfigs.getOrElse(topicPartition.topic, defaultConfig)
val logRecoveryPoint = recoveryPoints.getOrElse(topicPartition, 0L) //分区的恢复点
val current = new Log(logDir, config, logRecoveryPoint, scheduler, time) //恢复Log
this.logs.put(topicPartition, current) //这里放入logs集合中,所有分区的Log满血复活
}
}
jobsForDir.map(pool.submit).toSeq //提交任务
}
}
//只有调用loadLogs后,logs才有值,后面的操作都依赖于logs
def all
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1564
1564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











