









学习了机器学习实战第五章
这一章用到了最优化方法中的梯度上升法,简单说,梯度上升法基于函数的单调性,我们如果想求得函数的极值,就可以让自变量根据梯度的方向进行变化,这样根据函数的单调性可以保证变化的方向正确而且可以保证效率最高,因为梯度指示的方向相当于山脊的方向,沿梯度方向函数变化是最快的。
以本算法为例,目标函数是
error=classLabel−h
要求error的绝对值最小,其中
h=sigmoid(weights∗dataMat)
激活函数 sigmoid()
sigmoid(x)=1/(1−exp(−x))
梯度上升法本质是通过梯度联系自变量与因变量,使得自变量的变化能定向的改变因变量。这里我们讨论error的大小与回归系数weights的关系,自变量事实上是weights,因变量是error,我们将自变量weights结合error的大小进行变化(error的作用与梯度类似)可以使得因变量error绝对值最小化;例如,若error>0,则weights变大,由于error与weights成反比,所以error变小,即趋近于0,绝对值变小;若error<0,则weights变小,导致下次迭代后error变大,即error绝对值变小。∴该迭代结果是使error的绝对值最小化
weights=weights+alpha∗error∗dataMat
gradAscent
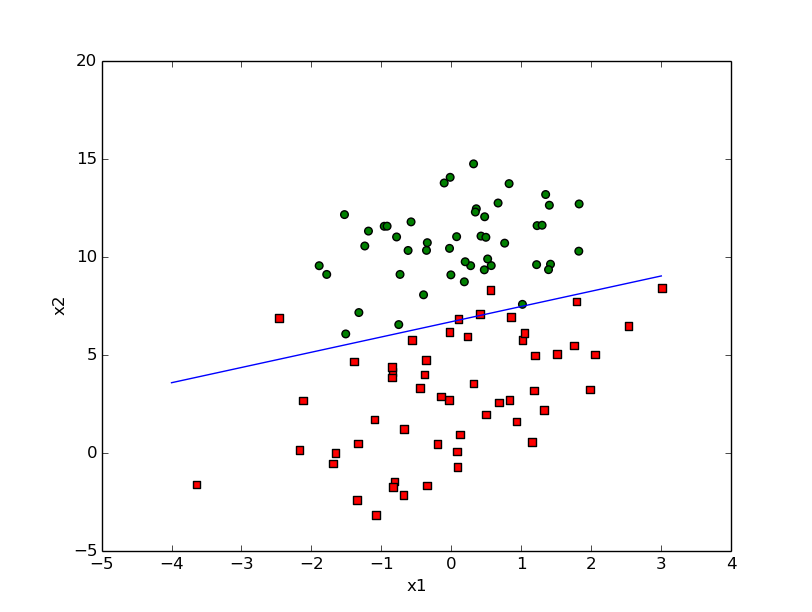
stocGradAscent
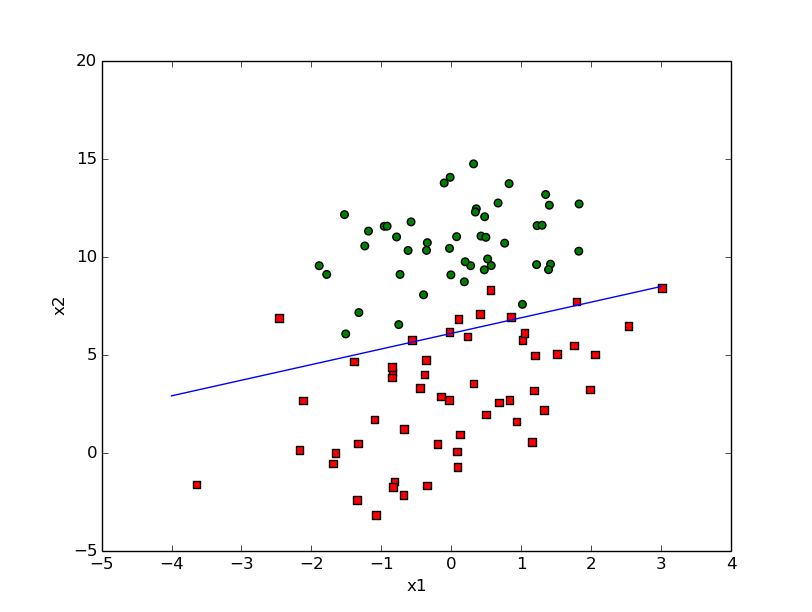
stocGradAscent1_iter=5
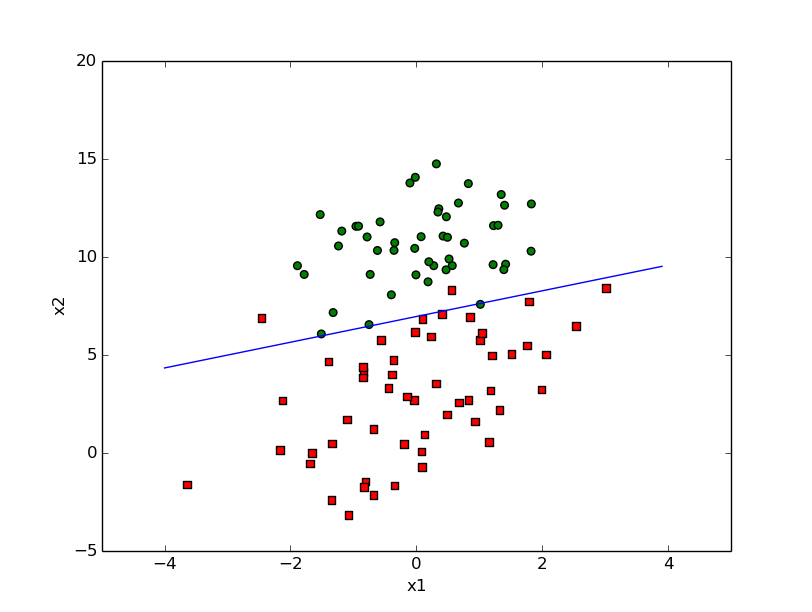
stocGradAscent1_iter=150
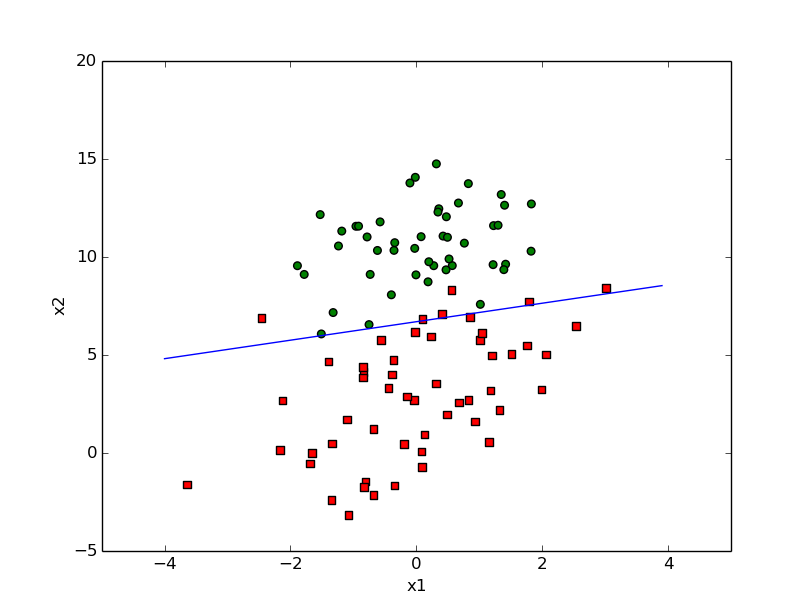
stocGradAscent1_iter=500
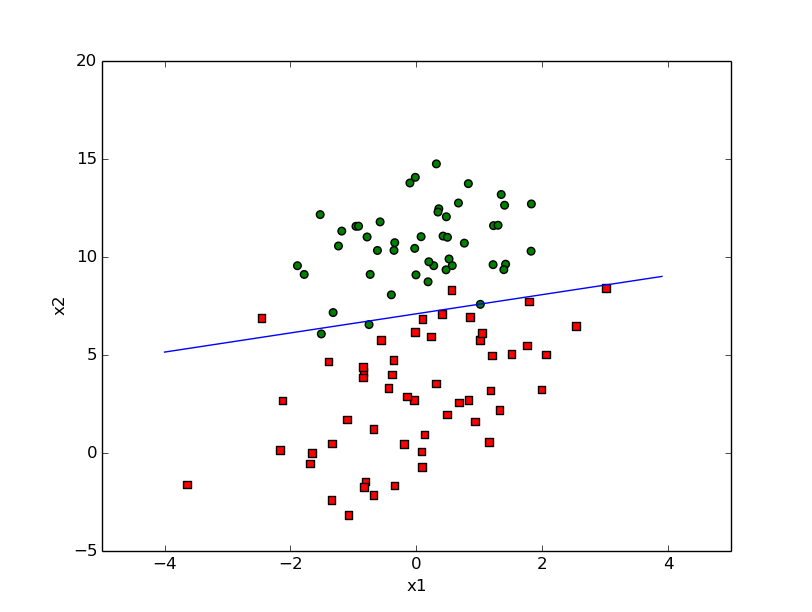
# -*- coding: utf-8 -*-
from numpy import *
def loadDataSet():
dataMat=[];labelMat=[]
fr=open('testSet.txt')
for line in fr.readlines():
line=line.strip().split()
dataMat.append([1.0,float(line[0]),float(line[1])])
labelMat.append(int(line[2]))###注意int不能缺少,否则会导致后续的计算时label中
return dataMat,labelMat #的数值不是int,不能进行代数运算
def sigmoid(x):
return 1.0/(1+exp(-x))
#最简单直接的梯度上升法
def gradAscent(dataMatIn,classLabels):
dataMatrix=mat(dataMatIn);labelList=mat(classLabels).transpose()
m,n=shape(dataMatIn)
weights=ones([n,1])
alpha=0.001
maxCycle=500
error=mat([m,1])
for i in xrange(maxCycle):
h=sigmoid(dataMatrix*weights)#h:[m,n]*[n,1]=[m,1]
#print type(h),h[0,0],labelList[0,0]
error= labelList-h#labelList:[m,1]
weights=weights+alpha*dataMatrix.transpose()*error
print type(weights)
return weights
#随机梯度上升,将训练样本一个个输入,相当于减少了迭代的次数,因此需要多次重复
def stocGradAscent(dataMatIn,classLabels):
m,n=shape(dataMatIn)
weights=ones(n)
alpha=0.001
for j in xrange(200):#多次重复迭代过程
for i in xrange(m):
h=sigmoid(sum(dataMatIn[i]*weights))
error=classLabels[i]-h
weights=weights+alpha*error*array(dataMatIn[i])
###上面要加上array(),因为dataMatIn是list类型,
#n*list类型表示将list重复n次生成新的list,而不表示array等的运算操作,
#只有array和mat与int或者float类型相乘才表示代数运算
#print weights
return weights
####改进的随机梯度上升,上一个所谓的随机梯度上升貌似并没有出现随机,由于其迭代过程中
#进行训练的元素是周期循环使用的,所以会造成一定的周期性的波动,可参见机器学习实战5-6图
#为了减少这种周期性的波动,我们利用随机的方法,随机选择每次的训练元素,这样类似于第四章中的
#留存交叉验证,利用随机减少结果的波动,加快迭代的速率,减少迭代的次数
#同时,使用变化的alpha,使其不严格下降,这样保证多次迭代后的新数据仍哟一定的影响
#这也常用于模拟退火算法
def stocGradAscent1(dataMatIn,classLabels,numIter=150):
dataMat=dataMatIn
m,n= shape(dataMat)
weights=ones(n)
for i in xrange(numIter):
dataInx=range(m)#注意这句,每次迭代结束后都将数据的下标回复完整
#保证了每个循环中所有数据都被使用了一次,同时改变训练数据的录入顺序,所谓随机
for j in xrange(m):
alpha=4/(i+j+1.0)+0.01
randInx=int(random.uniform(0,len(dataInx)))#注意理解这句中的dataInx
h=sigmoid(sum(dataMat[randInx]*weights))
error=classLabels[randInx]-h
weights=weights+alpha*error*array(dataMat[randInx])
del(dataInx[randInx])#删除dataInx中下标为randInx的元素,此时的被删除的值不一定等于randInx,
#这样做是为了打乱训练数据录入的顺序,但是又保证了在一次循环训练中所有的数据都被录入了一次
return weights
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()
dataArr=array(dataMat)
n=shape(dataArr)[0]
xcord1=[];ycord1=[]
xcord2=[];ycord2=[]
for i in xrange(n):
if int(labelMat[i])==1:
xcord1.append(dataArr[i,1]);ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]);ycord2.append(dataArr[i,2])
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(xcord1,ycord1,s=30,c='red',marker='s')
ax.scatter(xcord2,ycord2,s=30,c='green')
x=arange(-4.0,4.0,0.1)
#print type(x)
#print x
##试着理解为什么要画w0x0+w1x1+w2x2=0这条直线:因为根据算法的激活函数sigmoid,
#测试时当sigmoid函数结果>0.5时认为是1类型,此时对应的情况是w0x0+w1x1+w2x2<0;
#当sigmoid函数结果<0.5时为0型,此时对应的w0x0+w1x1+w2x2>0,也就是当以sigmoid
#是否大于0.5为分类规则时,就等同于将原始数据按照直线w0x0+w1x1+w2x2=0分类
#这里是一种思想,即将线性函数的值映射到非线性函数上,得到结果的二值化等结果
y=(-1*float(weights[0])-float(weights[1])*x)/float(weights[2])
#注意加上float否则weights中的元素可能不是数值型,无法代数运算
ax.plot(x,y)
plt.xlabel('x1');plt.ylabel('x2')
plt.show()testLogisticRegress:
import logisticRegress as lr
dataMat,labelMat=lr.loadDataSet()
weights=lr.stocGradAscent1(dataMat,labelMat,2000)
#weights=lr.stocGradAscent(dataMat,labelMat)
#weights=lr.gradAscent(dataMat,labelMat)
lr.plotBestFit(weights)














 384
384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









