







模型融合
1.将队友写好的模型代码放入django文件夹中:(如下),并在view文件中进行调用
界面的调整
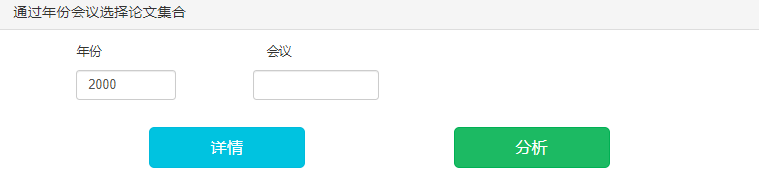
1.可选择只输入年份/会议来获得详情和分析结果:
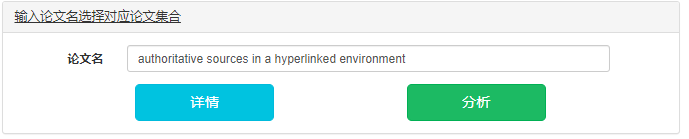
详情(展示的是满足条件的论文名,一行一个):

分析:(这里由于模型还有一点问题,训练速度慢,所以暂时用一些数据代替)

2.同理完善下面的选项:
出现的错误
1.路径不对:(需要将队友的所有文件的路径进行修改使之满足django运行)

修改如下:(举例)

2.运行速度慢,很久都不能显示结果,经过在本地运行模型,发现出现结果也很慢,所以需要队友进行改进。
代码:
(此处只列举一个,其他类似)
def paper_detail(request, paper_id): # 显示一篇论文的详细内容(存到数据库中的)
paper = Paper.objects.get(articals=paper_id)
context = {
'articals': paper.articals,
'authors ': paper.authors,
'abstracts': paper.abstracts,
'affiliations': paper.affiliations,
'IndexTerms ': paper.IndexTerms,
'keywords': paper.keywords,
'nodes': paper.nodes,
'inlinks': paper.inlinks,
'outlinks': paper.outlinks,
'GeneralTerms': paper.GeneralTerms,
}
return render(request, 'choose_paper/paper_example.html', context)
def function(request): # 根据会议和年份筛选数据集合
if request.POST:
if 'paper_set' in request.POST:
year = request.POST['datetimepicker']
venue = request.POST['venue']
articals = []
with open("choose_paper/data/id_year_venue.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
i = 0
while i < len(lines)-3:
a = lines[i].strip()
b = lines[i+1].strip()
c = lines[i+2].strip()
if year == "":
if(c == venue):
articals.append(a)
i += 4
elif venue == "":
if(b == year):
articals.append(a)
i += 4
else:
if(b == year and c == venue):
articals.append(a)
i += 4
name=[]
#找论文名称
with open('choose_paper/data/nodes2.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
for i in range(len(articals)):
for j in range(len(lines)):
line=lines[j].split()
if(line[0]==articals[i]):
s=""
for m in range(1,len(line)):
s=s+line[m]
s=s+" "
name.append(s)
break
context = {
'nodes': name # 获取满足年份,会议的论文id
}
return render(request, 'choose_paper/yv_paper.html', context)
else:
year = request.POST['datetimepicker']
venue = request.POST['venue']
articals = []
with open("choose_paper/data/id_year_venue.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
i = 0
while i < len(lines)-3:
a = lines[i].strip()
b = lines[i+1].strip()
c = lines[i+2].strip()
if year == "":
if(c == venue):
articals.append(a)
i += 4
elif venue == "":
if(b == year):
articals.append(a)
i += 4
else:
if(b == year and c == venue):
articals.append(a)
i += 4
SubSpace0_dict = np.load(
'choose_paper/PaperCompare/data_process_result/SubSpace0_dict.npy').item()
SubSpace1_dict = np.load(
'choose_paper/PaperCompare/data_process_result/SubSpace1_dict.npy').item()
SubSpace2_dict = np.load(
'choose_paper/PaperCompare/data_process_result/SubSpace2_dict.npy').item()
SubSpace3_dict = np.load(
'choose_paper/PaperCompare/data_process_result/SubSpace3_dict.npy').item()
SubSpace4_dict = np.load(
'choose_paper/PaperCompare/data_process_result/SubSpace4_dict.npy').item()
hh = [102, 114, 156, 157, 164, 171, 172, 173, 174, 175, 177,
190, 191, 192, 193, 195, 205, 206, 207, 230, 262, 263]
# finalresult = predmodel(
# "choose_paper/PaperCompare/model/model0.h5", hh, SubSpace0_dict)
context = {
'研究背景': hh, # 获取满足年份,会议的论文id
'研究问题': hh,
'贡献': hh,
'方法': hh,
'实验': hh
}
return render(request, 'choose_paper/setpaper.html', context)
上述内容详见:
https://blog.csdn.net/qq_41798302/article/details/106912062















 7596
7596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









