






动手学CV-Pytorch计算机视觉 ConditionGAN实战: 再战手写数字生成
在实现传统的GAN网络时,我们是不是会有这样的一个困惑,为什么模型的输入是从一个简单的分布(高斯分布)中随机抽样出来的一个张量,能不能加上人为控制的因素呢。比如我们想在生成新图像的时候,让Generator能按照用户输入的文字或者图片要求,产生出指定需求的图片。而这正是我们接下来所要介绍的:CGAN(条件生成式对抗网络)。
5.3.1 CGAN实现的问题
下面我们来举一个好玩的从文本生成图像例子:
假设我们在模型的输入中传入一段文本:“red eyes”,记作$label$,通过embedding技术将文本编码成文本张量
c
c
c,而Generator所作的就是将**输入的文本张量$c$和一个从标准正态分布中抽样出的张量$z$**一起吃掉,吐出一张图片$x$,对于$x$,它需要满足以下两个要求:
$y$是尽可能真实的动漫人物图片。$y$的特征要符合输入的文本要求,比如"red eyes"。
由于
z
z
z是随机抽样的,因此同一个$c$,可以生成多张满足要求的$x$
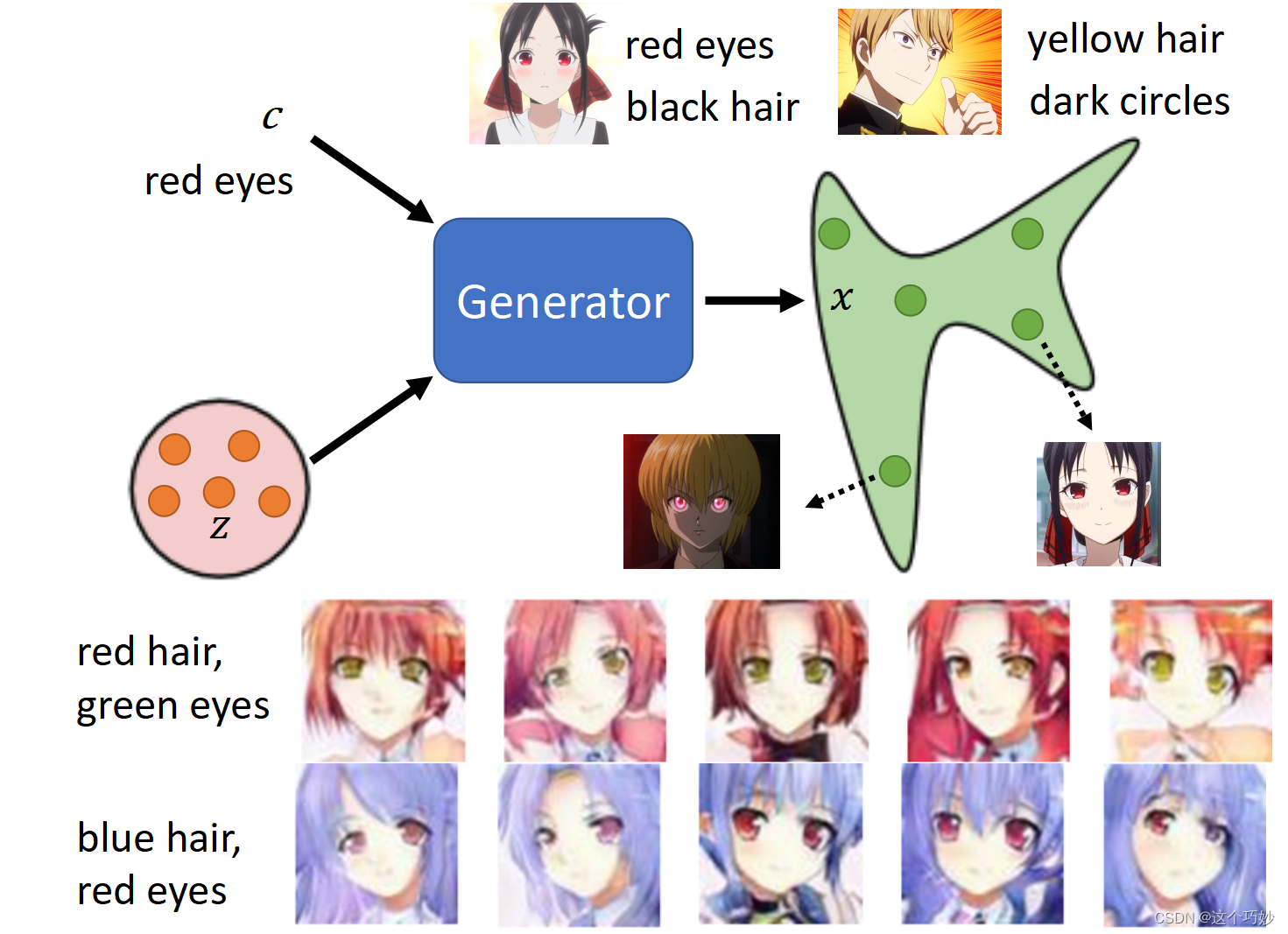
5.3.2 CGAN的原理
我们的目的是,既要让输出的图片真实,也要让输出的图片符合条件 c c c的描述。
- 因此对于生成器而言,所作的就是将输入的文本张量和一个从标准正态分布中**抽样出的张量
$z$**一起吃掉,吐出一张图片$x$。 - 而判别器输入便被改成了同时输入
$x$和 c c c,输出要做两件事情,一个是判断$x$是否是真实图片,另一个是$x$和$c$是否是匹配的。
因此对于判别器可能会面临几种可能
- 生成的图像真实且符合条件 Good
- 生成的图像真实但不符合条件 BAD
- 生成的图像虚假 BAD
5.3.3 CGAN的架构
在GAN这种完全无监督的方式加上一个标签或一点监督信息,使整个网络就可看成半监督模型。其基本架构与GAN类似,只要添加一个条件 c c c即可, c c c就是加入的监督信息,比如说MNIST数据集可以提供某个数字的标签信息,人脸生成可以提供性别、是否微笑、年龄等信息,带某个主题的图像等标签信息。
🎉🎉 在接下来的内容中,我们将结合代码,深入的了解CGAN的模型架构,实现一个简单的生成指定数字的CGAN网络。
模型训练流程
在本小节的内容中,我们将条件记作符号$c(condition)$。
算法:CCGAN的训练过程
在每次训练迭代中:
- 从数据集采样 m 个真实标签和对应的真实图片的正样本
$\left\{\left(c^{1}, x^{1}\right),\left(c^{2}, x^{2}\right), \ldots,\left(c^{m}, x^{m}\right)\right\}$- 从一个分布中采样 m 个噪音样本
$\left\{z^{1}, z^{2}, \ldots, z^{m}\right\}$- 通过生成网络,输入真实标签和噪音样本,生成对应标签的 m 个虚假图片的数据
$\left\{\tilde{x}^{1}, \tilde{x}^{2}, \ldots, \tilde{x}^{m}\right\}, \tilde{x}^{i}=G\left(c^{i}, z^{i}\right)$- 从数据集采样 m 个真实图片的样本
$\left\{\hat{x}^{1}, \hat{x}^{2}, \ldots, \hat{x}^{m}\right\}$,用以组合成真实图片但不符合条件的数据对- 更新判别器参数 θ d \theta_{d} θd 以最大化下式:
V ~ = 1 m ∑ i = 1 m log D ( c i , x i ) + 1 m ∑ i = 1 m m log ( 1 − D ( c i , x ~ i ) ) + 1 m ∑ i = 1 m log ( 1 − D ( c i , x ^ i ) ) , θ d ← θ d + η ∇ V ~ ( θ d ) \begin{array}{l} \tilde{V}=\frac{1}{m} \sum_{i=1}^{m} \log D\left(c^{i}, x^{i}\right) +\frac{1}{m} \sum_{i=1}^{m^{m}} \log \left(1-D\left(c^{i}, \tilde{x}^{i}\right)\right)+\frac{1}{m} \sum_{i=1}^{m} \log \left(1-D\left(c^{i}, \hat{x}^{i}\right)\right),\theta_{d} \leftarrow \theta_{d}+\eta \nabla \tilde{V}\left(\theta_{d}\right) \end{array} V~=m1∑i=1mlogD(ci,xi)+m1∑i=1mmlog(1−D(ci,x~i))+m1∑i=1mlog(1−D(ci,x^i)),θd←θd+η∇V~(θd)
- 从一个分布中采样 m 个噪音样本
$\left\{z^{1}, z^{2}, \ldots, z^{m}\right\}$- 从数据集采样 m 个文本条件
$\left\{c^{1}, c^{2}, \ldots, c^{m}\right\}$- 更新生成器器参数
$\theta_{g}$以最大化下式:V ~ = 1 m ∑ i = 1 m log ( D ( G ( c i , z i ) ) ) , θ g ← θ g − η ∇ V ~ ( θ g ) \tilde{V}=\frac{1}{m} \sum_{i=1}^{m} \log \left(D\left(G\left(c^{i}, z^{i}\right)\right)\right), \theta_{g} \leftarrow \theta_{g}-\eta \nabla \tilde{V}\left(\theta_{g}\right) V~=m1i=1∑mlog(D(G(ci,zi))),θg←θg−η∇V~(θg)
因为 CGAN 是半监督学习,采样的每一项都是文字和图片的 pair。CGAN 的核心就是判断什么样的 pair 给高分,什么样的 pair 给低分。
判别器
V ~ = 1 m ∑ i = 1 m log D ( c i , x i ) + 1 m ∑ i = 1 m m log ( 1 − D ( c i , x ~ i ) ) + 1 m ∑ i = 1 m log ( 1 − D ( c i , x ^ i ) ) \begin{array}{l} \tilde{V}=\frac{1}{m} \sum_{i=1}^{m} \log D\left(c^{i}, x^{i}\right) \\ +\frac{1}{m} \sum_{i=1}^{m^{m}} \log \left(1-D\left(c^{i}, \tilde{x}^{i}\right)\right)+\frac{1}{m} \sum_{i=1}^{m} \log \left(1-D\left(c^{i}, \hat{x}^{i}\right)\right) \\ \end{array} V~=m1∑i=1mlogD(ci,xi)+m1∑i=1mmlog(1−D(ci,x~i))+m1∑i=1mlog(1−D(ci,x^i))
第一项是正确条件与真实图片的 pair,应该给高分;第二项是正确条件与仿造图片的pair,应该给低分(于是加上了“1-”);第三项是错误条件与真实图片的 pair,也应该给低分。可以明显的看出,CGAN 与 GANs 在判别器上的不同之处就是多出了第三项。
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.label_emb = nn.Embedding(10,10)
#Embedding类返回的是一个形状为[每句词个数, 词维度]的矩阵。
self.model = nn.Sequential(
nn.Linear(794,1024),
nn.LeakyReLU(0.2,inplace=True),
nn.Dropout(0.4),
nn.Linear(1024,512),
nn.LeakyReLU(0.2,inplace=True),
nn.Dropout(0.4),
nn.Linear(512,256),
nn.LeakyReLU(0.2,inplace=True),
nn.Dropout(0.4),
nn.Linear(256,1),
nn.Sigmoid()
)
def forward(self,x,labels):
# 将图片reshape为(batch_size,784)的tensor
x = x.view(x.size(0),784)
# labels是用randint随机初始化到[0,9]的(batch_size,)的一维tensor。当作条件condition
# 每一个数字分配一个长度为10的向量。所以c.shape=(batch_size,10)
c = self.label_emb(labels)
# x.shape=(batch_size,794)
x = torch.cat([x,c],1)
out = self.model(x) # out.shape=(batch_size,1)
#可以删除数组形状中的单维度条目,即把shape中为1的维度去掉,但是对非单维的维度不起作用。
return out.squeeze()
D = Discriminator().to(device)
CGAN判别器的损失函数
# 定义判别器的损失函数交叉熵及优化器
criterion = nn.BCELoss()
# 定义判断器对真图片的损失函数
real_validity = D(real_images,real_labels)
# 损失比较,与1
d_loss_real = criterion(real_validity,torch.ones(batch_size).to(device))
# 判别器生成的值
real_score = real_validity
# 定义判别器对假图片(即由潜在空间点生成的图片)的损失函数
### 创建batch_size行100列的随机数的tensor,随机值的分布式均值为0,方差为1
z = torch.randn(batch_size,100).to(device)
### 输入的条件,即想要生成的数字[0,9],因此创建大小为batch_size的一维张量,其中取值范围在[0,9]
conditions = torch.randint(0, 10, (batch_size,)).to(device)
### 通过正态分布生成的特征数为100的z,以及conditions,产生一张fake_images
fake_images = G(z, conditions)
# 定义判断器对假图片的损失函数
fake_validity = D(fake_images, conditions)
# 损失比较,与0
d_loss_fake = criterion(fake_validity, torch.zeros(batch_size).to(device))
fake_score = fake_images # 生成器生成的值
# total
d_loss = d_loss_fake + d_loss_real
生成器
V ~ = 1 m ∑ i = 1 m log ( D ( G ( c i , z i ) ) ) \tilde{V}=\frac{1}{m} \sum_{i=1}^{m} \log \left(D\left(G\left(c^{i}, z^{i}\right)\right)\right) V~=m1i=1∑mlog(D(G(ci,zi)))
生成器的目的就是让判别器给仿造图片的得分越高越好,这与传统 GANs 本质上是一致的,只是在输入上多了一个参数 c。
class Generator(nn.Module):
def __init__(self):
super().__init__()
# 每一个数字分配一个长度为10的向量,总共十个数字,产生了10*10的tensor
self.label_emb = nn.Embedding(10, 10)
self.model = nn.Sequential(
nn.Linear(110, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(1024, 784),
nn.Tanh()
)
def forward(self, z, labels):
# 定义z是个从randn取样得到的shape为(batch_size,100)的二维的tensor
z = z.view(z.size(0), 100)
# labels是用randint随机初始化到[0,9]的(batch_size,)的一维tensor。当作条件condition
# 每一个数字分配一个长度为10的向量。所以c.shape=(batch_size,10)
c = self.label_emb(labels)
# x.shape=(batch_size,110)
x = torch.cat([z, c], 1)
out = self.model(x)
# 将out reshape为(batch_size,28,28)的tensor
return out.view(x.size(0), 28, 28)
G = Generator().to(device)
CGAN生成器的损失函数
# 定义生成器对假图片的损失函数,这里我们要求
# 判别器生成的图片越来越像真图片,故损失函数中
# 的标签改为真图片的标签,即希望生成的假图片,
# 越来越靠近真图片
### 创建batch_size行100列的随机数的tensor,随机值的分布式均值为0,方差为1
z = torch.randn(batch_size, 100).to(device)
### 输入的条件,即想要生成的数字[0,9],因此创建大小为batch_size的一维张量,其中取值范围在[0,9]
conditions = torch.randint(0, 10, (batch_size,)).to(device)
### 通过正态分布生成的特征数为100的z,以及conditions,产生一张fake_images
fake_images = G(z, conditions)
# 定义生成器的损失函数
validity = D(fake_images, fake_labels)
g_loss = criterion(validity, torch.ones(batch_size).to(device)) #标签为1
目标函数
min G max D V ( D , G ) = E x ∼ p data ( x ) [ log D ( x ∣ c ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ∣ c ) ) ) ] (5) \min _{G} \max _{D} V(D, G)=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x} \mid \boldsymbol{c})]+\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z} \mid \boldsymbol{c})))] \tag{5} GminDmaxV(D,G)=Ex∼pdata (x)[logD(x∣c)]+Ez∼pz(z)[log(1−D(G(z∣c)))](5)
5.3.4 训练模型
# 定义判别器的损失函数交叉熵及优化器
criterion = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(),lr=0.0001)
g_optimizer = torch.optim.Adam(G.parameters(),lr=0.0001)
#Clamp函数x限制在区间[min, max]内
def denorm(x):
out = (x+1)/2
return out.clamp(0,1)
def reset_grad():
d_optimizer.zero_grad()
g_optimizer.zero_grad()
#开始训练
total_step = len(data_loader)
for epoch in range(num_epochs):
for i,(images,labels) in enumerate(data_loader):
step = epoch*len(data_loader)+i+1
images = images.to(device)
labels = labels.to(device)
# 定义图像是真或假的标签
real_labels = torch.ones(batch_size).to(device) #真标签全是1
fake_labels = torch.randint(0,10,(batch_size,)).to(device) ##返回均匀分布的[0,10]之间的整数随机值
# ================================================================== #
# 训练判别器 #
# ================================================================== #
# 定义判断器对真图片的损失函数
real_validity = D(images,labels)
d_loss_real = criterion(real_validity,real_labels) #损失比较,与1
real_score = real_validity #判别器生成的值
# 定义判别器对假图片(即由潜在空间点生成的图片)的损失函数
z = torch.randn(batch_size,100).to(device)
#创建batch_size行100列的随机数的tensor,随机值的分布式均值为0,方差为1
fake_labels = torch.randint(0, 10, (batch_size,)).to(device)
#创建batch_size行列不指定的随机整数的tensor,随机值的区间是[low, high)[0,10]
fake_images = G(z,fake_labels)
fake_validity = D(fake_images,fake_labels)
d_loss_fake = criterion(fake_validity, torch.zeros(batch_size).to(device)) #损失比较,与0
fake_score = fake_images #生成器生成的值
d_loss= d_loss_fake + d_loss_real
# 对生成器、判别器的梯度清零
reset_grad()
d_loss.backward()
d_optimizer.step()
# ================================================================== #
# 训练生成器 #
# ================================================================== #
# 定义生成器对假图片的损失函数,这里我们要求
# 判别器生成的图片越来越像真图片,故损失函数中
# 的标签改为真图片的标签,即希望生成的假图片,
# 越来越靠近真图片
z = torch.randn(batch_size, 100).to(device)
fake_images = G(z, fake_labels)
validity = D(fake_images, fake_labels)
g_loss = criterion(validity, torch.ones(batch_size).to(device)) #标签为1
# 对生成器、判别器的梯度清零
# 进行反向传播及运行生成器的优化器
reset_grad()
g_loss.backward()
g_optimizer.step()
if (i + 1) % 200 == 0:
print('Epoch [{}/{}], Step [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.2f}, D(G(z)): {:.2f}'
.format(epoch, num_epochs, i + 1, total_step, d_loss.item(), g_loss.item(),
real_score.mean().item(), fake_score.mean().item() * (-1)))
# 保存真图片
if (epoch + 1) == 1: #只是保存一张
images = images.reshape(images.size(0), 1, 28, 28)
save_image(denorm(images), os.path.join(sample_dir, 'real_images.png'))
# 保存假图片
fake_images = fake_images.reshape(fake_images.size(0), 1, 28, 28)
save_image(denorm(fake_images), os.path.join(sample_dir, 'fake_images-{}.png'.format(epoch + 1)))
# 保存模型
torch.save(G.state_dict(), 'G.ckpt')
torch.save(D.state_dict(), 'D.ckpt')
可视化结果
import matplotlib.pyplot as plt # plt 用于显示图片
import matplotlib.pyplot as plt # plt 用于显示图片
import matplotlib.image as mpimg # mpimg 用于读取图片
reconsPath = './cgan_samples/real_images.png'
Image = mpimg.imread(reconsPath)
plt.imshow(Image) # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()
reconsPath = './cgan_samples/fake_images-50.png'
Image = mpimg.imread(reconsPath)
plt.imshow(Image) # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()
生成自定义图片
from torchvision.utils import make_grid
z = torch.randn(100, 100).to(device)
labels = torch.LongTensor([i for i in range(10) for _ in range(10)]).to(device)
images = G(z, labels).unsqueeze(1)
grid = make_grid(images, nrow=10, normalize=True)
#make_grid用于把几个图像按照网格排列的方式绘制出来
#每行的图片数量为10
#normalize如果为True,则把图像的像素值通过range指定的最大值和最小值归一化到0-1。
fig, ax = plt.subplots(figsize=(10,10))
#fig代表绘图窗口(Figure);ax代表这个绘图窗口上的坐标系(axis),一般会继续对ax进行操作。
#表示figure 的大小为宽、长(单位为inch)
ax.imshow(grid.permute(1, 2, 0).detach().cpu().numpy(), cmap='binary')
#grid.permute(1, 2, 0)将tensor的维度换位,原来的顺序是(0,1,2)
#当使用detach()分离tensor但是没有更改这个tensor时,并不会影响backward()
#显示设置,两端发散的色图 colormaps
ax.axis('off')
def generate_digit(generator, digit):
z = torch.randn(1, 100).to(device)
label = torch.LongTensor([digit]).to(device)
img = generator(z, label).detach()
img = 0.5 * img + 0.5 #还原图像,反归一化
return transforms.ToPILImage()(img)
generate_digit(G, 8)
5.3.5 CGAN判别器架构的讨论
大部分的 CGAN 判别器都采用上述架构,为了把图片和条件结合在一起,往往会把 x x x丢入一个网络产生一个 embedding,condition 也丢入一个网络产生一个 embedding,然后把这两个 embedding 拼在一起丢入一个网络中,这个网络既要判断第一个 embedding 是否真实,同时也要判断两个 embedding 是否逻辑上匹配,最终给出一个分数。但是也有一种CGAN 采用了另外一种架构。
首先有一个网络它只负责判断输入 $x$ 是否是一个真实的图片,并且同时产生一个embedding,与 $c$ 一同传给第二个网络;然后第二个网络只需判断
x
x
x 和 $c$ 是否匹配。最终两个网络的打分依据模型需求进行加权筛选即可。
**优劣势对比:**第二种模型有一个明显的好处就是判别器能区分出为什么这样的 pair 会得低分,是因为 $c$ 不匹配还是 $x$ 不够真实;然而对第一种模型却不知道得分低的原因是什么,这会造成一种情况就是生成器产生的图片已经足够清晰了,但是因为不匹配 $c$ 而得了低分,而生成器不知道得分低的原因是什么,依然以为是产生的图片不够清晰,那这样生成器就有可能朝着错误的方向迭代。
不过,目前第一种模型还是被广泛应用的,其实事实上二者的差异在实际中也不是特别明显。
5.3.6 小结
在本节内容中,我们学习了CGAN模型的原理及架构,同时基于CGAN模型完成了手写数字条件生成的案例。
对比传统的GAN模型,CGAN模型在输入部分增加了文本条件$label$的输入,但是文本字符串是无法直接当作生成器网络的输入,需要通过embedding技术编码为文本张量$c$,才能称为生成器网络的输入。
对于判别器网络的架构存在两种模型,一种是只用一个network,同时吃入图片张量 $x$ 和文本张量 $c$ ,进行两个任务的判断;另一种使用了两个network,第一个网络只负责判断输入 $x$ 是否是一个真实的图片,并且同时产生一个embedding,与 $c$ 一同传给第二个网络;然后第二个网络只需判断 $x$ 和 $c$ 是否匹配。最终两个网络的打分依据模型需求进行加权筛选即可。虽然第二种模型能更好解释什么原因导致得分低,但是事实上二者的差异在实际中也不是特别明显。















 756
756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









