







动手学CV-Pytorch计算机视觉 DCGAN实战:深度卷积生成对抗网络
生成对抗网络是指一类采用对抗训练方式来进行学习的深度生成模型,其包含的判别网络和生成网络都可以根据不同的生成任务使用不同的网络结构。
本节介绍一个生成对抗网络的具体模型:深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Network,DCGAN)[Radford et al., 2016]。在 DCGAN 中,判别网络是一个传统的深度卷积网络,但使用了带步长的卷积来实现下采样操作,不用最大汇聚(pooling)操作;生成网络使用一个特殊的深度卷积网络来实现,使用微步卷积来生成64 × 64大小的图像。
5.4.1 生成器模型
DCGAN在GAN的基础上优化了网络结构,加入了卷积层(Conv)、转置卷积 (ConvTranspose)、**批量正则(Batch_norm)**等层,使得网络更容易训练,下图为使用卷积层的DCGAN的生成器网络结构示意图。
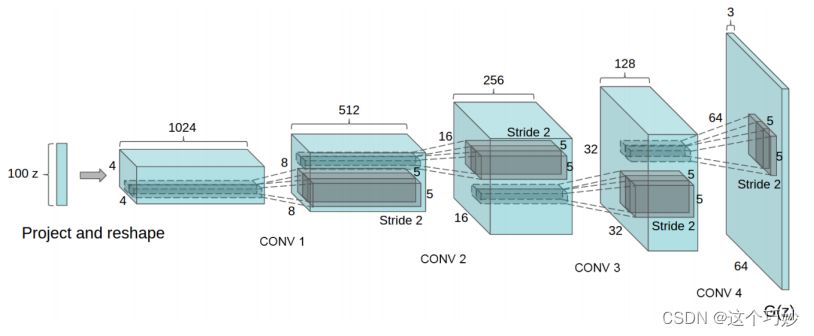
可以看出,生成器的输入是一个 100 维的噪声,中间会通过 4 层卷积层,每通过一个卷积层通道数减半,长宽扩大一倍 ,最终产生一个 64*64*3 大小的图片输出。值得说明的是,在很多引用 DCGAN 的paper中,误以为这 4 个卷积层是Wide Convolution(宽卷积)层,但其实在DCGAN 的介绍中这 4 个卷积层是 Fractionally Strided Convolution(微步幅度卷积)层,二者的差别如下图所示:
上图左边是宽卷积,用 3*3 的卷积核把 2*2 的矩阵反卷积成 4*4 的矩阵;而右边是微步幅度卷积,用 3*3 的卷积核把 3*3 的矩阵卷积成 5*5 的矩阵,二者的差别在于,宽卷积是在整个输入矩阵周围添 0,而微步幅度卷积会把输入矩阵拆开,在每一个像素点的周围添 0。
上述的两种从低维特征映射到高维特征的卷积操作称为转置卷积(Transposed Convolution)[Dumoulin et al., 2016],也称为反卷积(Deconvolution)[Zeiler et al., 2011]。
转置卷积的动图见https://nndl.github.io/v/cnn-conv-more
代码示例
n z nz nz是 z z z输入向量的长度, n g f ngf ngf与通过生成器传播的特征图的大小有关, n c nc nc是输出图像中的通道数(对于RGB图像设置为3)。
以下是生成器的代码:
# 生成器代码
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









