






前言
参考网上的数据库开发资料,将代码及实现逻辑梳理,经过几步踩坑,最终编译通过(Windows平台),实验成功。
git地址:代码
可执行文件:下载
测试命令 ,写入模拟数据
"insert 18 user18 person18@example.com",
"insert 7 user7 person7@example.com",
"insert 10 user10 person10@example.com",
"insert 29 user29 person29@example.com",
"insert 23 user23 person23@example.com",
"insert 4 user4 person4@example.com",
"insert 14 user14 person14@example.com",
"insert 30 user30 person30@example.com",
"insert 15 user15 person15@example.com",
"insert 26 user26 person26@example.com",
"insert 22 user22 person22@example.com",
"insert 19 user19 person19@example.com",
"insert 2 user2 person2@example.com",
"insert 1 user1 person1@example.com",
"insert 21 user21 person21@example.com",
"insert 11 user11 person11@example.com",
"insert 6 user6 person6@example.com",
"insert 20 user20 person20@example.com",
"insert 5 user5 person5@example.com",
"insert 8 user8 person8@example.com",
"insert 9 user9 person9@example.com",
"insert 3 user3 person3@example.com",
"insert 12 user12 person12@example.com",
"insert 27 user27 person27@example.com",
"insert 17 user17 person17@example.com",
"insert 16 user16 person16@example.com",
"insert 13 user13 person13@example.com",
"insert 24 user24 person24@example.com",
"insert 25 user25 person25@example.com",
打印btree节点
.btree
一、实现REPL
REPL(Read-Eval-Print Loop,简称REPL) “读取-求值-输出”循环, 也被称做交互式顶层构件,是一个简单的交互式的编程环境。
本实例启动无限循环,接受输入字符串,实现交互式窗口
二、SQL的解析前端
1.SQL解析
并单独封装一个do_meta_command函数来处理它。
以.开头的非sql语句称作元命令 (meta command) 所以我们在一开始就检查是否以其开头
bool DB::parse_meta_command(std::string& command)
{
if (command[0] == '.')
{
switch (do_meta_command(command))
{
case META_COMMAND_SUCCESS:
return true;
case META_COMMAND_UNRECOGNIZED_COMMAND:
std::cout << "Unrecognized command: " << command << std::endl;
return true;
}
}
return false;
}
sql语句目前仅定义了如下简单的两种状态字节码
enum StatementType { STATEMENT_INSERT, STATEMENT_SELECT };
同时再将上一步成功转化后得到的statement交给虚拟机进行解析。
2.实现一个虚拟机
根据得到的statement让虚拟机伪执行一下对应sql语句的操作效果。
void DB::excute_statement(Statement &statement)
{
switch (statement.type)
{
case STATEMENT_INSERT:
std::cout << "Executing insert statement" << std::endl;
break;
case STATEMENT_SELECT:
std::cout << "Executing select statement" << std::endl;
break;
}
}
void DB::start()
{
while (true)
{
print_prompt();
std::string input_line;
std::getline(std::cin, input_line);
if (parse_meta_command(input_line))
{
continue;
}
Statement statement;
if (parse_statement(input_line, statement))
{
continue;
}
execute_statement(statement);
}
}
设计储存结构
只支持单表 user ,目前规定所储存的类型结构如下
| 列 | 类型 |
|---|---|
| id | 整型 (integer) |
| username | 可变字符串 (varchar 32) |
| 可变字符串 (varchar 255) |
如果将一行行的数据了,合理的储存起来呢?在实现Btree前,先选择将它分组到 页面 ***(Page)***当中去,然后将这些页面以数组的形式排列。此外,我们需要在一页中,尽可能的将其紧密排列,意味着数据应该一个挨着一个。
| 列 | 大小 (bytes) | 偏移量 (offset) |
|---|---|---|
| id | 4 | 0 |
| username | 32 | 4 |
| 255 | 36 | |
| 总计 | 291 |
通过实现序列化 (serialize) 以及反序列化 (serialize) 来达成该目的。
同时注意到我们这里写了一个(char *)的强制转化类型,是为了让编译器明白,偏移量 (offset) 是以单个字节 (bytes) 为单位的
接下来,创建的Table来储存这些分页。同时与大多数计算机系统一样,将其设置为4k大小。
#define TABLE_MAX_PAGES 100
const uint32_t PAGE_SIZE = 4096;
const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
class Table
{
public:
uint32_t num_rows;
void *pages[TABLE_MAX_PAGES];
Table()
{
num_rows = 0;
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++)
{
pages[i] = NULL;
}
}
~Table()
{
for (int i = 0; pages[i]; i++)
{
free(pages[i]);
}
}
};
外还应该知道,表页该从何处开始读写。
void *row_slot(Table &table, uint32_t row_num)
{
uint32_t page_num = row_num / ROWS_PER_PAGE;
void *page = table.pages[page_num];
if (page == NULL)
{
// Allocate memory only when we try to access page
page = table.pages[page_num] = malloc(PAGE_SIZE);
}
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return (char *)page + byte_offset;
}
执行储存结构
对于insert操作,我们首先判断它是否超出储存限制,针对操作执行结果,我们同样添加了与我们之前类似的枚举类状态码
enum ExecuteResult { EXECUTE_SUCCESS, EXECUTE_TABLE_FULL };
之后,若满足对应条件,我们寻找到合适的内存插入位置,将我们输入的行以serialize_row的方式填充到内存page当中。
ExecuteResult DB::execute_insert(Statement &statement, Table &table)
{
if (table.num_rows >= TABLE_MAX_ROWS)
{
std::cout << "Error: Table full." << std::endl;
return EXECUTE_TABLE_FULL;
}
void *page = row_slot(table, table.num_rows);
serialize_row(statement.row_to_insert, page);
table.num_rows++;
return EXECUTE_SUCCESS;
}
类似的对于select操作,我们仅需从page中对应位置通过deserialize_row的方式获取到即可。
ExecuteResult DB::execute_select(Statement &statement, Table &table)
{
for (uint32_t i = 0; i < table.num_rows; i++)
{
Row row;
void *page = row_slot(table, i);
deserialize_row(page, row);
std::cout << "(" << row.id << ", " << row.username << ", " << row.email << ")" << std::endl;
}
return EXECUTE_SUCCESS;
}
最后将我们所设计好的操作交给虚拟机来执行即可。
void DB::execute_statement(Statement &statement, Table &table)
{
ExecuteResult result;
switch (statement.type)
{
case STATEMENT_INSERT:
result = execute_insert(statement, table);
break;
case STATEMENT_SELECT:
result = execute_select(statement, table);
break;
}
switch (result)
{
case EXECUTE_SUCCESS:
std::cout << "Executed." << std::endl;
break;
case EXECUTE_TABLE_FULL:
std::cout << "Error: Table full." << std::endl;
break;
}
}
void DB::start()
{
Table table;
while (true)
{
print_prompt();
std::string input_line;
std::getline(std::cin, input_line);
if (parse_meta_command(input_line))
{
continue;
}
Statement statement;
if (parse_statement(input_line, statement))
{
continue;
}
execute_statement(statement, table);
}
}
如何实现一个分页
现在将Table中 void *pages[TABLE_MAX_PAGES] 迁移到Pager;
class Pager
{
public:
int file_descriptor;
uint32_t file_length;
void *pages[TABLE_MAX_PAGES];
Pager(const char *filename);
void *get_page(uint32_t page_num);
void pager_flush(uint32_t page_num, uint32_t size);
};
构造这个Pager对象。
Pager::Pager(const char *filename)
{
file_descriptor = open(filename,
O_RDWR | // Read/Write mode
O_CREAT, // Create file if it does not exist
S_IWUSR | // User write permission
S_IRUSR // User read permission
);
if (file_descriptor < 0)
{
std::cerr << "Error: cannot open file " << filename << std::endl;
exit(EXIT_FAILURE);
}
file_length = lseek(file_descriptor, 0, SEEK_END);
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++)
{
pages[i] = nullptr;
}
}
我们看到,我们创建了一个新的file_descriptor用作我们物理磁盘上储存交互,并且设置了file_length属性来获取其文件大小。
此外我们在这当中添加了一个get_page函数来作用于row_slot当中,用于获取指定页的内存。逻辑依旧十分简单,如果我们没有获取到页面,我们就创建一个新的页面,并且将其存储到pages数组中。
实现光标
显然我们现在要指向table开头/结尾,所以我们需要实现一个cursor,它可以指向table开头,也可以指向table结尾。注意我们即然使用了cursor,也即指向这个词,我们在此处使用的就是指针,使用的其实一直就是DB::table唯一对象。
class Cursor
{
public:
Table *table;
uint32_t row_num;
bool end_of_table;
Cursor(Table *&table, bool option);
void *cursor_value();
void cursor_advance();
};
Cursor::Cursor(Table *&table, bool option)
{
this->table = table;
if (option)
{
// start at the beginning of the table
row_num = 0;
end_of_table = (table->num_rows == 0);
}
else
{
// end of the table
row_num = table->num_rows;
end_of_table = true;
}
}
同时我们将不再使用row_slot这个函数,而转为使用cursor_value函数。
void *Cursor::cursor_value()
{
uint32_t page_num = row_num / ROWS_PER_PAGE;
void *page = table->pager.get_page(page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return (char *)page + byte_offset;
}
再看一下select操作,我们先创建一个指向table开头的cursor,然后同样调用cursor_value函数便可直接获得对应分页信息。再使用cursor_advance函数,将cursor往后推进一个row。
BTREE是什么
B树 (B-tree) 是一种自平衡的树,能够保持数据有序。这种资料结构能够让查找数据、顺序访问、插入数据及删除的动作,都在对数时间内完成。 B树,概括来说是一个一般化的二元搜寻树(binary search tree)一个结点可以拥有2个以上的子结点。与自平衡二叉查找树不同,B树适用于读写相对大的数据块的存储系统,例如磁盘。
B树减少定位记录时所经历的中间过程,从而加快存取速度。 B树这种数据结构可以用来描述外部存储。这种资料结构常被应用在数据库和文件系统的实现上。
与二叉树不同,B-Tree中的每个结点可以有超过2个子结点。每个结点最多可以有m子结点,其中m称为树的“阶”。为了保持树的大部分平衡,我们还说结点必须至少有m/2子结点(四舍五入)。
但实际上,我们在这里使用的是B-Tree的一个变种情况,即:B+Tree。
我们在其中储存我们的数据,并且每个结点中存在多个键值对,而且这个键值是按照顺序排列的。
使用这种结构我们的查找时间复杂度是O(log(n)),而且插入和删除的时间复杂度也是O(log(n))。
实现Btree
BTree的结点是不同的,存在内部结点和叶子结点的差异性
现在来看我们重中之重的常量
/*
* Common Node Header Layout
*/
const uint32_t NODE_TYPE_SIZE = sizeof(uint8_t);
const uint32_t NODE_TYPE_OFFSET = 0;
const uint32_t IS_ROOT_SIZE = sizeof(uint8_t);
const uint32_t IS_ROOT_OFFSET = NODE_TYPE_SIZE;
const uint32_t PARENT_POINTER_SIZE = sizeof(uint32_t);
const uint32_t PARENT_POINTER_OFFSET = IS_ROOT_OFFSET + IS_ROOT_SIZE;
const uint8_t COMMON_NODE_HEADER_SIZE =
NODE_TYPE_SIZE + IS_ROOT_SIZE + PARENT_POINTER_SIZE;
我们将每个结点设置储存其本身结点类型,指向其父节点的指针(通过这个我们可以实现查找其兄弟结点),以及标记是否为根结点。我们将这三个数据定义为元数据作为结点的标头所存储。
我们来定义叶子结点需要储存的实际数据。
/*
* Leaf Node Header Layout
*/
const uint32_t LEAF_NODE_NUM_CELLS_SIZE = sizeof(uint32_t);
const uint32_t LEAF_NODE_NUM_CELLS_OFFSET = COMMON_NODE_HEADER_SIZE;
const uint32_t LEAF_NODE_HEADER_SIZE =
COMMON_NODE_HEADER_SIZE + LEAF_NODE_NUM_CELLS_SIZE;
我们储存其中包含多少个CELL,即对应的键值对(id与ROW中信息形成对应关系)。
我们定义我们键值对的键和值的大小,以及每个CELL的大小。同时我们也定义了叶子结点的最大CELL数量,以及它的空间大小,通过一个结点对应一个页面 (Page)。
当叶子结点满了之后,需要对其进行分裂,这个分裂标准是什么?
我们需要将现有的 cell 分成两个部分:上半部分与下半部分。
上半部分的 key 严格大于下半部分的 key ,这样我们就可以将 cell
分成两个部分。因此,我们分配一个新的叶子结点,并将对应的上半部分移入
该叶子结点。
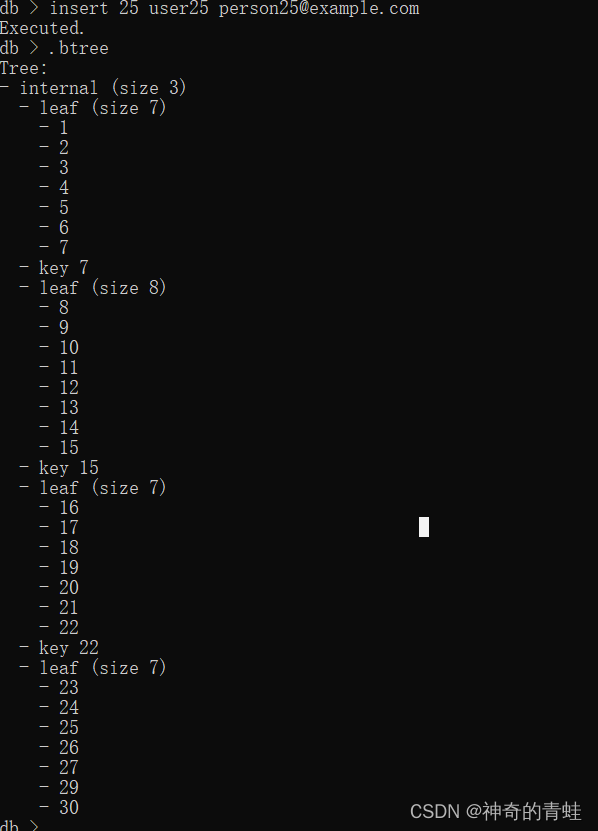
按照惯例,先看一下假设我们修复错误后应该如何正常打印我们的B-Tree。
核心仍旧是使用二分搜索+递归。我们知道内部结点中所储存的孩子结点的指针的右侧储存的是该孩子指针所包含的最大的key值,所以我们只需要将被搜索的key不断与key_to_right进行比较,直到找到key的位置。
此外,当我们找到了对应的孩子结点时,要注意判断其类型仍旧为InternalNode,我们需要递归调用internal_node_find。亦或是我们找到了LeafNode,我们仅需要返回一个相应指向该结点的Cursor对象即可。
为了保证我们能够在打印到第一个叶子结点的末端时,自动跳转到第二个叶子结点,我们在其标头设置相应的next_leaf字段来指向下一个叶子结点。
最后更新拆分后的父结点。
总结
本文实例有两处可改善
- 基于固定的存储结构(user)
- REPL只能在本机交互
- select insert 命令最简版
感兴趣小伙伴,可以一块基于socket实现REPL,同时能够支持create table 等命令。















 4048
4048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









