






CUDA线程层次
HelloFromGpu<<<?,?>>>();
-
Thread: sequential execution unit
- 所有线程执行相同的核函数
- 并行执行
-
Thread Block: a group of threads
- 执行在一个Streaming Multiprocessor(SM)
- 同一个Block中的线程可以协作
-
Thread Grid: a colleciton of thread blocks
- 一个Grid当中的Block可以在多个SM中执行 -
执行设置
dim3 grid(3,2,1),block(5,3,1)```
- Built-in variables:
- threadIdx.[x y z]是执行当前kernel函数的线程在block中的索引值
- blockIdx.[x y z ]是执行当前kernel函数的线程所在block,在grid中的索引值
- blockDim.[x y z] 表示一个block 中包含多少个线程
- gridDim.[x y z ]表示一个grid中包含多少个线程块
```cpp
__global__ void add(int *a,int *b,int *c){
c[threadIdx.x]=a[threadIdx.x]+b[threadIdx.x];
}
add<<<1,4>>>(a,b,c);
实际上在设备运行的样子:
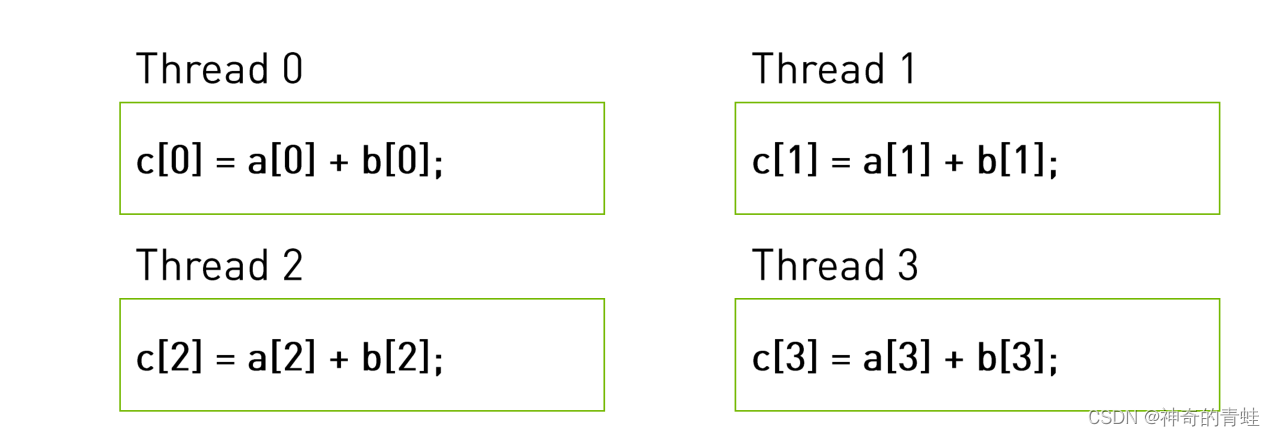
WHY BOTH BLOCK AND Thread
为什么不只有线程?这样不就更方便的使用了吗?
Blocks好像不是必须的
- 增加了一个层级的抽象,也增加了复杂度
使用Blocks或者grid我们收获了什么?
- This is related to the GPU architecture!
CUDA的执行流程
- 加载核函数
- 将Grid分配到一个Device
- 根据<<<>>>内的执行设置的第一个参数,Giga Thread engine将block分配到sm中。一个block内的线程一定会在同一个SM内,一个SM可以有很多个block。
- 根据<<<>>>内的执行设置的第二个参数,Warp调度器会将调用线程。
- Warp调度器为了提高运行效率,会将每32个线程分为一组,称作一个warp。
- 每个warp会被分配到32个core上运行
硬件调度 : - Grid:GPU(GPC)级别的调度单位
- Block(CTA):SM级别的调度单位
- Thread/Warp:CUDA core级别的调度单位
资源和通信: - Grid:共享同样的kernel 和Context
- Block(CTA):同一个SM(Streaming Multiprocessor),同一个SM(Shard Memory)
- Threads/Warp: 允许同一个warp中的thread读取其他thread中的值。
CUDA线程索引
int index = threadIdx.x+blockIdx.x*blockDim.x;
如何设置Gridsize和Blocksize:
block_size=128;
grid_size=(N+block_size-1)/block_size;
每个BLOCK可以申请多少个线程?

CUDA线程分配
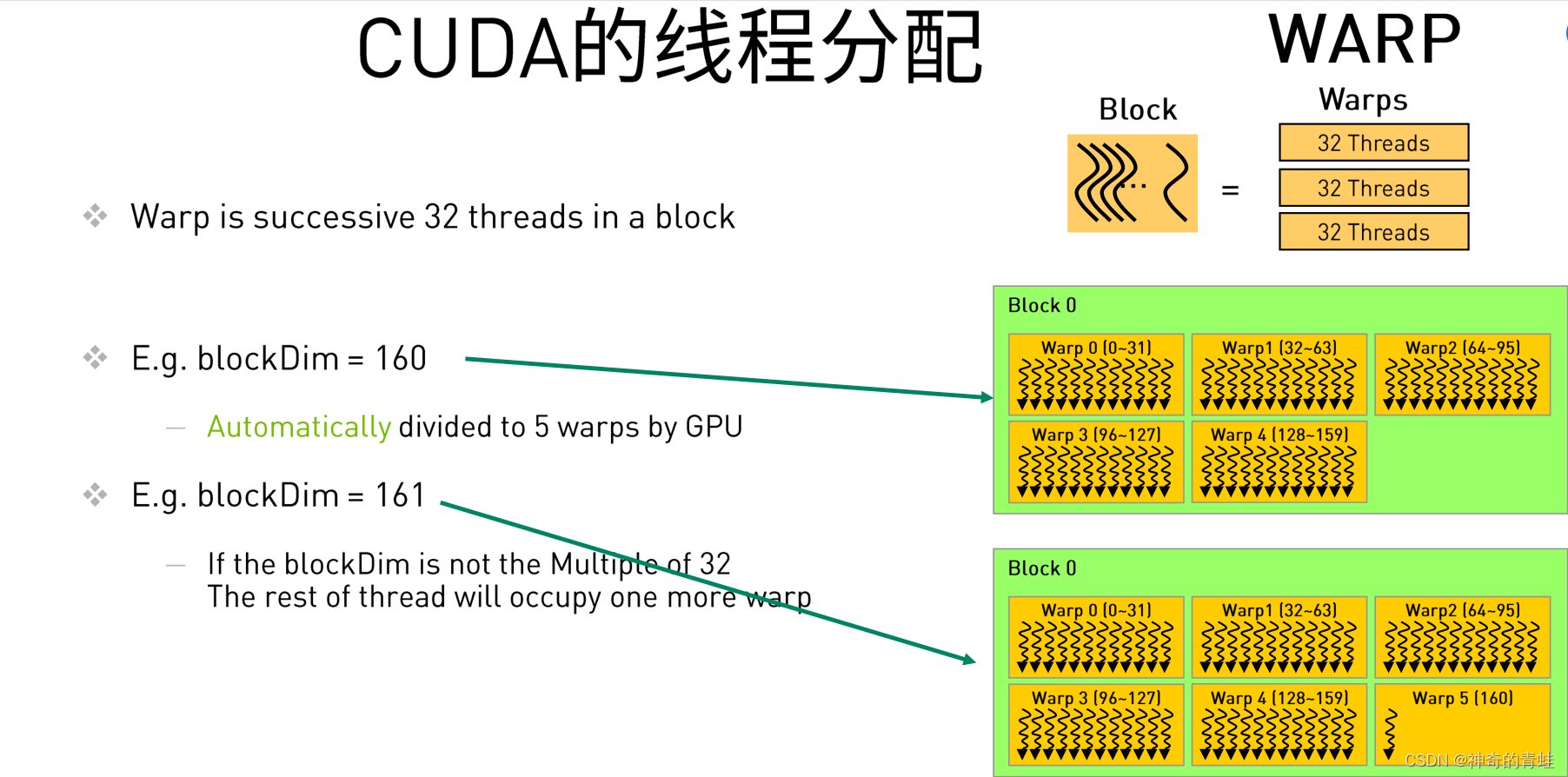
如果我们的数据过大,线程数量不够怎么办?
__global__ add (const double *x,const double *y,double *z,int n)
{
int index=blockDim.x*blockIdx.x+threadIdx.x;
int stride=blockDim.x*gridDim.x;
for(;index<n;index+stride)
{
z[index]=x[index]+y[index];
}
}















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









