






CUDA编程
为什么使用cuda
常规传统单核处理器遇到物理约束,时钟频率(perf/clock)无法保存线性。 现在的CPU系统已经遇到各种瓶颈,只能向多核及并行系统发展,顺势而生GPU-Graphics Process Unit .
并行计算
并行计算是同时应用多个计算资源解决一个计算问题,包括以下三点:涉及多个计算资源或处理器,问题被分解为多个离散的部分,可以同时处理(并行),每个部分可以由一系列指令完成。 并且最好是计算密集的任务,通信和计算开销比例合适,不要受制于访存带宽。
目前这些都能在基于ARM平台的JetsonNANO上完成。
加速比
Amdahl’sLaw程序可能的加速比取决于可以并并行的部分。
speedup = 1/ (1-p)
- 如果没有可以并行化的,P=0 and the speedup=1. 如果全部可以并行化,P=1 and the speedup is infinite(in theory);
2.如果50%可以并行化,maximum speedup=2; - 如果有N个并行处理器
speedup =1/(p/n+s)
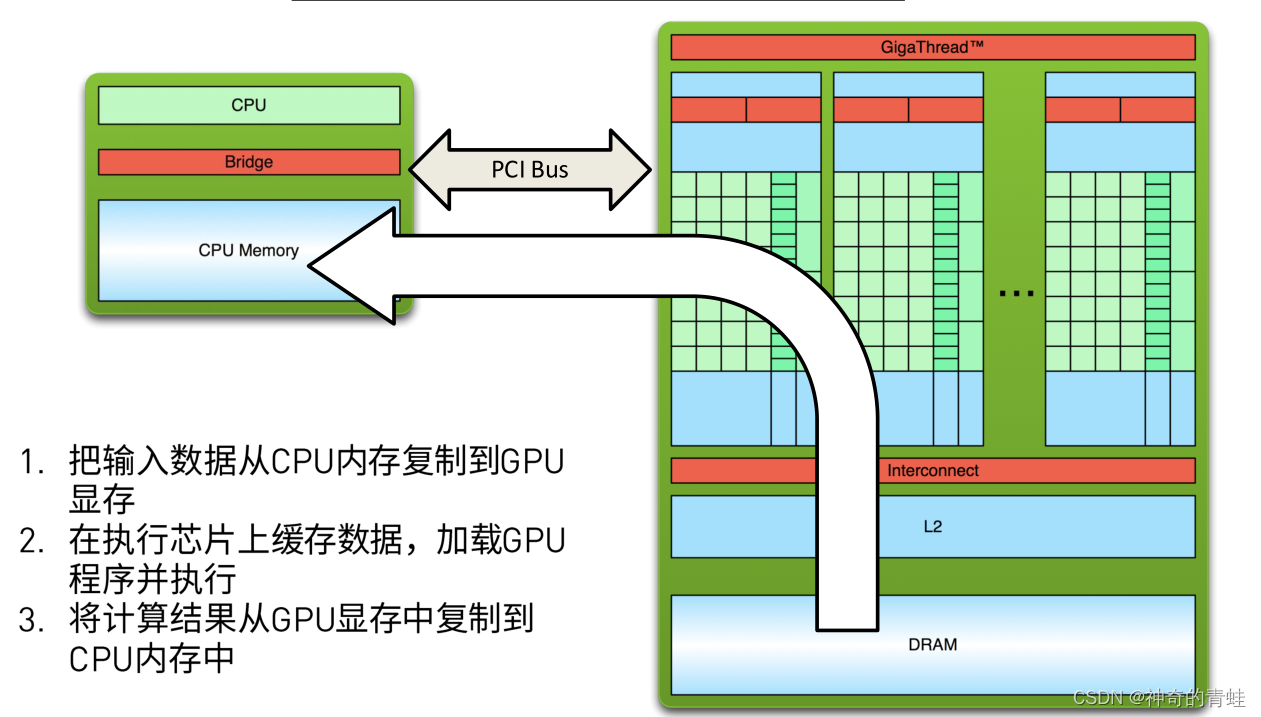
cuda程序编写
- 把输入数据从cpu内存复制到gpu显存
- 执行cpu上缓存数据,加载GPU程序并行执行
- 将计算结果从gpu显存中复制到cpu内存中
cuda编程模式:Extended C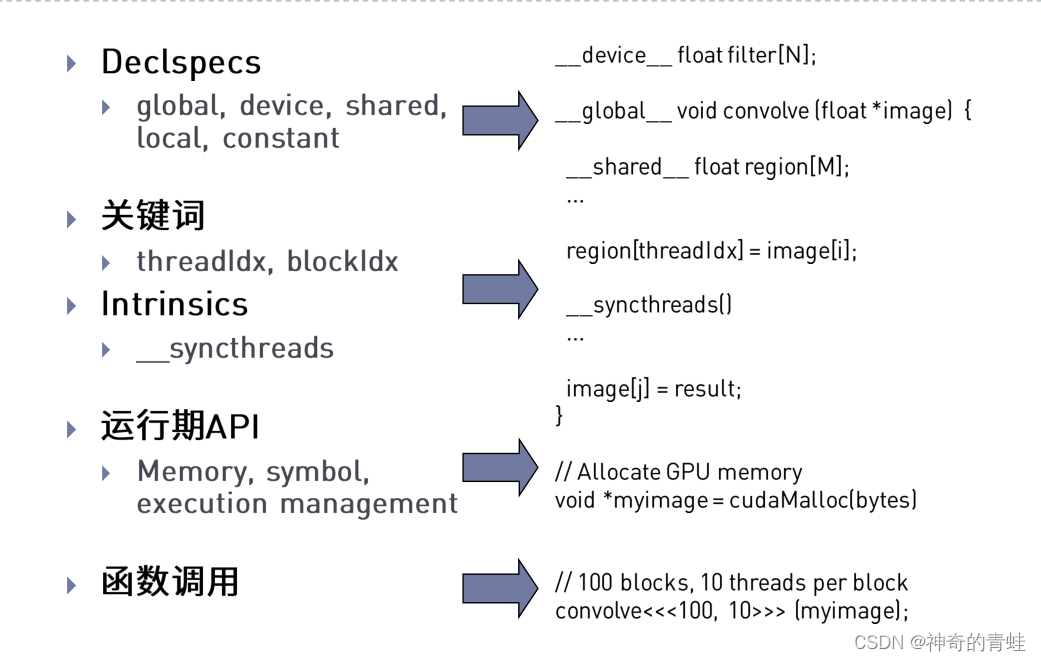
cuda declpecs

| 执行位置 | 调用位置 | |
|---|---|---|
| __device____float DeiceFunc() | device | device |
| global void KernelFunc() | device | host&device(arch>3.0) |
| host float HostFunc() | host | host |
网格、线程块、线程
调用核函数时,指定并发的线程数量,是由网格(含有多少线程块),线程(含有多少线程)共同决定。

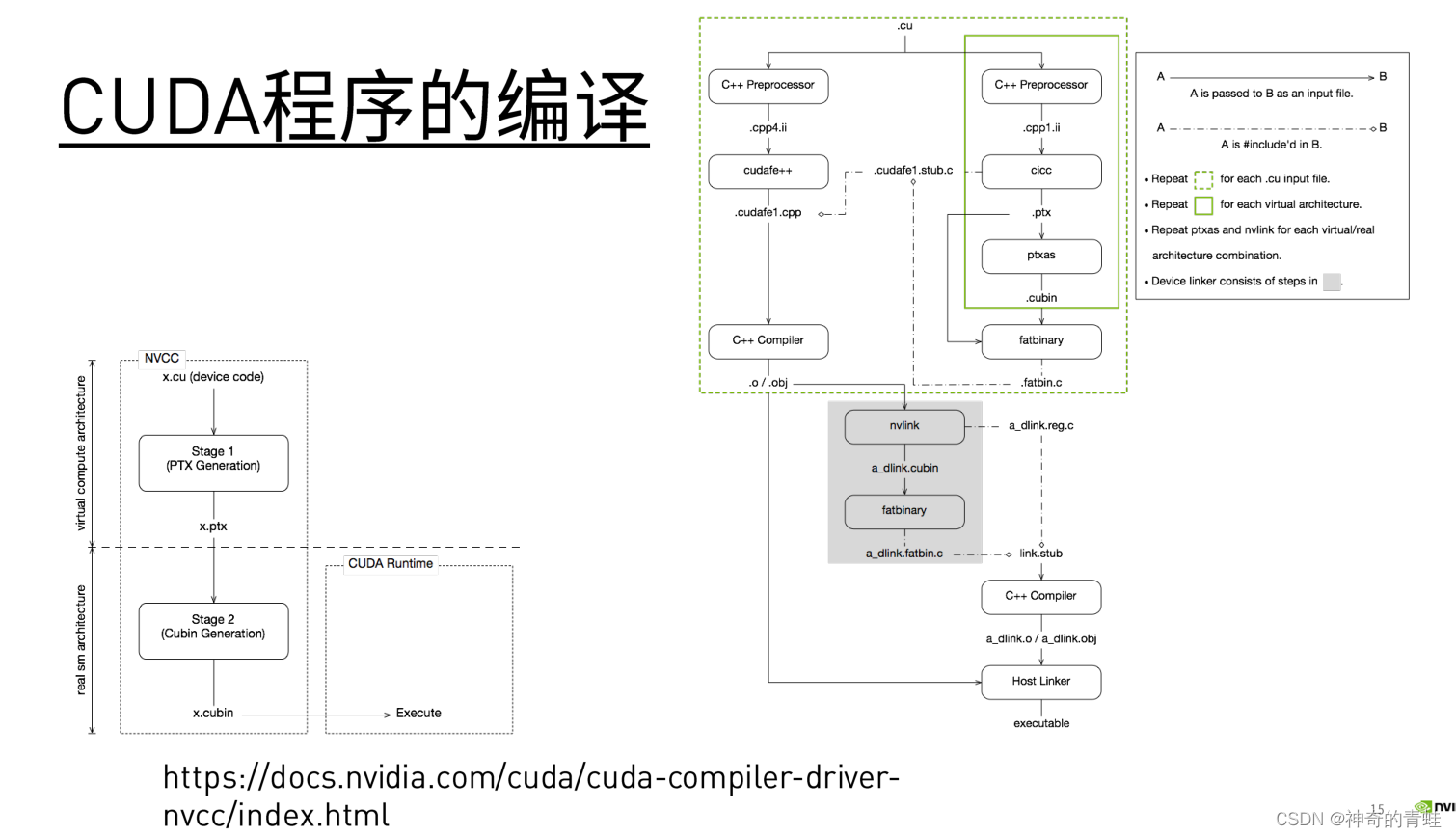
CUDA程序的编译

NVPROF
















 850
850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









