```
import torch
import torch.nn as nn
from skimage.segmentation import chan_vese
import numpy as np
from torch.nn import Conv2d
from torchvision.ops import FeaturePyramidNetwork
from torchvision.models import resnet50
import os
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE'
class ImageSegmentationModel(nn.Module):
def __init__(self):
super(ImageSegmentationModel,self).__init__()
self.conv_layers = nn.Sequential(
nn.Conv2d(1,128,kernel_size=3,stride=2),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.ReLU(),
nn.Conv2d(128,64, kernel_size=3, stride=2),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.ReLU(),
nn.Conv2d(64,32,kernel_size=3,stride=2),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.ReLU(),
nn.Conv2d(32,16,kernel_size=3,stride=2)
)
#使用resnet作为特征提取器
self.resnet = resnet50(pretrained=True)
self.initial_layer = nn.Sequential(
self.resnet.conv1, # 输出通道64
self.resnet.bn1,
self.resnet.relu,
self.resnet.maxpool # 输出通道64
)
self.layer1 = self.resnet.layer1 # 输出256通道
self.layer2 = self.resnet.layer2 # 输出512通道
self.layer3 = self.resnet.layer3 # 输出1024通道
self.layer4 = self.resnet.layer4 # 输出2048通道
#修改,调整fpn输入通道
self.fpn = FeaturePyramidNetwork([256,512,1024,2048],256)
self.conv_layers11 = nn.Conv2d(256,1,kernel_size=1,stride=1)
self.final_conv = nn.Conv2d(16,21,kernel_size=1,stride=1)
self.softmax = nn.Softmax(dim=1)
def preprocess(self,x):
#将输入图像尺寸调整为511×511,使用双线性插值法
x = torch.nn.functional.interpolate(x,size=(511,511),mode='bilinear',align_corners=False)
#将输入图像转换为灰度图像,通过对通道维度求均值
x = torch.mean(x,dim=1,keepdim=True)
x_np = x.detach().cpu().numpy()
segmented = []
for i in range(x_np.shape[0]):
img = x_np[i,0]
#init =np.array([[img.shape[1]-1,0],[img.shape[1]-1,img.shape[0]-1],[0,img.shape[0]-1,],[0,0]])
snake = chan_vese(img,mu=0.25, lambda1=1.0, lambda2=1.0, tol=0.001, max_num_iter=500, dt=0.5)
seg = np.zeros_like(img)
from skimage.draw import polygon
rr, cc = polygon(snake[:,1],snake[:,0],seg.shape)
seg[rr, cc] = 1
segmented.append(seg)
segmented = np.array(segmented)
segmented = torch.from_numpy(segmented).unsqueeze(1).float().to(x.device)
return segmented
def forward(self,x):
y = torch.nn.functional.interpolate(x,size=(511,511),mode='bilinear',align_corners=False)
x = self.preprocess(x)
conv_output = self.conv_layers(x)
conv_output[0,:,:,:] = 16
print("conv_output:", conv_output.shape)
z = self.initial_layer(y)
c1 = self.layer1(z) # [batch,256,H,W]
c2 = self.layer2(c1) # [batch,512,H,W]
c3 = self.layer3(c2) # [batch,1024,H,W]
c4 = self.layer4(c3) # [batch,2048,H,W]
fpn_input = {
'feat1': c1,
'feat2': c2,
'feat3': c3,
'feat4': c4
}
fpn_output = self.fpn(fpn_input)
fpn_output_upsampled = torch.nn.functional.interpolate(fpn_output['feat1'], size=(511, 511), mode='bilinear',
align_corners=False)
final_output = nn.functional.conv2d(fpn_output_upsampled,conv_output,stride=1,padding=1,groups=16)
final_output = self.final_conv(final_output)
final_output = self.softmax(final_output)
return final_output```目前conv_output的shape为[batch_size=64,16,3,3],我想让这之后的conv_output变为4个shape为[16,16,3,3]进行之后的操作
最新发布








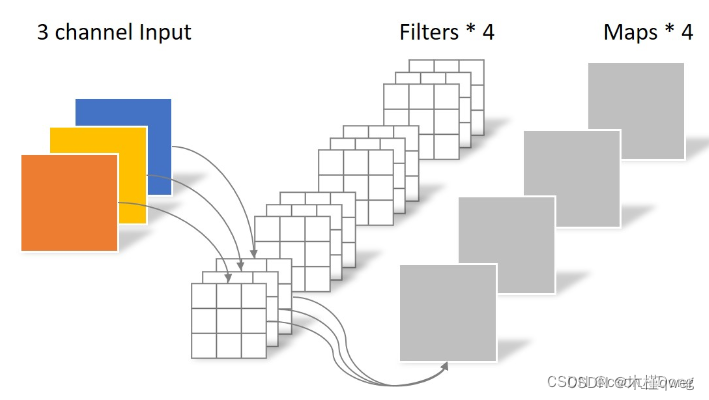
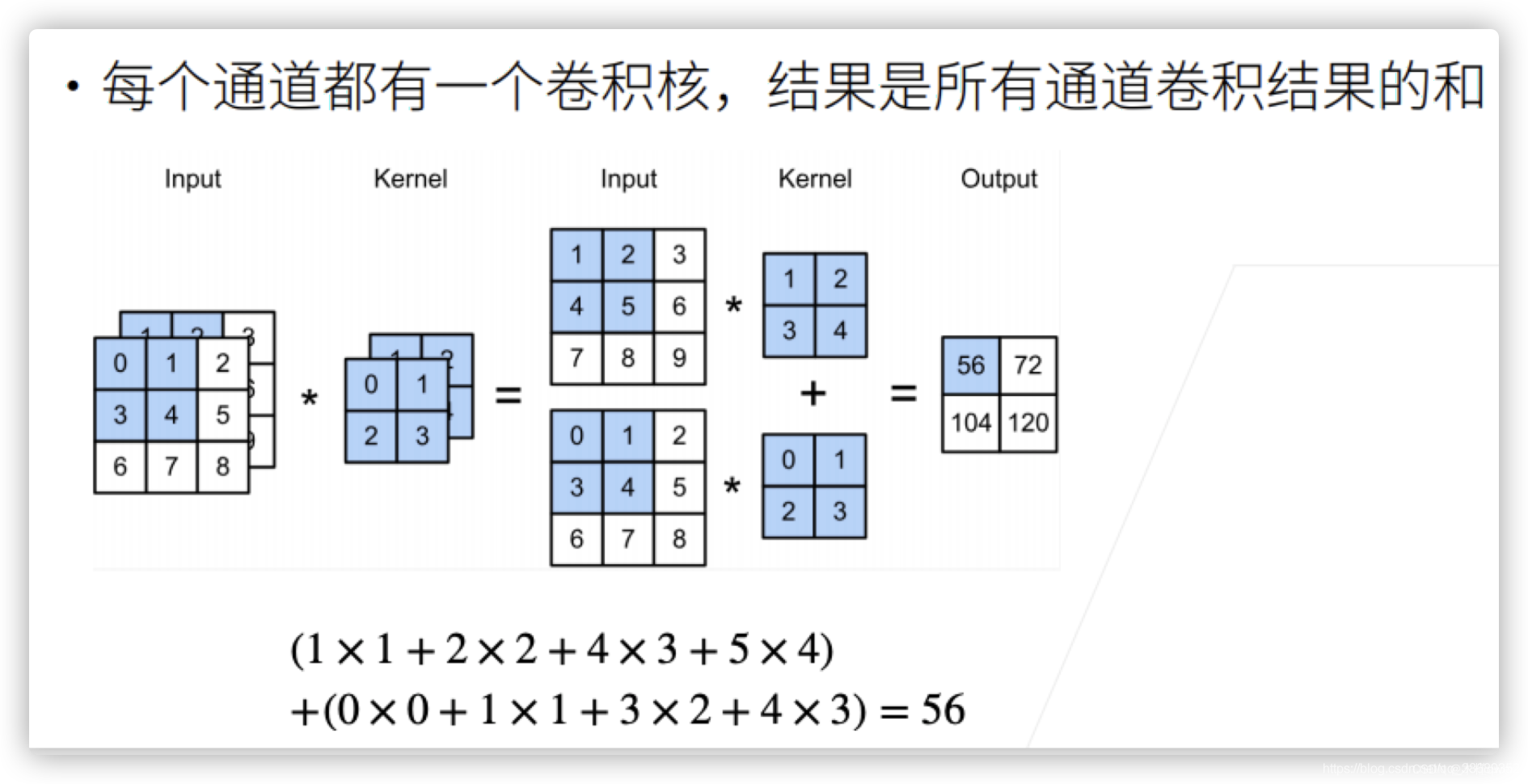
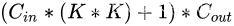


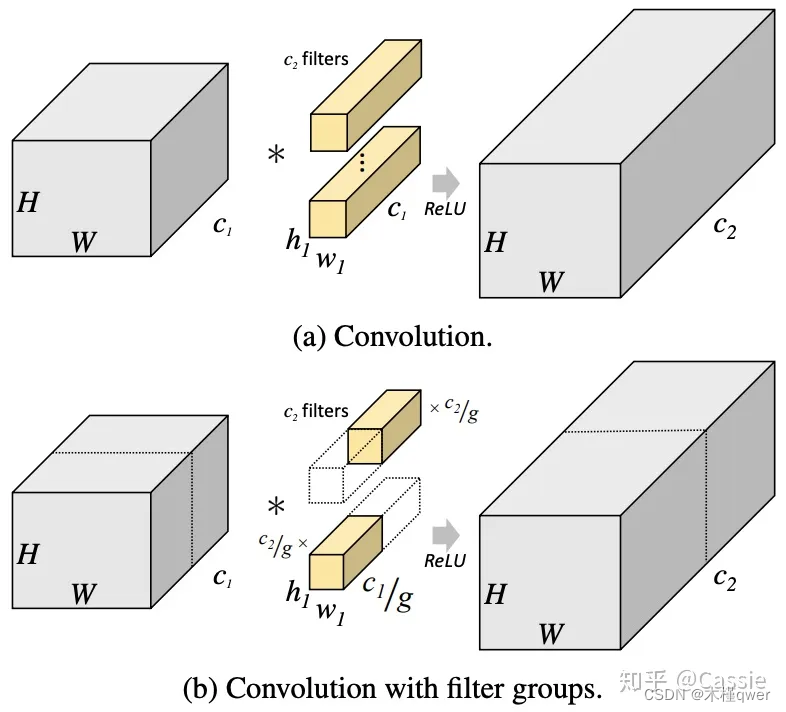




















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









