







对于支持向量机,其是一个二类分类器,但是对于多分类,SVM也可以实现。主要方法就是训练多个二类分类器。
一、多分类方式
1、一对所有(One-Versus-All OVA)
给定m个类,需要训练m个二类分类器。其中的分类器 i 是将 i 类数据设置为类1(正类),其它所有m-1个i类以外的类共同设置为类2(负类),这样,针对每一个类都需要训练一个二类分类器,最后,我们一共有 m 个分类器。对于一个需要分类的数据 x,将使用投票的方式来确定x的类别。比如分类器 i 对数据 x 进行预测,如果获得的是正类结果,就说明用分类器 i 对 x 进行分类的结果是: x 属于 i 类,那么,类i获得一票。如果获得的是负类结果,那说明 x 属于 i 类以外的其他类,那么,除 i 以外的每个类都获得一票。最后统计得票最多的类,将是x的类属性。
2、所有对所有(All-Versus-All AVA)
给定m个类,对m个类中的每两个类都训练一个分类器,总共的二类分类器个数为 m(m-1)/2 .比如有三个类,1,2,3,那么需要有三个分类器,分别是针对:1和2类,1和3类,2和3类。对于一个需要分类的数据x,它需要经过所有分类器的预测,也同样使用投票的方式来决定x最终的类属性。但是,此方法与”一对所有”方法相比,需要的分类器较多,并且因为在分类预测时,可能存在多个类票数相同的情况,从而使得数据x属于多个类别,影响分类精度。
对于多分类在matlab中的实现来说,matlab自带的svm分类函数只能使用函数实现二分类,多分类问题不能直接解决,需要根据上面提到的多分类的方法,自己实现。虽然matlab自带的函数不能直接解决多酚类问题,但是我们可以应用libsvm工具包。libsvm工具包采用第二种“多对多”的方法来直接实现多分类,可以解决的分类问题(包括C- SVC、n - SVC )、回归问题(包括e - SVR、n - SVR )以及分布估计(one-class-SVM )等,并提供了线性、多项式、径向基和S形函数四种常用的核函数供选择。
二、用libsvm在matlab中实现多分类(训练函数svmtrain+预测函数svmpredict)
对于libsvm中训练模型的函数svmtrain来说,model = svmtrain(训练数据类别, 训练数据, ‘一系列参数’);其中参数的形式如‘-c 2 -g 0.02’在这当中,参数主要包括以下几个方面:
(1) -s —— 其表示SVM的类型,包括上面提到的(默认值为0):
0 —— C-SVC
1—— v-SVC
2 —— 一类SVM
3 —— e -SVR
4 —— v-SVR
(2)-t—— 其表示核函数类型(默认值为2)
0 – 线性:u’v
1 – 多项式:(r*u’v + coef0)^degree
2 – RBF函数:exp(-gamma|u-v|^2)
3 –sigmoid:tanh(r*u’v + coef0)
(3)核函数参数设置
-d ——核函数中的degree设置(针对多项式核函数)(默认3)
-g ——核函数中的gamma函数设置(针对多项式/rbf/sigmoid 核函数)(默认1/ k,k为特征值个数)
-r ——核函数中的coef0设置(针对多项式/sigmoid核函数)((默认0)
-c ——设置C-SVC,e -SVR和v-SVR的参数(损失函数)(默认1)
-n——设置nu-SVC,一类SVM和nu- SVR的参数(默认0.5)
-p ——设置e -SVR 中损失函数p的值(默认0.1)
-m ——设置cache内存大小,以MB为单位(默认40)
-e ——设置允许的终止判据(默认0.001)
-h ——是否使用启发式,0或1(默认1)
-b ——是否训练一个SVC或者SVR模型,0或1(默认0)
-wi ——设置第i类的参数C为weight*C(C-SVC中的C)(默认1)
-v——n-fold交互检验模式,n为fold的个数,必须大于等于2(训练中使用了-v参数进行交叉验证时,返回的不是一个模型,而是交叉验证的分类的正确率或者回归的均方根误差)
使用函数svmtrain训练分类模型后,会返回一个结构体,其中包括数据:
(1) parameters(一个5*1的数组)
第一个元素:-s,SVM的类型(int默认为0)
第二个元素:-t,核函数类型(默认为2)
第三个元素:-d,核函数中的degree设置(针对多项式核函数)(默认3);
第四个元素:-g,核函数中的r(gamma)函数设置(针对多项式/rbf/sigmoid核函数) (默认为类别数目的倒数);
第五个元素:-r 核函数中的coef0设置(针对多项式/sigmoid核函数)((默认0)
(2)-nr_class: 表示数据集中有多少个类(int)
(3)-totalSV: 表示支持向量的总数。(int)
(4)-rho: 决策函数wx+b中的常数偏置的相反数(-b)。
(5)-Label: 表示数据集中类别的标签
(6)ProbA: 使用-b参数时用于概率估计的数值,否则为空。
ProbB: 使用-b参数时用于概率估计的数值,否则为空。
(7)-nSV: 表示每类样本的支持向量的数目,和Label的类别标签对应。
(8)-sv_coef: 表示每个支持向量在决策函数中的系数。
(9)-SVs: 表示所有的支持向量,如果特征是n维的,支持向量一共有m个,则为m x n的稀疏矩阵。
(10)nu: -n参数的显示
(11)iter: 迭代次数
(12)obj: 表示SVM文件转换的二次规划求解的最小值
svmpredict函数根据测试数据类属性,测试数据,以及通过svmtrain函数获得的模型来进行分类预测并计算分类精度,[predict_label, accuracy, dec_values]=svmpredict(测试数据类属性,测试数据,分类模型),返回值介绍如下:
(1)predicted_label:存储着分类后样本所对应的类属性。
(2)accuracy:一个3 * 1的数组,依次为:分类的正确率、回归的均方根误差、回归的平方相关系数。
(3)decision_values/prob_estimates:是一个表示概率的数组,对于一个m个数据,n个类的情况,如果指定“-b 1”参数(使用,则n x k的矩阵,每一行表示这个样本分别属于每一个类别的概率;如果没有指定“-b 1”参数,则为n * n×(n-1)/2的矩阵,每一行表示n(n-1)/2个二分类SVM的预测结果。
三、 使用libsvm进行分类的步骤
(1) 对数据做归一化(simple scaling)
对数据进行简单的缩放处理(scaling),缩放的最主要优点是能够避免大数值区间的属性过分支配了小数值区间的属性。另一个优点能避免计算过程中数值复杂度。(在试验中发现,归一化过程,分别对训练数据和测试数据进行归一化处理,比对训练数据和测试数据整体进行归一化处理获得的分类精度要高)
(2) 应用 RBF kernel
(3) 选择得到最优的c和g
c是惩罚因子,是一个在训练模型前需要自己设置的一个数值,它表示我们对类中的离群数据的重视程度,c的数值越大,表明我们越重视,越不想丢掉这些离群的数据;g是核函数中的gamma函数设置(针对多项式/rbf/sigmoid 核函数)(默认1/ k,k为特征值个数) 。c和g的选择对分类精度影响很大,在本文的试验中,用函数SVMcgForClass选择完成c和g的选择。
(4) 用得到的最优c和g训练分类模型
使用libsvm中的svmtrain函数来训练多分类模型
(5)测试
使用libsvm中的svmpredict函数来测试分类精度
四、实验
使用libsvm提供的数据进行多分类实验,下载的wine数据,是关于葡萄酒种类,下载的数据包括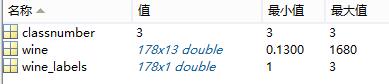
function [ classfication ] = test( train,test )
load chapter12_wine.mat %下载数据
train=[wine(1:30,:);wine(60:95,:);wine(131:153,:)]; %选取训练数据
train_group=[wine_labels(1:30);wine_labels(60:95); wine_labels(131:153)];%选取训练数据类别标识
test=[wine(31:59,:);wine(96:130,:);wine(154:178,:)];%选取测试数据
test_group=[wine_labels(31:59);wine_labels(96:130); wine_labels(154:178)]; %选取测试数据类别标识
%数据预处理,用matlab自带的mapminmax将训练集和测试集归一化处理[0,1]之间
%训练数据处理
[train,pstrain] = mapminmax(train');
% 将映射函数的范围参数分别置为0和1
pstrain.ymin = 0;
pstrain.ymax = 1;
% 对训练集进行[0,1]归一化
[train,pstrain] = mapminmax(train,pstrain);
% 测试数据处理
[test,pstest] = mapminmax(test');
% 将映射函数的范围参数分别置为0和1
pstest.ymin = 0;
pstest.ymax = 1;
% 对测试集进行[0,1]归一化
[test,pstest] = mapminmax(test,pstest);
% 对训练集和测试集进行转置,以符合libsvm工具箱的数据格式要求
train = train';
test = test';
%寻找最优c和g
%粗略选择:c&g 的变化范围是 2^(-10),2^(-9),...,2^(10)
[bestacc,bestc,bestg] = SVMcgForClass(train_group,train,-10,10,-10,10);
%精细选择:c 的变化范围是 2^(-2),2^(-1.5),...,2^(4), g 的变化范围是 2^(-4),2^(-3.5),...,2^(4)
[bestacc,bestc,bestg] = SVMcgForClass(train_group,train,-2,4,-4,4,3,0.5,0.5,0.9);
%训练模型
cmd = ['-c ',num2str(bestc),' -g ',num2str(bestg)];
model=svmtrain(train_group,train,cmd);
disp(cmd);
%测试分类
[predict_label, accuracy, dec_values]=svmpredict(test_group,test,model);
%打印测试分类结果
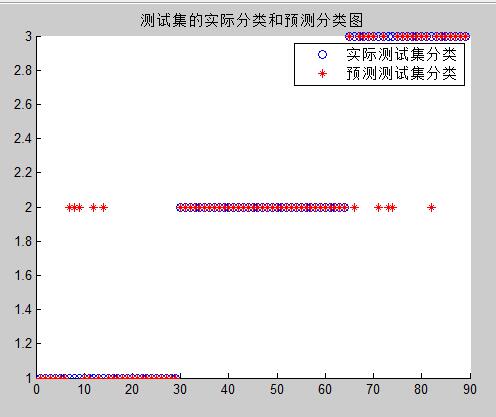
figure;
hold on;
plot(test_group,'o');
plot(predict_label,'r*');
legend('实际测试集分类','预测测试集分类');
title('测试集的实际分类和预测分类图','FontSize',10);
end
五、实验结果
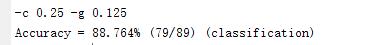
六、问题
疑惑(1)!!!!!!!!!!!!!!!!!!!!!!!!!!!!
上面的实验是参照libsvm 中的示例写的,最开始按照示例思路,但是在归一化时,自己是将训练数据和测试数据一起归一化的, 获得的精度只有61%,后来改为示例中的分别对训练数据和测试数据进行归一化后,精度就到了现在的88%,但是不理解造成此差异的原因,希望知道原因的朋友多多指教(代码如下(1)和(2))
1、训练数据和测试数据分别归一化到[0,1]代码(获得分类精度88%):
%训练数据处理
[train,pstrain] = mapminmax(train');
% 将映射函数的范围参数分别置为0和1
pstrain.ymin = 0;
pstrain.ymax = 1;
% 对训练集进行[0,1]归一化
[train,pstrain] = mapminmax(train,pstrain);
% 测试数据处理
[test,pstest] = mapminmax(test');
% 将映射函数的范围参数分别置为0和1
pstest.ymin = 0;
pstest.ymax = 1;
% 对测试集进行[0,1]归一化
[test,pstest] = mapminmax(test,pstest);
% 对训练集和测试集进行转置,以符合libsvm工具箱的数据格式要求
train = train';
test = test';2、训练数据和测试数据整体归一化到[0,1]代码(获得分类精度61%):
[mtrain,ntrain]=size(train);
[mtest,ntest]=size(test);
dataset=[train;test];
[dataset_scale,ps]=mapminmax(dataset',0,1);
dataset_scale=dataset_scale';
train=dataset_scale(1:mtrain,:);
test=dataset_scale((mtrain+1):(mtrain+mtest),:);疑惑(2)!!!!!!!!!!!!!!!!!!!!!!!!!!!!
再有就是,对于c和g这两个数值有函数可以自动调优,但是在归一化时,如下面我要是把对训练数据和测试数据分别归一化的范围从[0,1]变成[0,4],获得的分类精度就从88%提高到了96%,这种归一化的范围又该怎么确定呢?
训练数据和测试数据分别归一化到[0,4]代码(获得分类精度96%):
%训练数据处理
[train,pstrain] = mapminmax(train');
% 将映射函数的范围参数分别置为0和4
pstrain.ymin = 0;
pstrain.ymax = 4;
% 对训练集进行[0,4]归一化
[train,pstrain] = mapminmax(train,pstrain);
% 测试数据处理
[test,pstest] = mapminmax(test');
% 将映射函数的范围参数分别置为0和4
pstest.ymin = 0;
pstest.ymax = 4;
% 对测试集进行[0,4]归一化
[test,pstest] = mapminmax(test,pstest);
% 对训练集和测试集进行转置,以符合libsvm工具箱的数据格式要求
train = train';
test = test';














 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









