









GlusterFS文件系统
文章目录
什么是GlusterFS
是一种可扩展的开源分布式文件系统,可将来自多个服务器的磁盘存储资源聚合到一个全局命名空间中
Gluster将多台存储设备通过tcp/ip连接在一个全局命名空间中,统一管理。
因为tcp/ip存在网络的波动,所以需要存在双副本,设置50台为1组,当1组数据找不到了,可以找2组的数据,保证数据都能被访问到
GlusterFS标签
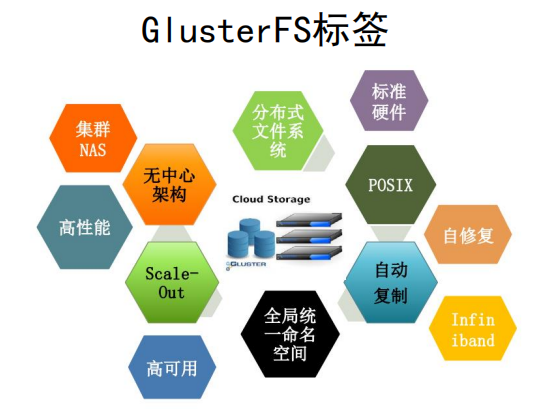
NAS集群 无中心架构 …
Gluster 特点
它是FS 文件系统,为了兼容PB级数据,它无元数据服务器
无单点故障,为了方便执行遍历操作,它把元数据存储在redis中
架构简单,使用方便
全用户空间设计,堆栈式扩展
高性能可扩展
支持多种访问协议,支持RDMA协议
什么是无集中元数据服务器
客户端在找文件的时候采用弹性哈希算法在存储池中定位数据
实现了真正的线性扩展
数据恢复简单
Gluster 扩容
在主机中存在内存硬盘等,这些在主机中是纵向层级(tree结构),为了提升Gluster 的性能,存在横向扩容和纵向扩容
横向扩容
多添加一台主机,比提升单台性能,对整体的性能提升效果更好
纵向扩容
给单台主机添加新的磁盘或者添加内存,提升单台性能
Gluster基本概念
Brick
− 文件系统挂载点
− GLusterFS存储结构单元
Translator
− 按层级提供功能
GlusterFS提供的一种强大文件系统功能扩展机制,所有的功能都通过Translator机制实现,运行时以动态库方式进行加载,服务端和客户端相互兼容
提供的功能
(1) Cluster:存储集群分布,目前有AFR, DHT, Stripe三种方式
(2) Debug:跟踪GlusterFS内部函数和系统调用
(3) Encryption:简单的数据加密实现
(4) Features:访问控制、锁、Mac兼容、静默、配额、只读、回收站等
(5) Mgmt:弹性卷管理
(6) Mount:FUSE接口实现
(7) Nfs:内部NFS服务器
(8) Performance:io-cache, io-threads, quick-read, read-ahead, stat-prefetch, sysmlinkcache, write-behind等性能优化
(9) Protocol:服务器和客户端协议实现
(10)Storage:底层文件系统POSIX接口实现
Cluster存储集群分布
DHT:(单副本)分布式集群,文件通过HASH算法分散到集群节点上,每个节点上的命名空间均不重叠,所有集群共同构成完整的命名空间,访问时使用HASH算法进行查找定位
AFR:(双副本)复制集群类似RAID1,所有节点命名空间均完全相同,每一个节点都可以表示完整的命名空间,访问时可以选择任意个节点
对比DHT多了一个分组
Stripe:条带集群与RAID0相似,所有节点具有相同的命名空间,但对象属性会有所不同,文件被分成数据块以Round Robin方式分布到所有节点上,访问时需要联动所有节点 来获得完整的名字信息
Translator数据流通过程
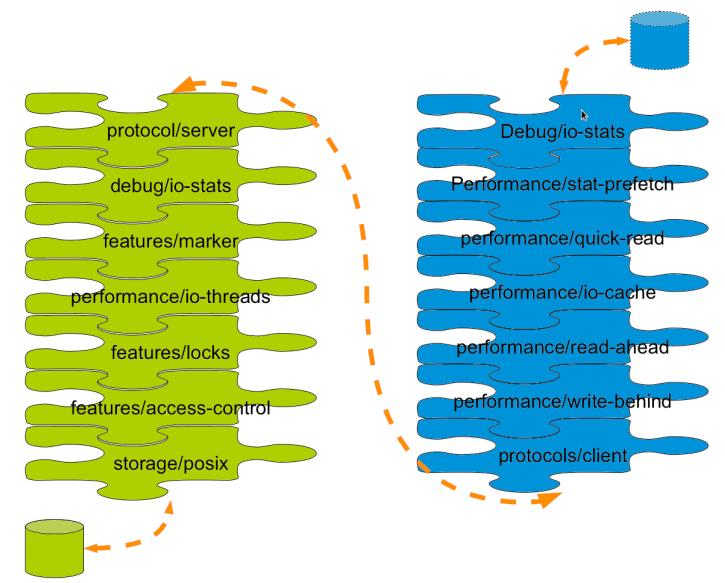
先通过IO将数据传输到Gluster的文件系统上,通过io层,预处理,读取缓存(判断是否存在缓存)、写入io缓存、制作预读、写入数据、创建Client连接 通过TCP/IP进行传输到 server端,然后经过io层、生成标识、通过io线程、对文件加锁后、经过权限控制操作基本io写入硬件中
Volume
− 由文件系统挂载点(brick)通过按层级提供功能(translator)组合而成
brick挂载出来的目录,通过Translator提供功能,生成了volume(卷)供应用使用
Node/Peer
− 运行gluster进程的服务器
Gluster外部结构
存储服务器(BrickServer)、客户端以及NFS/Samba 存储网关组成
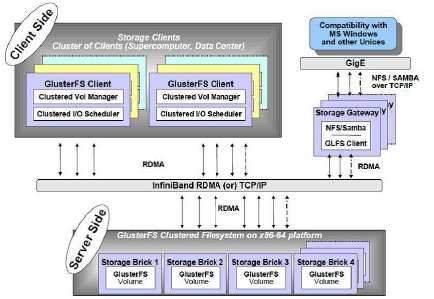
GlusterFS 架构中没有元数据服务器组件
分布式文件系统一定有服务端和客户端(一定是CS架构)
服务端为了兼容第三方系统,所以存在NFS等兼容接口
开发中也主要使用Linux原生态的NFS协议,这样扩展性更高
客户端是向服务器写入数据的一个平台
可以的存储集群磁盘管理工具,以及集群日志工具
存储集群磁盘管理工具可以添加服务端的集群磁盘的元素信息
RDMA是一个协议,通过网卡与存储磁盘通信,进行数据传输(或者使用TCP/IP)
服务段连接存储池
Gluster内部结构
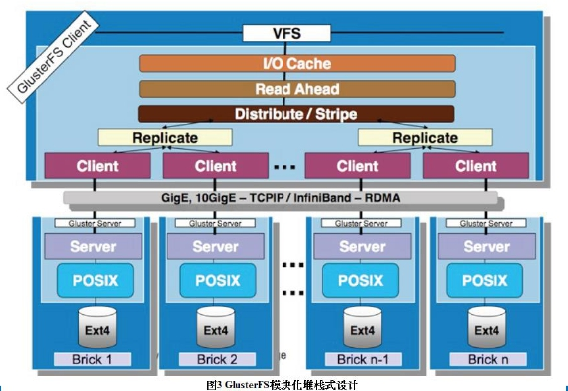
Gluster内部使用模块化堆栈式的架构设计
模块称为Translator,是GlusterFS提供的一种强大机制,借助这种良好定义的接口可以高效简便地扩展文件系统的功能
客户端通过对文件系统进行IO操作,存储在IO缓存池(IO Cache)中,再读取操作情况(Read Ahead),再进行分发(Disribute/Stripe)分配到服务器中(需要复制一个副本Repllicate 双副本),创建连接(Client)到Gluster服务器上,Gluster服务器收到连接后,转换为标准io协议(POSIX)再写入物理存储池(Ext4 Brick)
因为这些层级分类型高,开发中可以对其添加层级进行开发
GlusterFS系统组件
一共有三个重要的进程Glusterd Glusterfsd Glusterfs
还有两个工具:mount.glusterfs gluster
服务端三个进程都有作用,客户端一般只有后两个进程
Glusterd
一个后台管理进程,管理卷,运行在Server服务端上
− 弹性卷管理进程
− 运行在server上
Glusterfsd
每启动一个brick,就会有一个Glusterfsd,主要是与文件进行做交互的
− GlusterFS brick进程
− 每个brick一个进程
− 由glusterd管理
Glusterfs
NFS 网络文件系统的进程 可以提供NFS功能
− NFS server进程
− FUSE客户端进程
mount.glusterfs
FUSE本地挂载工具,可以对Gluster的卷进行管理
gluster
Gluster控制管理器
Gluster的数据访问
• Gluster本地客户端
− FUSE
• NFS
− 内置的服务
• SMB/CIFS
− 需要Samba server
Gluster访问数据的流程
1.用户通过glusterfs的mount point 来读写数据
2.这个操作被交给本地linux系统的VFS来处理
3.VFS将数据提交给FUSE内核文件系统
4.数据会被FUSE递交给Glusterfs client 客户端,客户端对数据进行一些指定的处理
5.客户端使用TCP/IP连接服务端,服务端再把请求写入到存储设备中
弹性哈希算法
GlusterFS采用的是去中心化的存储方式,文件定位在客户端即可完成。
GlusterFS在服务前端创建和客户端相同的目录结构,也就是说,任何客户端创建的文件夹,在每一个存储节点上都会对应一个真实文件夹,但是具体一个文件存在哪个节点上是需要计算得到的。
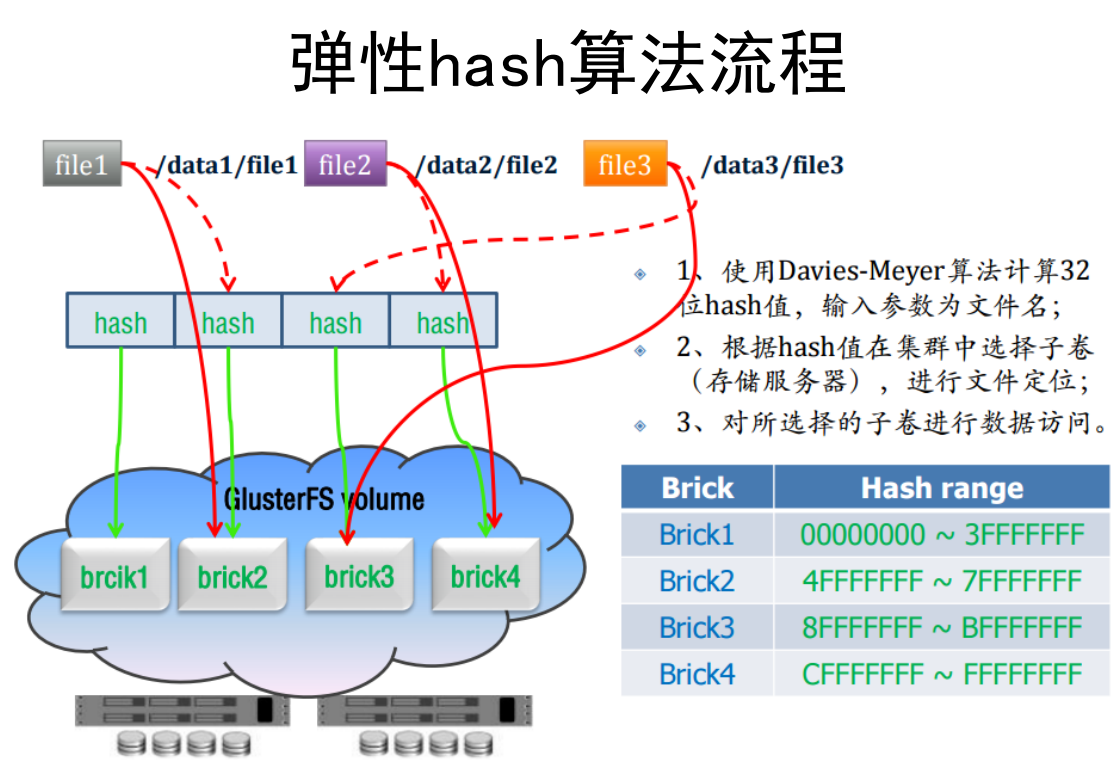
存储节点上文件定位方式
− 1. 所有的文件会被hash到一个32位的整数空间
− 2. 对于每个文件夹,存储节点上该文件夹的扩展属性里会标明该文件夹的hash range,落到该range的文件会存储到该节点上
− 3. 客户端在连接服务器端时,会要求获取某个文件夹在所有存储节点上的hash range
− 4. 访问文件时,客户端会计算该文件的hash值,然后访问对应的节点
− 5. 新增节点时,不改变已存在的文件夹的扩展属性,因此在已存在的文件夹下创建新文件时,该文件仍会放到老节点上
Gluster卷类型
基本卷
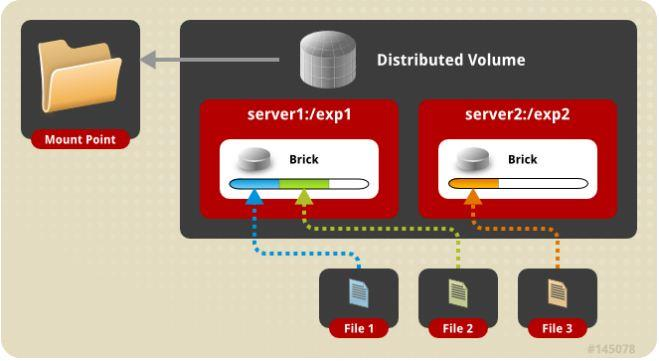
哈希卷(Distributed Volume)
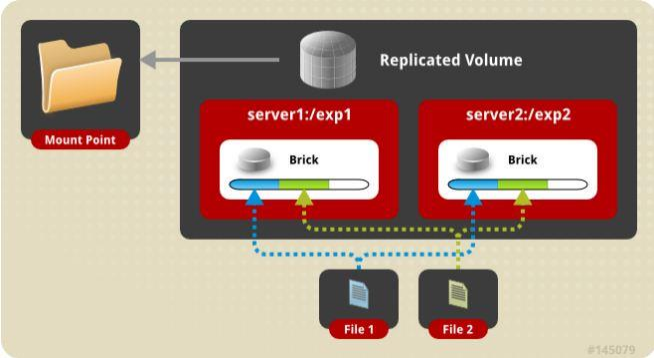
复制卷(Replicated Volume)
条带卷(Striped Volumes)
复合卷
哈希复制卷(Distributed Replicated Volume)
哈希条带卷(Distributed Striped Volume)
复制条带卷(Replicated Striped Volume)
哈希复制条带卷(Distributed Replicated Striped Volume)
哈希卷
文件通过hash算法在所有brick上分布
文件级RAID 0,不具有容错能力
复制卷
文件同步复制到多个brick上
文件级RAID 1,具有容错能力
写性能下降,读性能提升
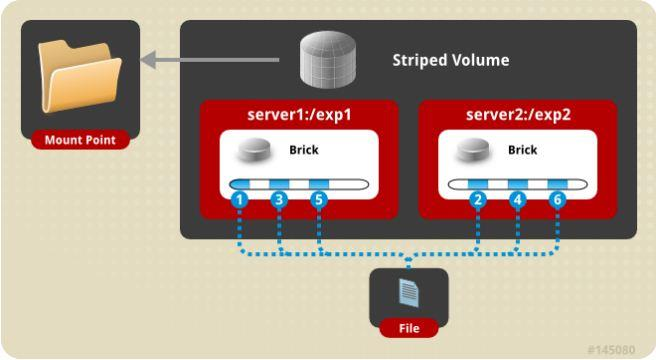
条带卷
单个文件分布到多个brick上,支持超大文件
类似RAID 0,以Round-Robin方式
通常用于HPC中的超大文件高并发访问
条带卷一般是3台
复合卷:哈希+复制
哈希卷和复制卷的复合方式
同时具有哈希卷和复制卷的特点
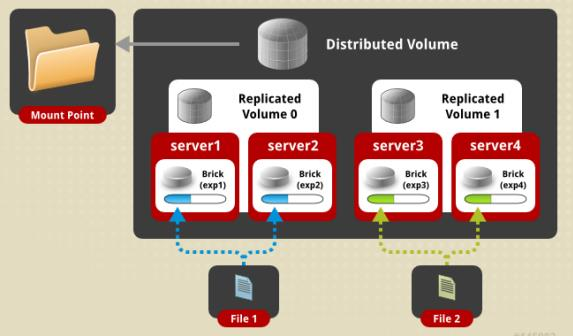
先做复制,然后再做哈希存储
如果有100台服务器,一台机子就是一个brisk,两两配置形成副本,形成50组的复制卷,再分为50组合起来生产成一个哈希卷
复合卷:哈希+条带
哈希卷和条带卷的复合方式
同时具有哈希卷和条带卷的特点
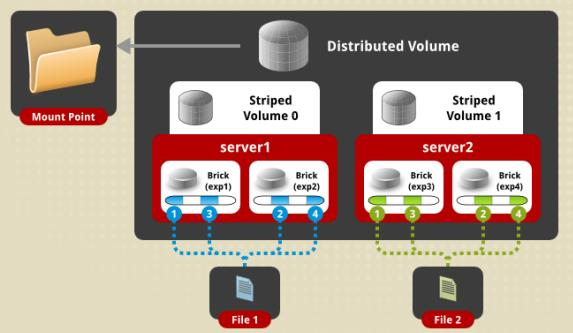
先将做条带处理,然后再做哈希存储
如果有100台服务器,一台机子就是一个brisk,两两配置形成条带,形成50组的条带卷,再分为50组合起来生产成一个哈希卷
复合卷:条带+复制
类似RAID 10
同时具有条带卷和复制卷的特点
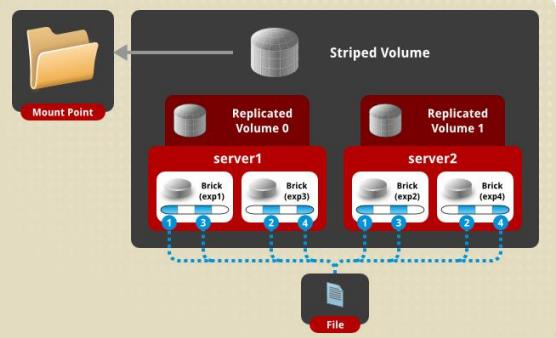
先做条带处理,然后再做复制备份
复合卷:哈希+条带+复制
三种基本卷的复合卷
通常用于类Map Reduce应用
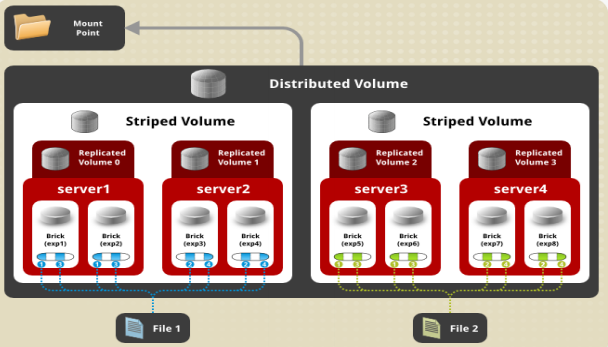
先做条带处理,然后再做复制备份,再用哈希存储
可以三台做一组条带卷,再三台做一组条带卷组成一组复制卷,组成一个哈希卷
除了复制卷至少需要2台,其他理论上一台就可以组成哈希或者条带卷,但实际上条带卷一般是3台
分布式哈希表 (DHT)
GlusterFS弹性扩展的基础
确定目标hash和brick之间的映射关系
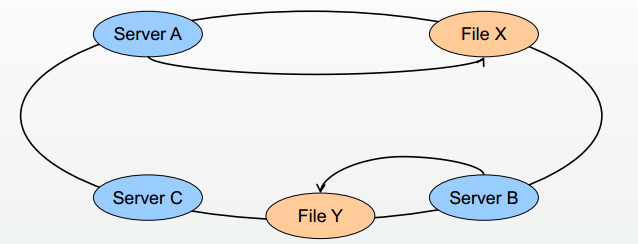
原先节点A到C总长度是1000 每个节点间隔333
插入一个节点D后A到C总长度是1000,但节点间隔变成了250
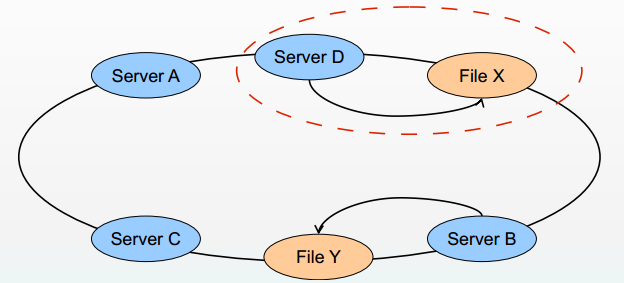
重新计算的时候,X会重新计算的在最近节点上,原先落在A服务器上,发现X离D更近,那需要重新将X文件搬移到D服务器上
容量负载均衡
添加新节点时,最小化数据重新分配
老数据分布模式(哈希值)不变,新数据分布到所有节点上
增加节点后会执行rebalance,数据重新分布到最近的服务器上
Hash范围均衡分布,节点一变动全局
目标:优化数据分布,最小化数据迁移
数据迁移自动化、智能化、并行化
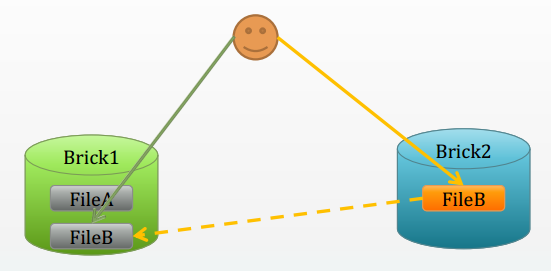
文件更名
文件更名:FileA 为 FileB时
原先的hash映射关系失效,大文件难以实时迁移
所以采用文件符号链接,访问时解析重定向
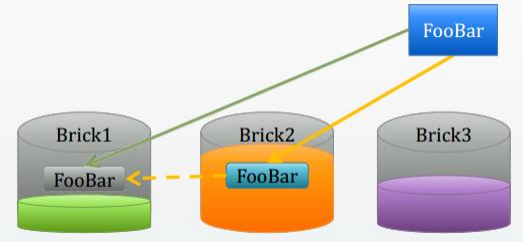
容量负载优先
设置容量阈值,优先选择可用容量充足brick
Hash目标brick上创建文件符号链接
访问时解析重定向
但文件哈希得到离Brick2近,但Brick2容量不太充足,可以将文件写在容量充足的Brick1上,创建一个重定向文件到在Brick2上,访问这个重定向文件的时候就会访问到真实存储的Brick1上
脑裂
所谓脑裂,就是指两个或多个节点都“认为”自身是正常节点而互相“指责”对方,导致不能选取正确的节点进行接管或修复,导致脑裂状态。
在写入双副本(AFR)的时候,容易出现数据不一致的情况,两个节点不知道哪个数据是正常的,就发生了脑裂
在大量小文件写入上就通常会发现脑裂,因为小文件写入快,判断时间短,容易出错
解决方法:
1、报错处理 反馈给用户,让用户自己选择保留
2、Quorum方法(N=2?) 如果三份里面2份一致的,那就选择2份一致的情况
3、仲裁机制(一般判断时间戳,大概率选择后面写入的文件)
Gluster设计讨论
无元数据服务器 vs 元数据服务器
优点
没有单点故障和性能瓶颈问题,可提高系统扩展性、性能、可靠性和稳定性。有利于解决海量小文件元数据难点问题
如果几台坏了,那么可以从之后的机子找到数据,如果有元数据的服务器坏了,那就找不回数据
缺点
数据一致问题更加复杂,文件目录遍历操作效率低下,缺乏全局监控,管理功能。
导致客户端承担了更多的职能,比如文件定位、名字空间缓存、逻辑卷视图维护等等,这些都增加了客户端的负载,占用相当的CPU和内
存
结论
哈希找文件的时候,需要找文件的全名的
文件遍历的情况,比如输入ls,它要到全部服务器去读取一遍,才能得出结果
为了解决这个问题,需要多加一个元数据的服务器对Gluster做辅助作用,专门对ls这样的操作做处理
用户空间 vs 内核空间
用户空间优点
用户空间实现起来相对要简单许多,对开发者技能要求较低,运行相对安全。
用户空间缺点
用户空间效率低,数据需要多次与内核空间交换,另外GlusterFS借助FUSE来实现标准文件系统接口,性能上又有所损耗。
内核空间优点
内核空间实现可以获得很高的数据吞吐量
内核空间缺点
实现和调试非常困难,程序出错经常会导致系统崩溃,安全性低
纵向扩展上,内核空间要优于用户空间,GlusterFS有横向扩展能力来弥补
堆栈式 vs 非堆栈式
GlusterFS堆栈式设计开开发更灵活,一层一层开发
非堆栈式设计可看成类似Linux的单一内核设计,系统调用通过中断实现,非常高效,但是系统核心臃肿,实现和扩展复杂,出现问题调试困难
原始存储格式 vs 私有存储格式
GlusterFS使用原始格式存储文件或数据分片,可以直接使用各种标准的工具进行访问,数据互操作性好,迁移和数据管理非常方便
数据是以平凡的方式保存的,接触数据的人可以直接复制和查看,存在数据安全问题。
GlusterFS要实现自己的私有格式,在设计实现和数据管理上相对复杂一些,也会对性能产生一定影响。
大文件 vs 小文件
GlusterFS适合存储大文件,小文件性能较差,还存在很大优化空间。
弹性哈希算法和Stripe数据分布策略,移除了元数据依赖,优化了数据分布,提高数据访问并行性,能够大幅提高大文件存储性能。
对于小文件,无元数据服务设计解决了元数据的问题
但GlusterFS并没有在I/O方面作优化,在存储服务器底层文件系统上仍然是大量小文件,本地文件系统元数据访问是一个瓶颈,数据分布和并行性也无法充分发挥作用。
可用性 vs 存储利用率
可用性与存储利用率是一个矛盾体,可用性高存储利用率就低,反之亦然
采用复制技术,存储利用率为1/复制数,镜像是50%,三路复制则只有33%
RAID5的利用率是(n-1)/n,RAID6是(n-2)/n,而纠删码技术可以提供更高的存储利用率
鱼和熊掌不可得兼,会对性能产生较大影响
一些参考
http://www.gluster.org/community/documentation/index.php
https://github.com/anoopcs9/glusterfs
刘爱贵的GlusterFS专栏:
http://blog.csdn.net/liuaigui

















 966
966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











