







第十章 模块及常用的第三方模块
模块的简介
模块:
- 在Python中一个后缀名为 .py 的 Python 文件就是一个模块
- 模块中可以定义函数、类等
- 模块也可以避免函数、类、变量等名称相冲突的问题
- 模块不仅提高了代码的可维护性,同时还提高了代码的可重用性
- 在给模块命名的时候要求全部使用小写字母,多个单词之间使用下划线进行分隔
- 如果自定义模块名称与系统内置模块名称相同,那么在导入时会优先导入自定义的模块
模块的分类:
- 系统内置模块:由开发人员编写好的模块,在安装Python解释器时一同安装到计算机中
- 自定义模块:一个以 .py 结尾的文件就是一个模块,新建Python文件,实际上就是在新建模块
- 第三方模块
自定义模块的作用:
- 一是规范代码,将功能相同的函数、类等封装到一个模块中,让代码更易于阅读
- 另外一个目的与系统内置模块相同,即可以被其他模块调用,提高开发的效率
模块的导入
模块编写完成就可以被其他模块进行调用并使用被调用模块中的功能。
import导入方式的语法结构 [ 方括号里的内容可以省略 ]:
import 模块名称 [as 别名]
这种方式下调用该模块中的功能时需要 模块名.功能 ,即使用模块名进行打点调用 [使用别名后就用别名进行打点调用]。
from…import导入方式的语法结构:
from 模块名称 import 变量/函数/类/*
这种方式下调用该模块中的功能时不再需要进行模块名打点调用,可以直接使用。
如果想要一次导入多个模块时,模块之间可以用逗号进行分隔。
新建一个模块 my_info.py ,内容如下:
name = 'lxl'
def info():
print(f'大家好,我叫{name}')
导入该模块:
# (1)import...
import my_info
print(my_info.name)
my_info.info()
# 给模块起别名
import my_info as a
print(a.name)
a.info()
# (2)from...import...
from my_info import name # 导入的是一个具体的变量的名称
print(name)
from my_info import info # 导入的是一个具体的函数的名称
info()
from my_info import *
print(name)
info()
# 同时导入多个模块,用逗号分隔
import math, time, random

注意:
导入模块中具有同名的变量和函数,后导入的会将之前导入的进行覆盖。如果不想覆盖,解决方案,可以使用 import 进行导入。这时使用模块中的函数或变量时,模块名打点调用。
再新建一个模块 introduce.py ,内容如下:
name = 'wz'
age = 18
def info():
print(f'大家好,我叫{name},年龄{age}岁')
与模块 my_info.py 有同名属性 name,和同名方法 info( ) 。
导入两个模块:
from my_info import *
from introduce import *
# 导入模块中具有同名的变量和函数,后导入的会将之前导入的进行覆盖
info()
# 如果不想覆盖,解决方案,可以使用import
import my_info
import introduce
# 使用模块中的函数或变量时,模块名打点调用
my_info.info()
introduce.info()

Python中的包
包:
- 含有__init__.py 文件的文件夹(目录)
- 可以避免模块名称相冲突的问题
可以将功能相似的模块放入一个包中进行管理,方便模块的组织和管理。
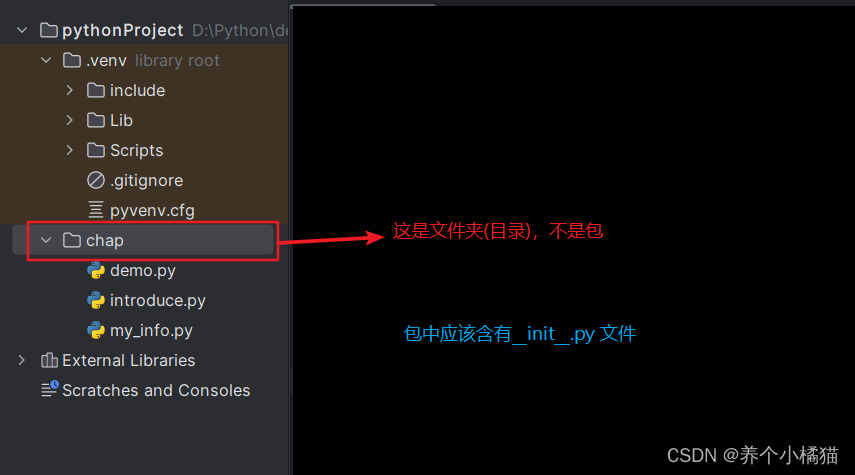
在Pycharm中新建包:
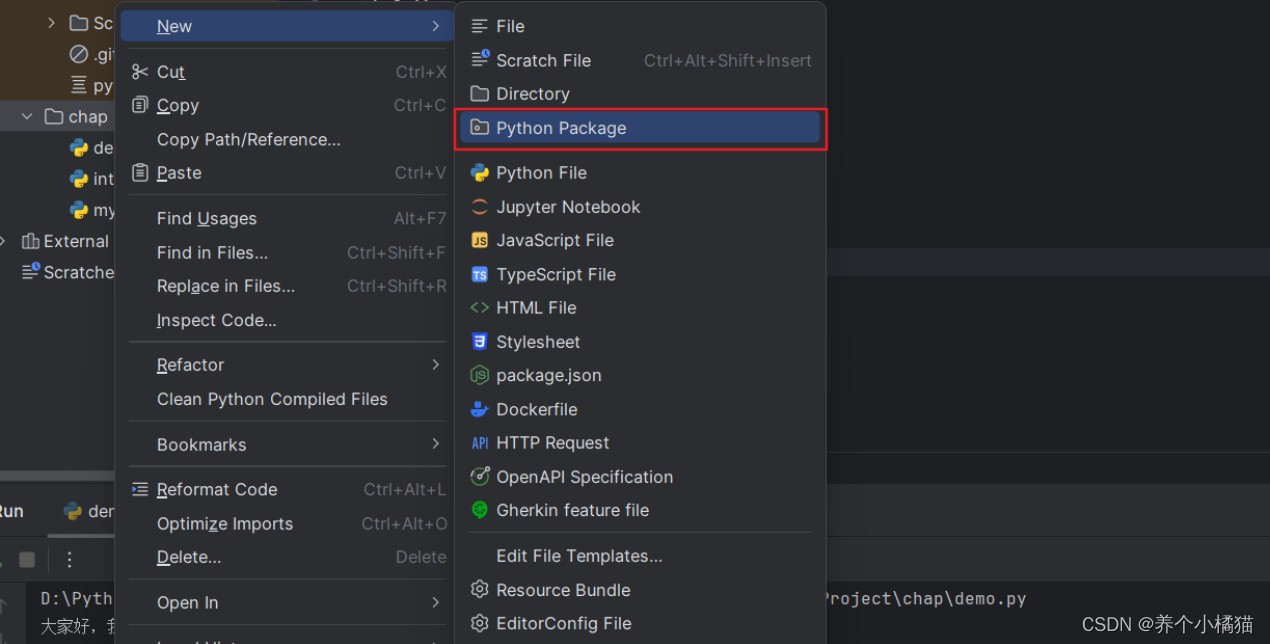
要遵循包的命名规范。
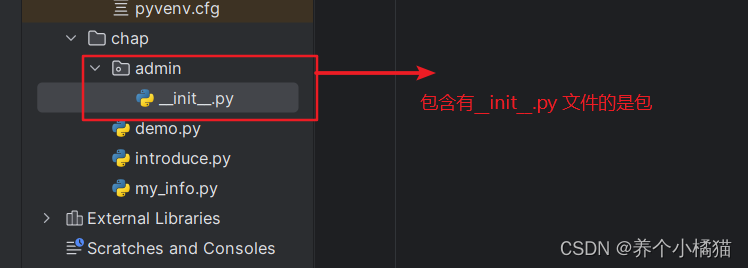
__init__.py 文件中可以写代码也可以不写代码。
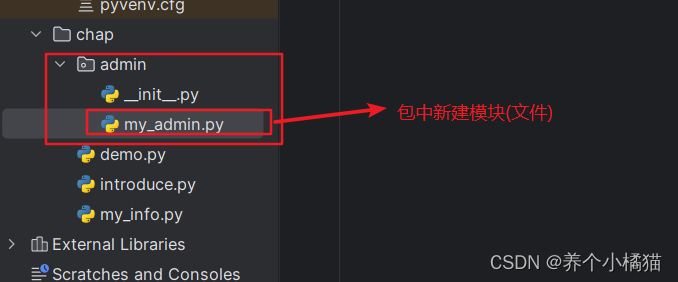
在__init__.py 文件中写如下代码:
# 在__init__.py文件中可以写代码,也可以不写代码
print('版权:lxl')
在包admin的my_admin.py 文件中写如下代码:
name = 'lxl'
def info():
print(f'大家好,我叫{name}')
导入包中的模块:
# 导入包中的模块
import admin.my_admin as a # 包名.模块名 admin是包名,my_admin是模块名
a.info()
# 当包被导入的时候,__init__.py 文件中的代码会自动被调用执行,但仅会执行一次
print('-' * 30)
from admin import my_admin as b # from 包名 import 模块 as 别名
b.info()
print('-' * 30)
from admin.my_admin import info # from 包名.模块名 import 函数/变量等
info()
print('-' * 30)
from admin.my_admin import * # from 包名.模块名 import *
print(name)

注意:
当包被导入的时候,__init__.py 文件中的代码会自动被调用执行,但仅会执行一次。
主程序运行
主程序运行:
if __name__ == ‘__main__’ :
pass
新建两个文件module_a.py和module_b.py:
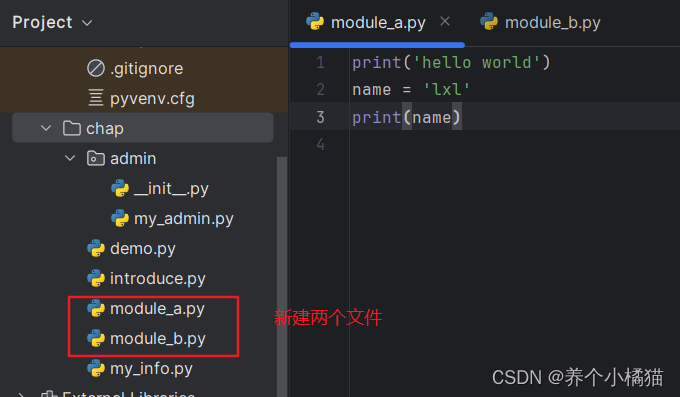
module_a.py中的内容:
print('hello world')
name = 'lxl'
print(name)
module_b.py中的内容:
# 导入的代码
import module_a
运行module_b.py后的结果是:

意思是执行了module_a.py 中的print输出语句。
如果不希望module_a.py中的print输出语句跟着被导入后一起输出,这时就可以在module_a.py中使用主程序运行。
使用主程序运行,对module_a.py中的代码作如下修改:
if __name__ == '__main__':
print('hello world')
name = 'lxl'
print(name)
此时再运行module_b.py则module_a.py中的print输出语句不会再被执行。
主程序运行的作用:
放入主程序运行中的代码被导入其他模块中不会执行。
Python中常用的内置模块
在安装Python解释器时与解释器一起安装进来的模块被称为系统内置模块,也被称为标准模块或标准库。
| 标准库名称 | 功能描述 |
|---|---|
| os模块 | 与操作系统和文件相关操作有关的模块 |
| re模块 | 用于在Python的字符串中执行正则表达式的模块 |
| random模块 | 用于产生随机数的模块 |
| json模块 | 用于对高维数据进行编码和解码的模块 |
| time模块 | 与时间相关的模块 |
| datetime模块 | 与日期时间相关的模块,可以方便的显示日期并对日期进行计算 |
random模块中常用函数的使用
random模块是Python中用于产生随机数的标准库。
| 函数名称 | 功能描述 |
|---|---|
| seed(x) | 初始化给定的随机数种子,默认为当前系统时间 |
| random() | 产生一个 [0.0,1.0) 之间的随机小数 |
| randint(a,b) | 生成一个 [a,b] 之间的整数 |
| randrange(m,n,k) | 生成一个 [m,n) 之间步长为k的随机整数 |
| uniform(a,b) | 生成一个 [a,b] 之间的随机小数 |
| choice(seq) | 从序列中随机选择一个元素 |
| shuffle(seq) | 将序列seq中元素随机排序,返回打乱后的序列 |
# 导入
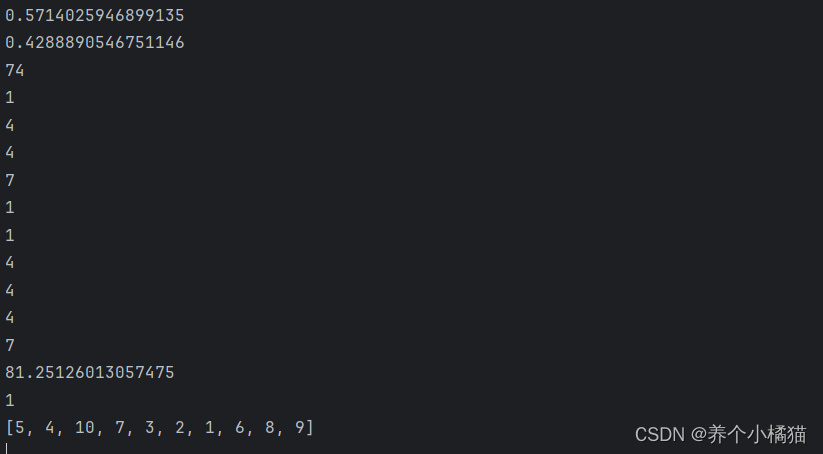
import random
# 设置随机数的种子,默认为当前系统时间
random.seed(10)
print(random.random()) # [0.0,1.0)
print(random.random())
# 随机数种子相同产生的随机数也相同--->无论运行多少次,产生的随机数是一样的
random.seed(10)
print(random.randint(1, 100)) # [1,100]
for i in range(10): # [m,n),步长为k
print(random.randrange(1, 10, 3)) # 执行了10次
print(random.uniform(1, 100)) # [a,b]随机小数
# 列表生成式
lst = [i for i in range(1, 11)]
print(random.choice(lst)) # lst是列表,称为序列
# 随机的排序
random.shuffle(lst)
print(lst)
time模块中常用的函数
time模块是Python中提供的用于处理时间的标准库,可以用来进行时间处理、时间格式化和计时等。
| 函数名称 | 功能描述 |
|---|---|
| time() | 获取当前时间戳 |
| localtime(sec) | 获取指定时间戳对应的本地时间的struct_time对象 |
| ctime() | 获取当前时间戳对应的易读字符串 |
| strftime() | 格式化时间,结果为字符串 |
| strptime() | 提取字符串的时间,结果为struct_time对象 |
| sleep(sec) | 休眠sec秒 |
除了以上常用的函数外,还有配合time模块使用的格式化字符串:
| 格式化字符串 | 日期/时间 | 取值范围 |
|---|---|---|
| %Y | 年份 | 0001~9999 |
| %m | 月份 | 01~12 |
| %B | 月名 | January~December |
| %d | 日期 | 01~31 |
| %A | 星期 | Monday~Sunday |
| %H | 小时(24h制) | 00~23 |
| %I | 小时(12h制) | 01~12 |
| %M | 分钟 | 00~59 |
| %S | 秒 | 00~59 |
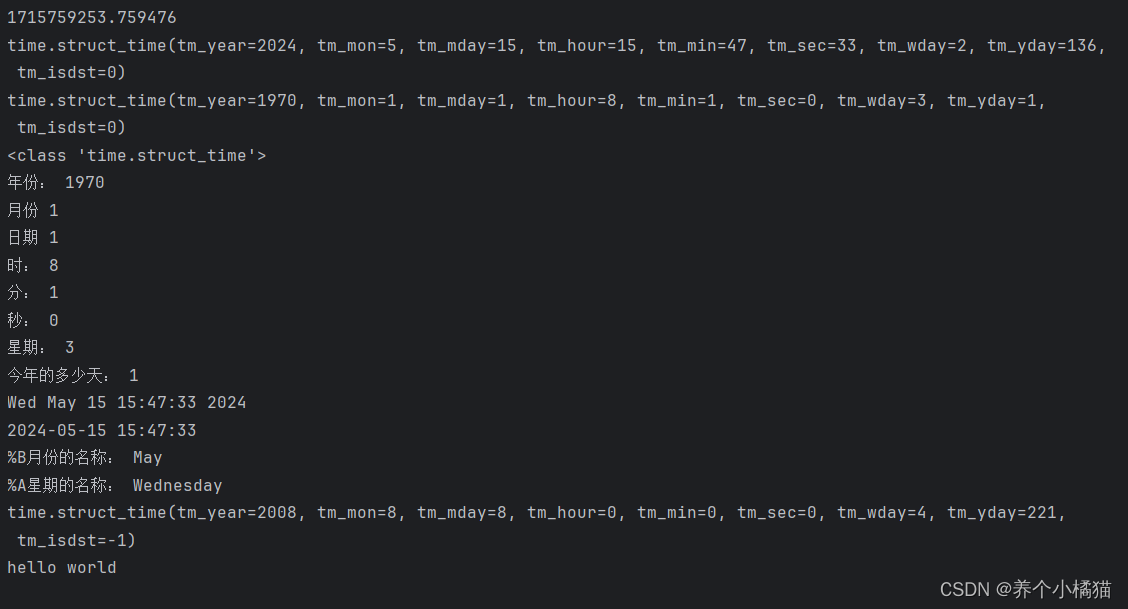
import time
# time() 获取当前时间戳
now = time.time()
print(now)
obj = time.localtime() # struct_time对象
print(obj)
'''
localtime(sec) 获取指定时间戳对应的本地时间的struct_time对象
时间戳从 1970-01-01 00:00:00 开始计算
【localtime(sec) 获取指定时间戳对应的“本地时间”的struct_time对象】
本地时间:北京时间是东八区,故从 1970-01-01 08:00:00 开始计算
'''
obj2 = time.localtime(60) # 60秒
print(obj2)
print(type(obj2))
print('年份:', obj2.tm_year)
print('月份', obj2.tm_mon)
print('日期', obj2.tm_mday)
print('时:', obj2.tm_hour)
print('分:', obj2.tm_min)
print('秒:', obj2.tm_sec)
print('星期:', obj2.tm_wday) # [0,6] 0表示星期一; 1表示星期二
print('今年的多少天:', obj2.tm_yday)
# ctime() 获取当前时间戳对应的易读字符串
print(time.ctime()) # Wed May 15 15:36:52 2024
# 日期时间格式化(将时间转成字符串)
# 将struct_time对象转成字符串--->str,格式化format--->f,时间--->time。故为strftime
# 注意:分隔符不同。年-月-日 时:分:秒
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
print('%B月份的名称:', time.strftime('%B', time.localtime()))
print('%A星期的名称:', time.strftime('%A', time.localtime()))
# 将字符串转成struct_time对象(时间)
print(time.strptime('2008-08-08', '%Y-%m-%d'))
time.sleep(5) # 程序暂停5秒
print('hello world')
datetime模块
time模块可以进行时间的处理、时间格式化以及计时等等。但是在计算时间间隔上却不如datetime模块好用方便。
datetime模块可以更方便的显示日期并对日期进行运算。
datetime模块中常用的与时间相关的有5个类:
| 类名 | 功能描述 |
|---|---|
| datetime.datetime | 表示日期时间的类 |
| datetime.timedelta | 表示时间间隔的类 |
| datetime.date | 表示日期的类 |
| datetime.time | 表示时间的类 |
| datetime.tzinfo | 时区相关的类 |
最常用的是datetime.datetime与datetime.timedelta类。
datetime类的使用
datetime类(指datetime.datetime)结合了date类和time类的特点,在datetime类的对象中表示的是某个时刻,所以该对象中包含了 年、月、日;时、分、秒以及微秒等属性。
在datetime类(指datetime.datetime)中有一个方法datetime.now()可以用于获取当前的日期和时间。
from datetime import datetime # 从datetime模块中导入datetime类
# datetime.now()获取当前的系统时间
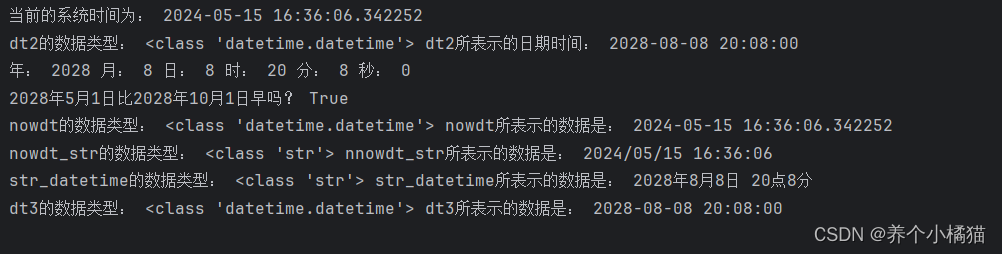
dt = datetime.now()
print('当前的系统时间为:', dt) # 2024-05-15 16:13:59.703922--->年-月-日 时:分:秒.微秒
# datetime是一个类,手动创建这个类的对象
dt2 = datetime(2028, 8, 8, 20, 8)
print('dt2的数据类型:', type(dt2), 'dt2所表示的日期时间:', dt2)
print('年:', dt2.year, '月:', dt2.month, '日:', dt2.day, '时:', dt2.hour, '分:', dt2.minute, '秒:', dt2.second)
# 比较两个datetime类型对象的大小--->直接用 大于号、小于号
labor_day = datetime(2028, 5, 1, 0, 0, 0)
national_day = datetime(2028, 10, 1, 0, 0, 0)
print('2028年5月1日比2028年10月1日早吗?', labor_day < national_day) # True
# time可以与字符串进行转换,datetime类型亦可以与字符串进行转换
# datetime--->字符串,也是用到strftime()方法【time中也是这个方法】
nowdt = datetime.now()
nowdt_str = nowdt.strftime('%Y/%m/%d %H:%M:%S')
print('nowdt的数据类型:', type(nowdt), 'nowdt所表示的数据是:', nowdt)
print('nowdt_str的数据类型:', type(nowdt_str), 'nnowdt_str所表示的数据是:', nowdt_str)
# 字符串--->datetime类型,也是用到strptime()方法【time中也是这个方法】
str_datetime = '2028年8月8日 20点8分'
dt3 = datetime.strptime(str_datetime, '%Y年%m月%d日 %H点%M分')
print('str_datetime的数据类型:', type(str_datetime), 'str_datetime所表示的数据是:', str_datetime)
print('dt3的数据类型:', type(dt3), 'dt3所表示的数据是:', dt3)
timedelta类的使用
timedelta类可以很方便的在 日期上进行添小时、分钟、秒、毫秒的加减运算,但是不能进行年、月加减运算。
timedelta类可以进行 “datetime类型对象” 之间的加减运算。
from datetime import datetime
from datetime import timedelta
# timedelta类可以进行“datetime类型对象”之间的加减运算
# 创建两个datetime类型的对象
delta1 = datetime(2028, 10, 1) - datetime(2028, 5, 1)
print('delta1的数据类型是:', type(delta1), 'delta1所表示的数据是:', delta1)
print('2028年5月1日之后的153天是:', datetime(2028, 5, 1) + delta1)
# 通过传入参数的方式手动创建一个timedelta对象
td1 = timedelta(10)
print('创建一个10天的timedelta对象:', td1)
td2 = timedelta(10, 11)
print('创建一个10天11秒的timedelta对象:', td2)

第三方模块的安装与卸载
第三方模块由全球Python爱好者、程序员、各行各业的专家进行开发并进行维护。
安装第三方模块的语法:
pip install 模块名称
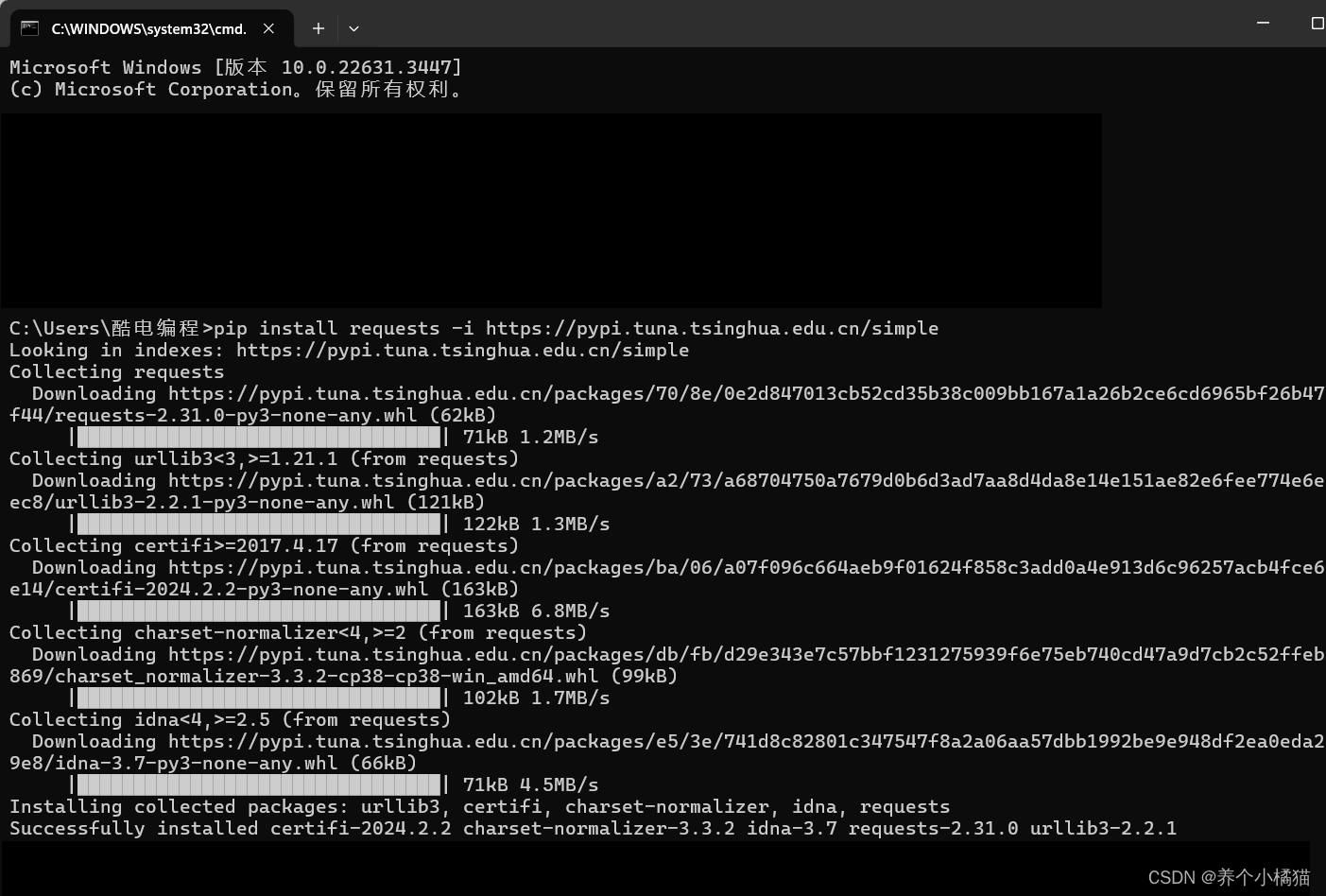
加快安装速度可以使用国内镜像源:
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
使用镜像源的语法:
pip install 模块名称 -i 镜像源
卸载第三方模块的语法:
pip uninstall 模块名称
升级pip命令的语法:
python -m pip install --upgrade pip
升级pip命令的语法中 python 指的是 python.exe 这个文件。
pip是一个命令,实际上是一个pip.exe文件:
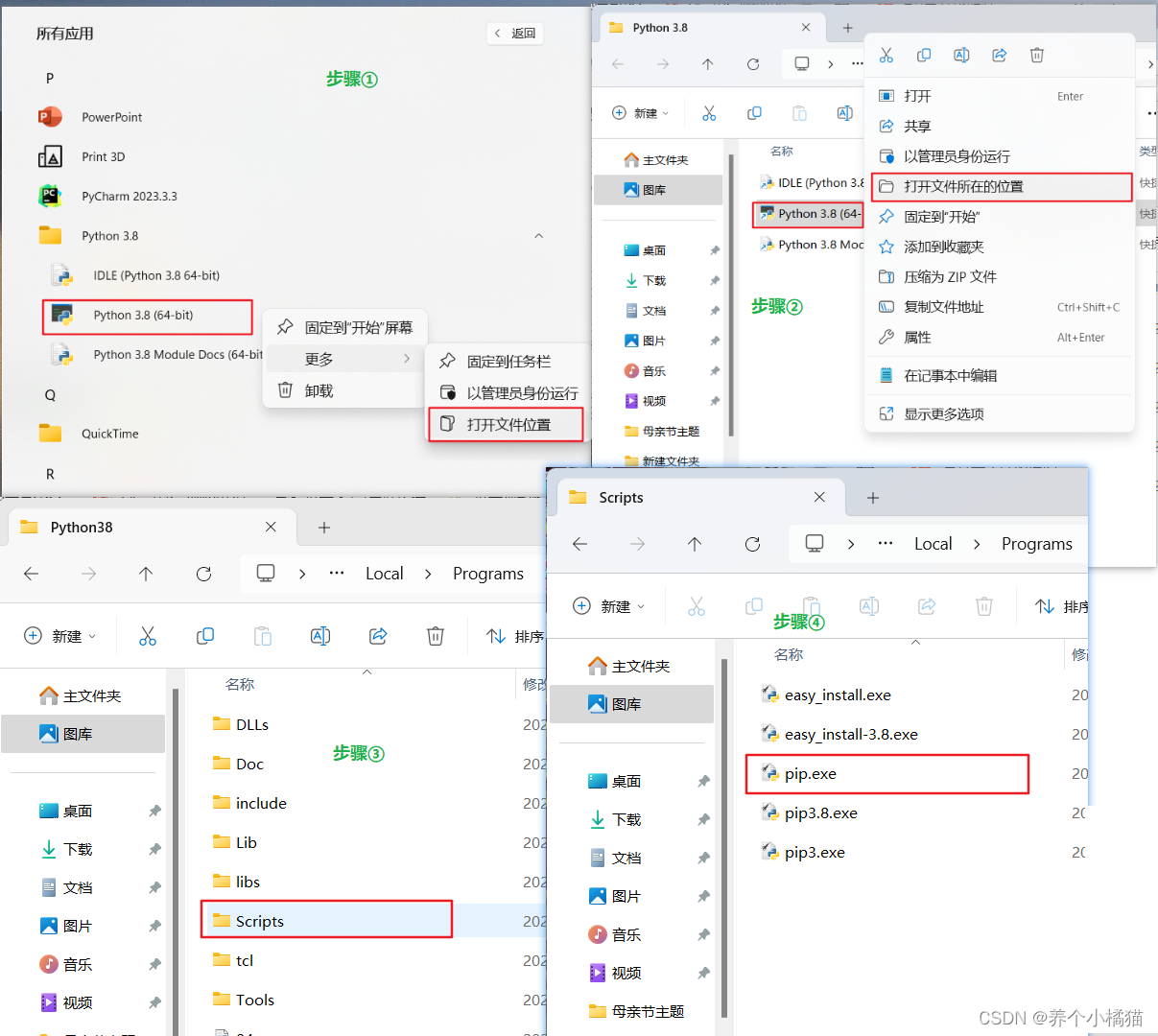
安装第三方模块步骤(以安装爬虫模块requests为例,使用清华镜像源):
升级pip命令:

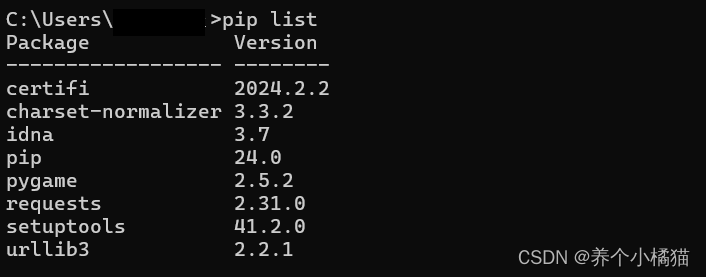
可以使用 pip list 命令查看已安装的第三方模块:
PyCharm第三方模块设置
在PyCharm中可以直接安装第三方模块:
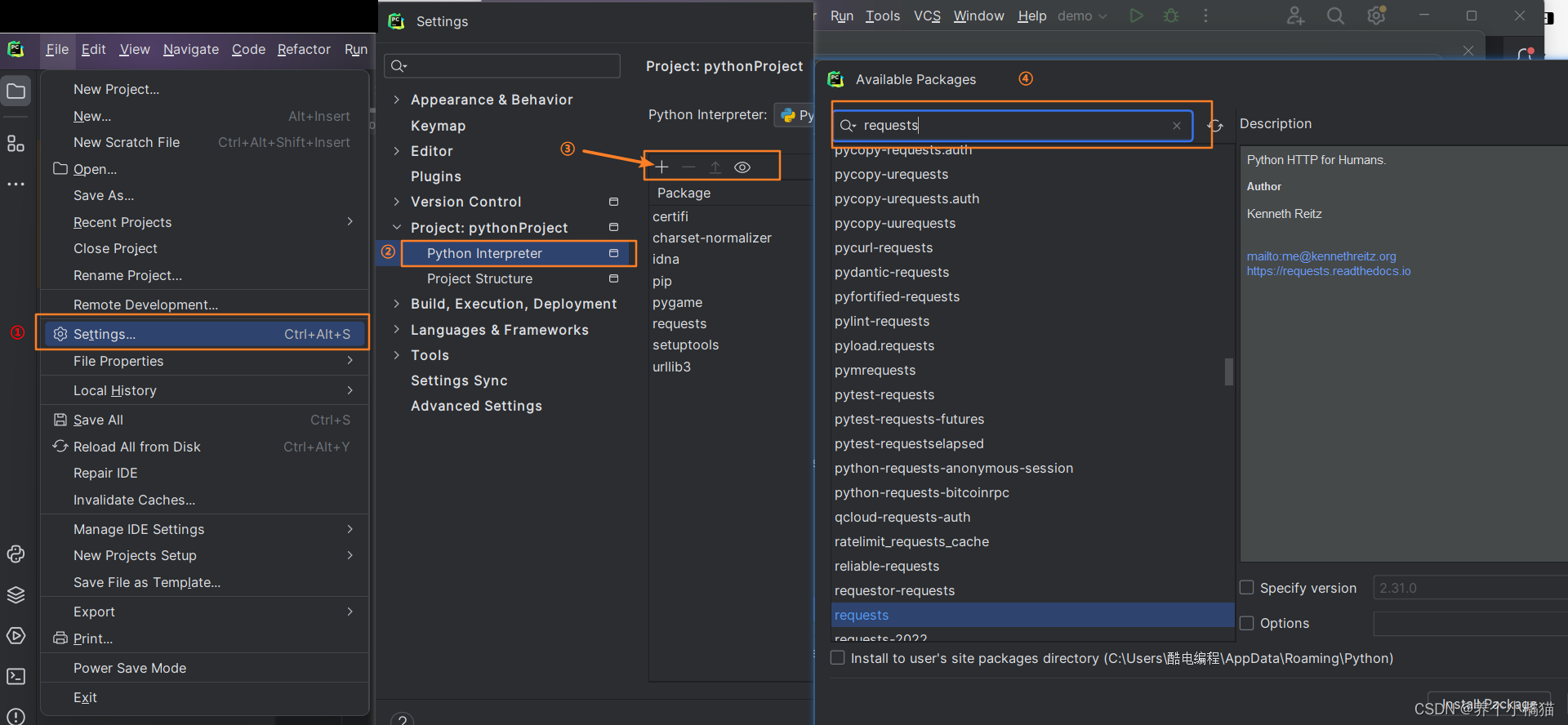
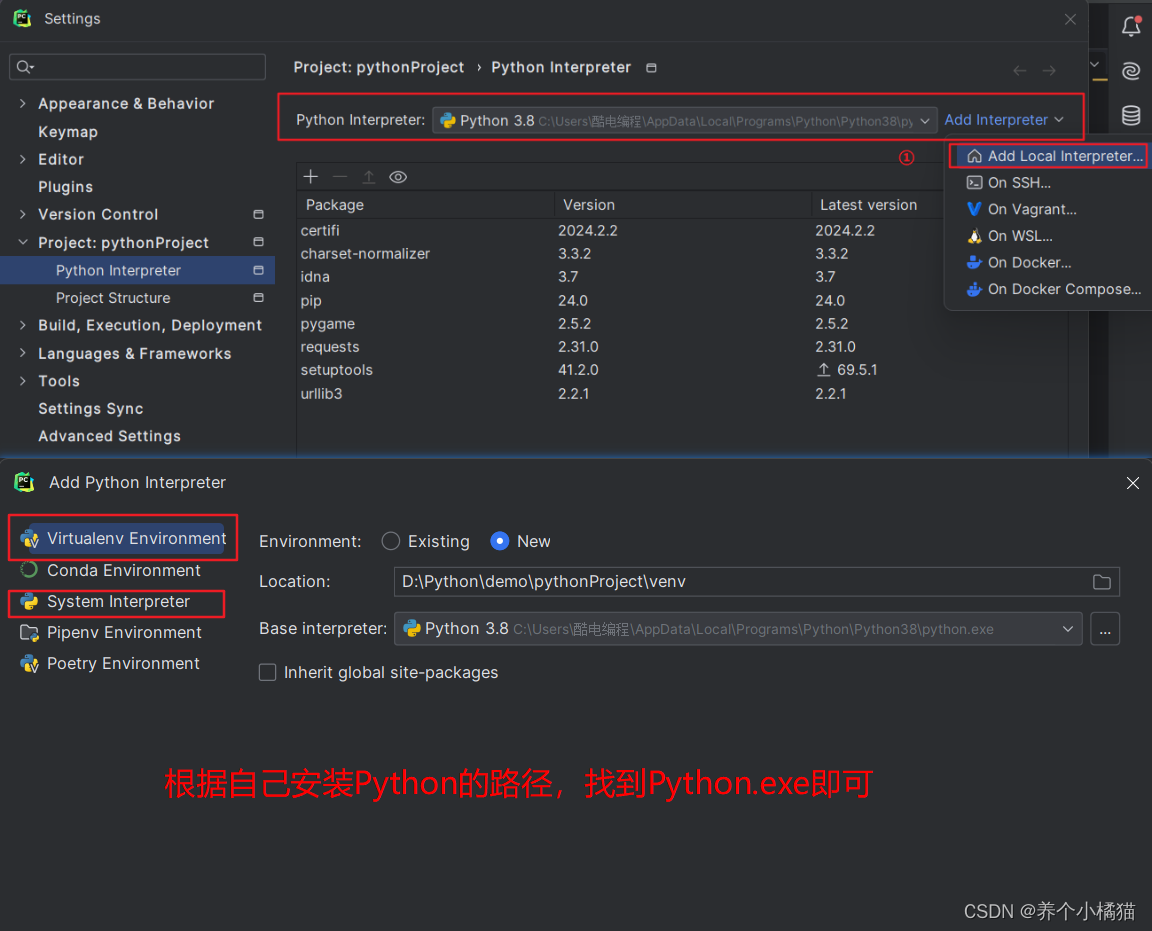
事实上如果在计算机中使用 pip 命令安装过第三方模块之后在PyCharm中便不必再安装,但是有时在计算机中使用 pip 命令安装过第三方模块之后发现在PyCharm中找不到所安装的模块,这种情况一般都是环境配置错误,只需配置一下即可:
requests模块的使用
requests模块:
- 被称为requests库,是用于处理HTTP(Hypertext Transfer Protocol超文本传输协议)请求的第三方库,该库在爬虫程序中应用非常广泛。
- 使用requests库中的get()函数可以打开一个网络请求,并获取一个Response响应对象。响应结果中的字符串数据可以通过响应对象的text属性获取,响应结果中除了有字符串数据也有二进制数据,响应结果中的二进制数据可以通过响应对象的content属性获取。
简单的爬虫程序(爬取字符串数据即文本数据),提取天气预报中的景区天气。天气预报网址:http://www.weather.com.cn/weather1d/101010100.shtml。
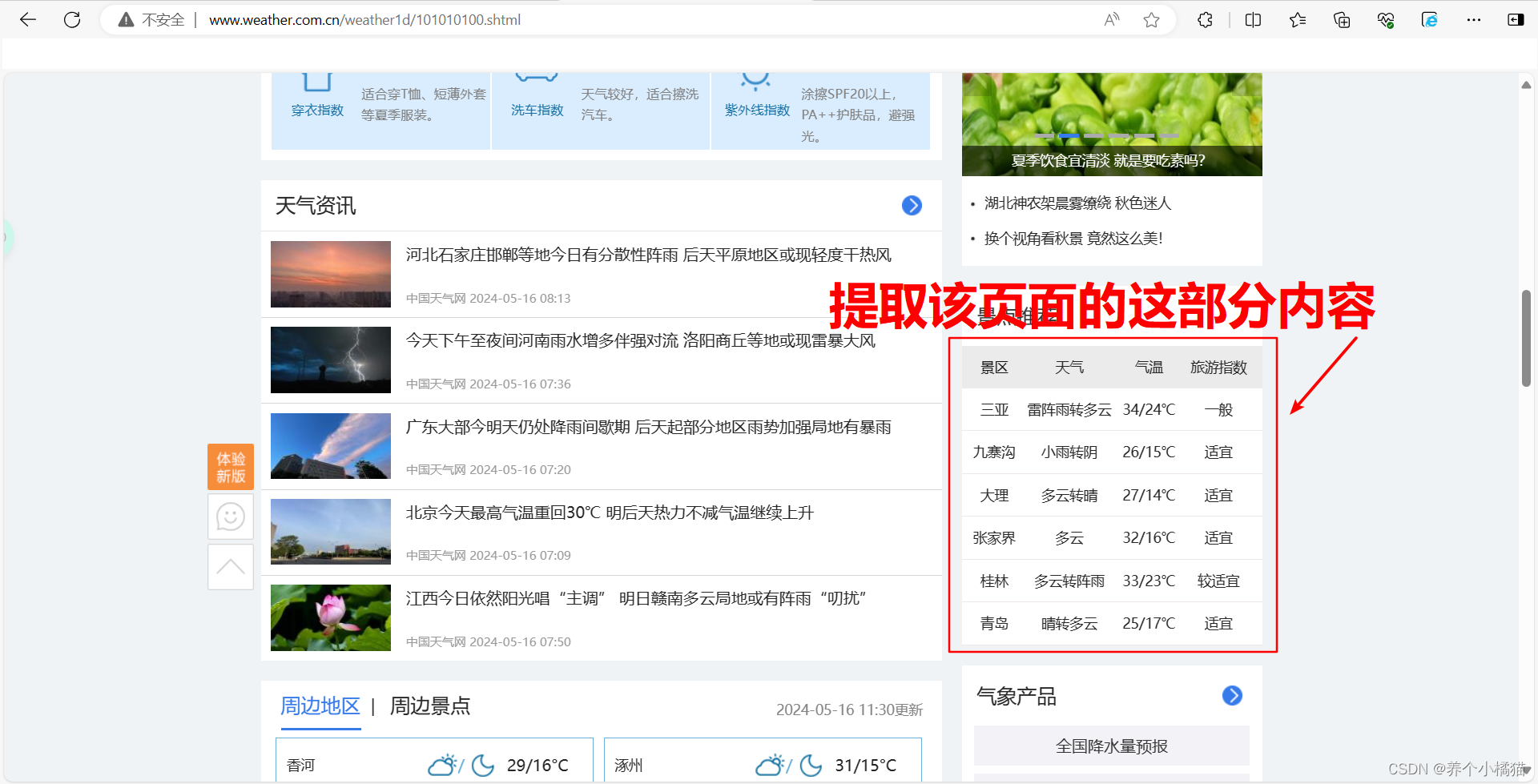
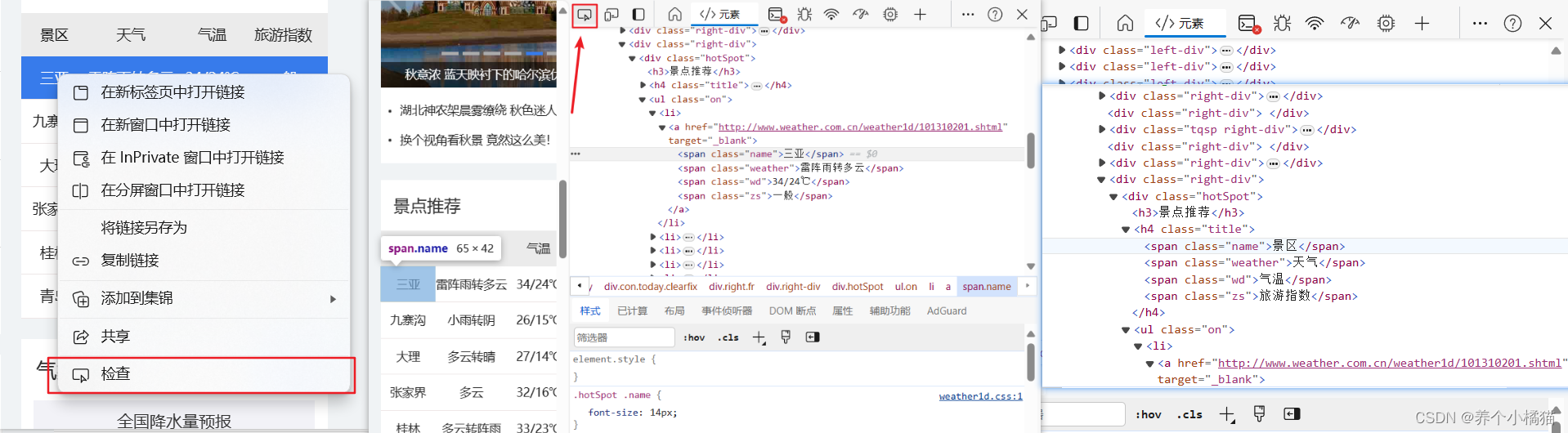
经过观察发现,只需提取出<span>标签中的中文即可:
<span class=“name”>景区</span>
<span class=“weather”>天气</span>
<span class=“wd”>气温</span>
<span class=“zs”>旅游指数</span>
import requests # 爬虫模块
import re # 正则表达式
# 需要告知程序所要打开的网页是什么(网址)
url = 'http://www.weather.com.cn/weather1d/101010100.shtml' # 爬虫打开的浏览器上的网页
resp = requests.get(url) # 打开浏览器并打开网址(返回Response响应对象)
# 设置编码格式(目的是查看中文)
resp.encoding = 'utf-8'
print(resp.text) # resp-->响应对象 对象名.属性名
'''
可以看到得到的resp.text字符串是一个html页面,只想要该页面中的景区的天气预报数据,
则需要从返回的字符串中提取出景区、天气、气温、旅游指数。
从一堆字符串中提取想要的数据,则需要用到正则表达式。
提取出<span>标签中的内容
<span class="name">景区</span>
<span class="weather">天气</span>
<span class="wd">气温</span>
<span class="zs">旅游指数</span>
'''
# (re) 对正则表达式分组并记住匹配的文本
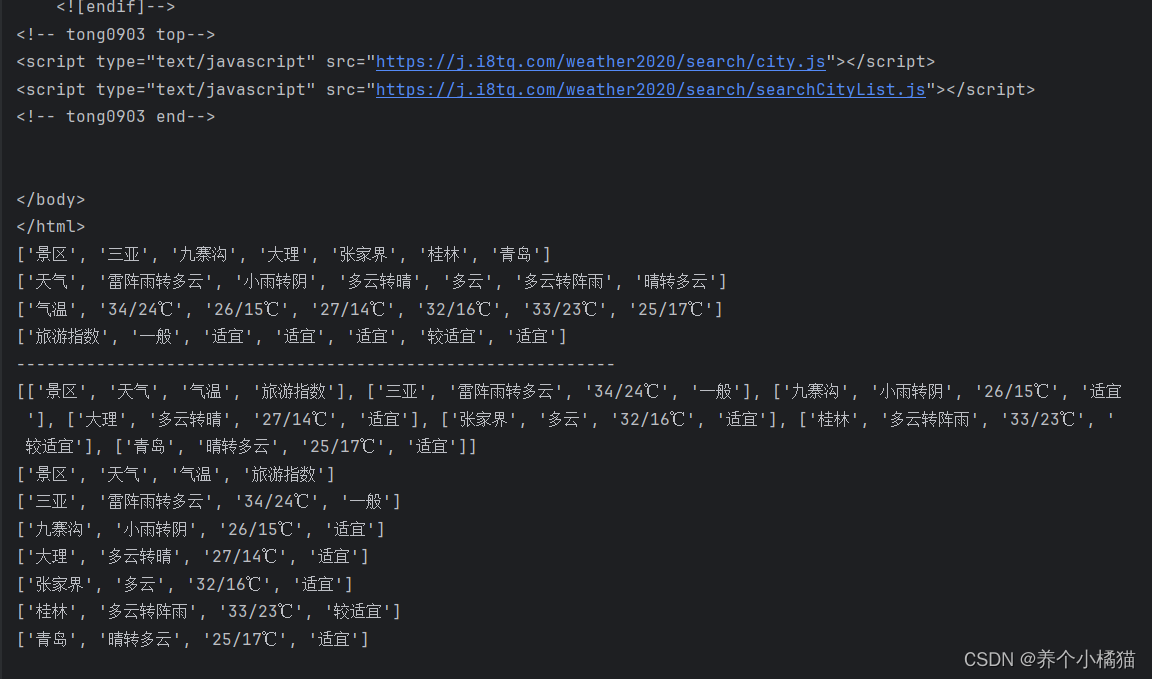
city = re.findall('<span class="name">([\u4e00-\u9fa5]*)</span>', resp.text)
weather = re.findall('<span class="weather">([\u4e00-\u9fa5]*)</span>', resp.text)
wd = re.findall('<span class="wd">(.*)</span>', resp.text) # 因为气温这一栏有中文也有数字和其他字符,因此用 '.' 表示匹配任意字符
zs = re.findall('<span class="zs">([\u4e00-\u9fa5]*)</span>', resp.text)
print(city)
print(weather)
print(wd)
print(zs)
print('-' * 60)
# 对数据进行打包-->zip()
lst = []
for a, b, c, d in zip(city, weather, wd, zs):
lst.append([a, b, c, d])
print(lst)
for item in lst:
print(item)
简单的爬虫程序(爬取二进制数据),爬取百度LOGO图片。百度网址:https://www.baidu.com/,从该网址中找到百度LOGO图片网址:https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png。
import requests
# 爬取百度LOGO图片。百度LOGO图片网址如下:
url = 'https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png'
resp = requests.get(url)
# 将爬取到的二进制文件保存到本地
# logo.png是保持的文件名称,wb中的w--->write,b--->byte意思是以二进制方式写入
with open('logo.png', 'wb') as file:
file.write(resp.content)

需要说明的一点是这里仅仅是最简单的爬虫程序,如若要系统的学习爬虫还要专门进行细致的学习。
openpyxl模块的使用
使用pip命令安装openpyxl模块:
openpyxl模块:
- openpyxl模块是用于处理Microsoft Excel文件的第三方库
- 可以对Excel文件中的数据进行写入和读取
| 函数/属性名称 | 功能描述 |
|---|---|
| load_workbook(filename) | 打开已存在的表格,结果为工作簿对象 |
| workbook.sheetnames | 工作簿对象的sheetnames属性,用于获取所有工作表的名称,结果为列表类型 |
| sheet.append(lst) | 向工作表中添加一行数据,新数据接在工作表已有数据的后面 |
| workbook.save(excelname) | 保存工作簿 |
| Workbook() | 创建新的工作簿对象 |
下面做这样一件事:将在上面学习requests模块时爬取到的景区天气数据存储到Excel文件中。
思路:将爬取景区天气预报的代码封装到函数中,再将爬取的数据存储到Excel文件中。
新建文件(模块) weather.py,该模块会将爬取景区天气预报的代码封装到函数中,内容如下:
import requests # 爬虫模块
import re # 正则表达式
# 定义函数
def get_html(): # 爬取html页面(字符串数据)。【发送请求获取响应结果】
url = 'http://www.weather.com.cn/weather1d/101010100.shtml' # 爬虫打开的浏览器上的网页
resp = requests.get(url) # 打开浏览器并打开网址(返回Response响应对象)
# 设置编码格式(目的是查看中文)
resp.encoding = 'utf-8'
return resp.text
def parse_html(html_str): # 对html页面字符串数据进行解析。【对响应结果进行数据解析】
city = re.findall('<span class="name">([\u4e00-\u9fa5]*)</span>', html_str)
weather = re.findall('<span class="weather">([\u4e00-\u9fa5]*)</span>', html_str)
wd = re.findall('<span class="wd">(.*)</span>', html_str) # 因为气温这一栏有中文也有数字和其他字符,因此用 '.' 表示匹配任意字符
zs = re.findall('<span class="zs">([\u4e00-\u9fa5]*)</span>', html_str)
# 对数据进行打包-->zip()
lst = []
for a, b, c, d in zip(city, weather, wd, zs):
lst.append([a, b, c, d])
return lst
然后调用 weather.py 模块:
import weather
import openpyxl
html = weather.get_html() # 发请求,得响应结果
lst = weather.parse_html(html) # 解析数据
# 创建一个新的Excel工作簿
workbook = openpyxl.Workbook() # 创建对象
# 在Excel文件中创建工作表
sheet = workbook.create_sheet('景区天气') # 参数是工作表的名称
# 向工作表中添加数据
for item in lst: # lst是二维列表,item是列表
# sheet.append(lst) 向工作表中添加一行数据(列表),新数据接在工作表已有数据的后面
sheet.append(item) # 一次添加一行
# 保存工作簿。参数是工作簿名
workbook.save('景区天气.xlsx')
可以打开查看Excel文件:
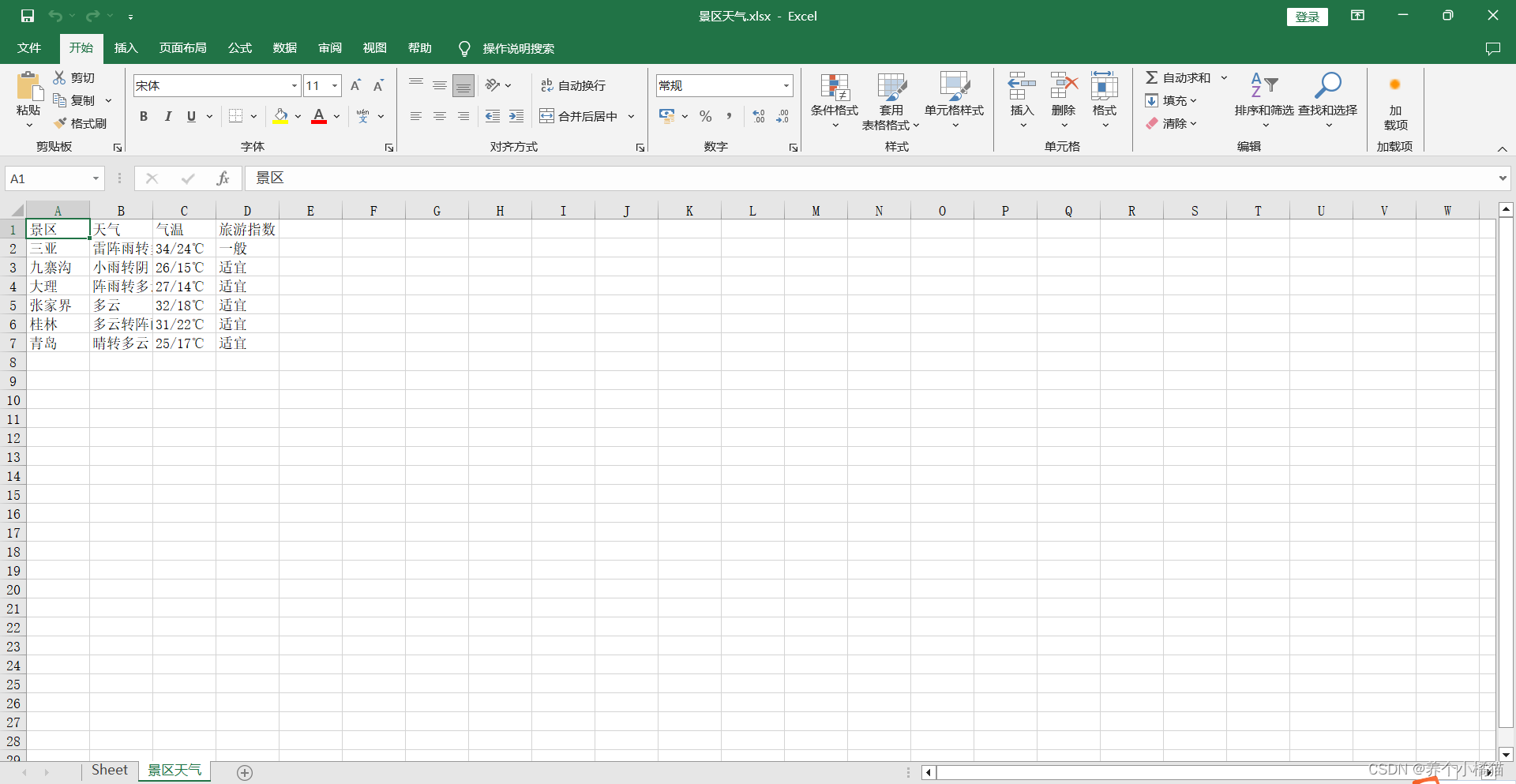
读取Excel文件:
import openpyxl
# 打开工作簿
workbook = openpyxl.load_workbook('景区天气.xlsx')
# 选择要操作的工作表
sheet = workbook['景区天气']
# 表格实际上就是二维列表。先遍历的是行,后遍历的是列
lst = [] # 存储的是行数据
for row in sheet.rows: # sheet.rows--->该工作表的所有行。一行一行遍历
sublst = [] # 存储单元格数据
for cell in row: # cell单元格
sublst.append(cell.value)
lst.append(sublst)
for item in lst:
print(item)

openpyxl模块在自动化办公中使用的比较多,同样的如若要系统的学习还要专门进行细致的学习。
pdfplumber模块的使用
pdfplumber模块可以用于从PDF文件中读取内容。
使用pip命令安装pdfplumber模块:
先在同目录下创建一个pdf文件:
import pdfplumber
# 打开PDF文件
with pdfplumber.open('古诗.pdf') as pdf:
# i是每页的对象
for i in pdf.pages: # pdf.pages--->该pdf的所有页。一页一页遍历
print(i.extract_text()) # extract_text()方法提取内容
print(f'----------第{i.page_number}页结束') # i.page_number获取页码

可以将Excel文件通过Python程序存储为PDF文件,可以从PDF文件中提取指定的数据,比如将PDF文件中的奇数页提取出来,将PDF倒序等都是可以通过pdfplumber模块来实现。如若想更深入的了解pdfplumber模块则可以学习自动化办公内容。
Numpy模块的使用
Numpy模块是Python数据分析方向和其他库的依赖库,用于处理数组、矩阵等数据。
使用pip命令安装numpy模块:
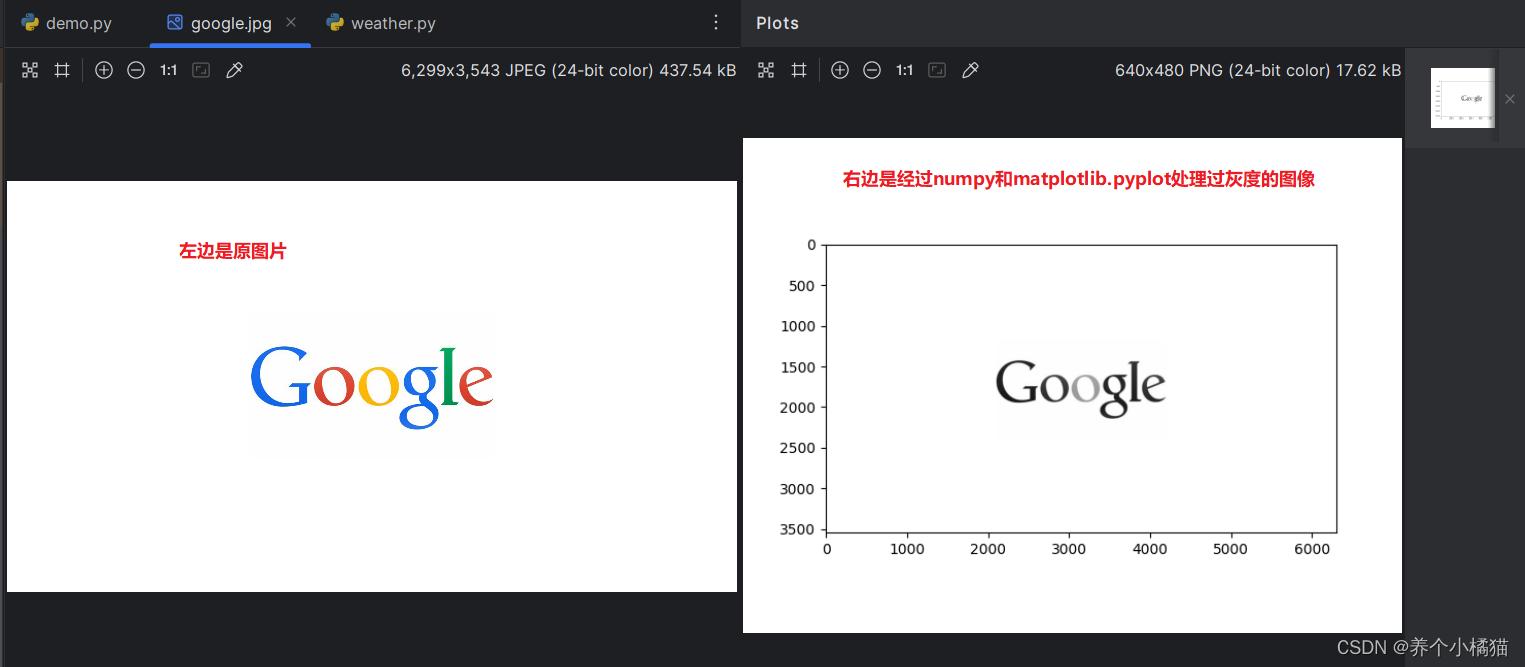
numpy模块可以用来处理图片,这类使用numpy模块对图像进行灰度处理:
首先在Python程序的同目录下放置一张彩色的图片,文件名为google.jpg。
import numpy as np # 起别名
import matplotlib.pyplot as plt # 起别名
'''
参考matplotlib官方文档:
matplotlib.pyplot.imread()将图像从文件读取到数组中。
返回:numpy.array 图像数据。返回的数组具有形状.
PNG 图像以浮点数组 (0-1) 的形式返回。所有其他格式都是 返回为 int 数组
'''
# 读取图片
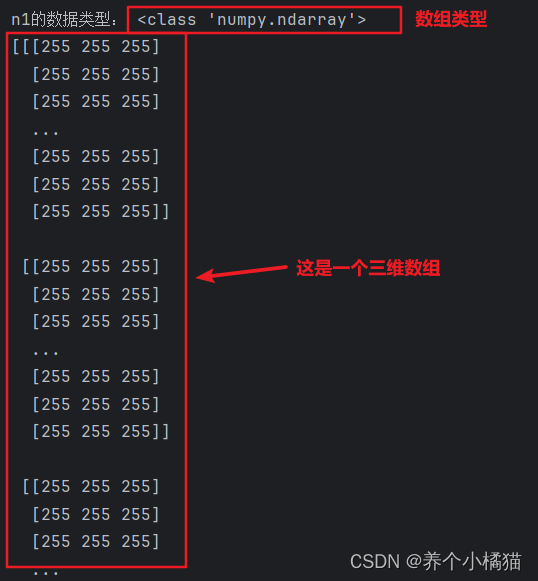
n1 = plt.imread('google.jpg')
print('n1的数据类型:', type(n1))
print(n1) # 数组,三维数组。最高维度表示的是图像的高,次高维度表示的是图像的宽,最低维表示[R,G,B]颜色
plt.imshow(n1)
# 编写一个灰度的公式--->这是一个固定值,照着写就行
n2 = np.array([0.299, 0.587, 0.114]) # 创建数组
# 将数组n1(RGB)颜色值与数组n2(灰度公式[固定值]),进行点乘运算
x = np.dot(n1, n2) # 点乘
# 传入数组,显示灰度
plt.imshow(x, cmap='gray')
# 显示图像
plt.show()
更详细的关于numpy模块的使用需要学习数据分析的内容,numpy模块是数据分析中必须学习的,用于处理数组、矩阵等数据,并且在学人工智能时也离不开。
Pandas模块与Matplotlib模块的使用
Pandas是基于Numpy模块扩展的一个非常重要的数据分析模块,使用Pandas读取Excel数据更加的方便。
Matplotlib是用于数据可视化的模块,使用Matplotlib.pyplot可以非常方便的绘制饼图、柱形图、折线图等。
使用pip命令安装pandas模块:
使用pip命令安装matplotlib模块:
下面使用pandas模块和matplotlib模块读取Excel文件并绘制饼图:
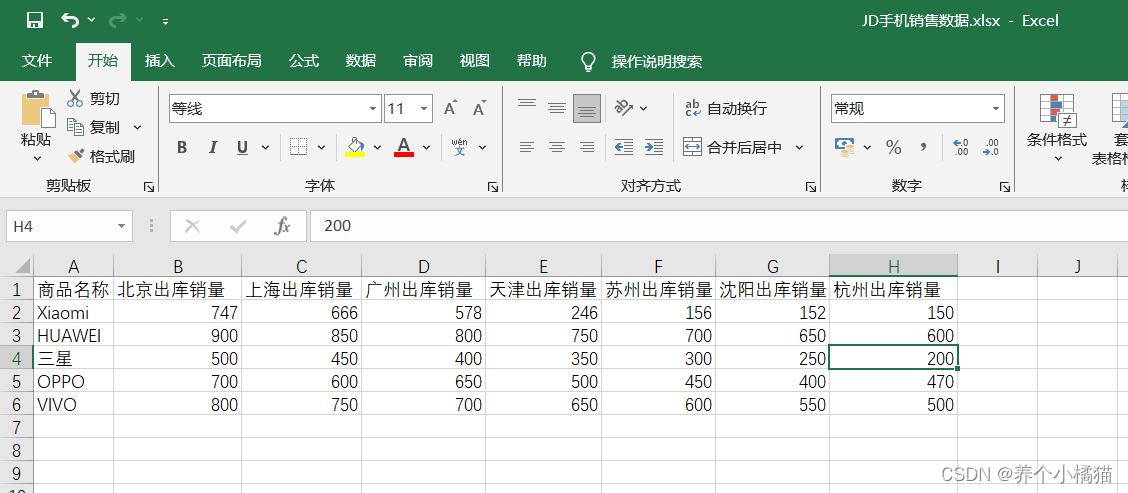
在Python程序的同目录下放置要读取的Excel文件,文件名为 JD手机销售数据.xlsx,内容如下:
编写代码:
import pandas as pd # 起别名
import matplotlib.pyplot as plt # 起别名
# 读取Excel文件
df = pd.read_excel('JD手机销售数据.xlsx')
# print(df)
# 解决绘图时产生的中文乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 右边是字体,计算机中需要有该字体
# 绘图需要设置画布的大小
plt.figure(figsize=(10, 6))
labels = df['商品名称'] # 饼图扇形中的标签
y = df['北京出库销量'] # y轴
# print(labels)
# print(y)
# 绘制饼图-->查看北京出库销量不同商品所占的份额。
# pie英文意思是“饼”。可以查看matplotlib官方文档
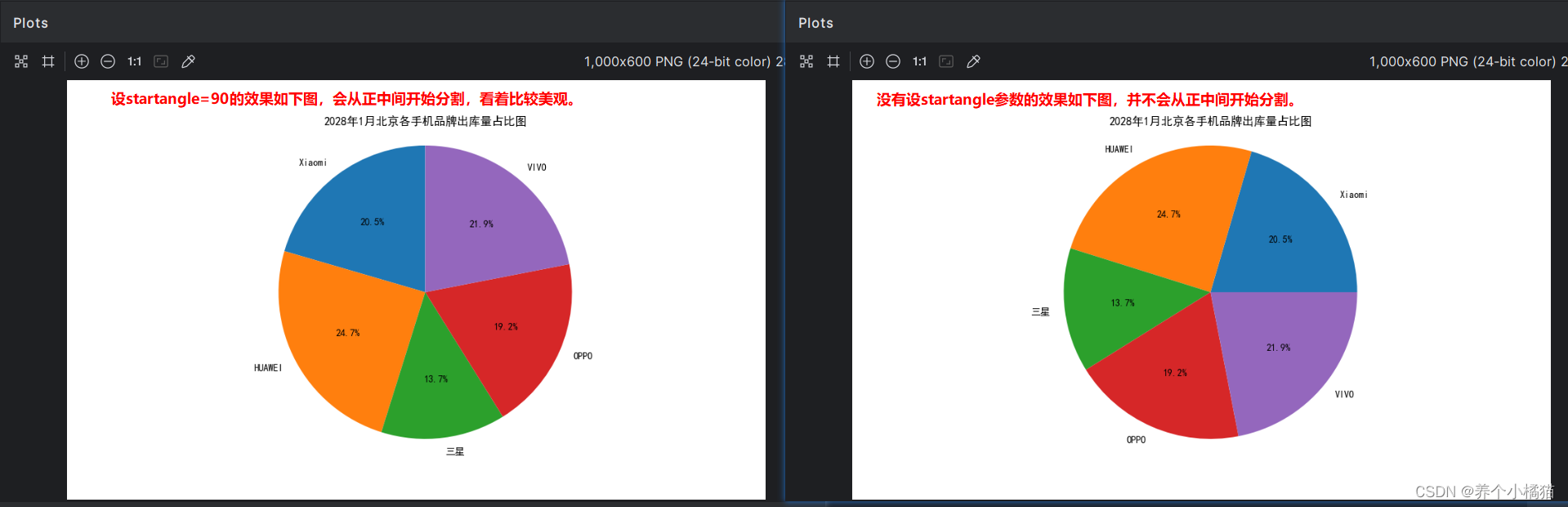
# pie()第二个参数是饼图的标签,第三个参数意思是保留一位小数(百分比),为了美观可以将第四个参数设为startangle=90
plt.pie(y, labels=labels, autopct='%1.1f%%', startangle=90)
# 设置x,y轴刻度,保证饼图是一个正圆
plt.axis('equal')
# 饼图的标题
plt.title('2028年1月北京各手机品牌出库量占比图')
# 显示出来
plt.show()
pandas模块和matplotlib模块同numpy模块一样都属于数据分析的内容,如要更深入的学习这些模块,则需要细致的学习数据分析。
PyEcharts模块的使用
PyEcharts是由百度开源的数据可视化库,它对流行图的支持度比较高,它给用户提供了30多种图形,如柱形渐变图、K线周期图。
中文帮助文档:https://pyecharts.org/#/zh-cn/
PyEcharts的使用可以分四个步骤实现:
1、导入pyecharts包
2、找到相应图形模版
3、准备相应数据
4、对图表进行个性化修饰
使用pip命令安装pyecharts模块:
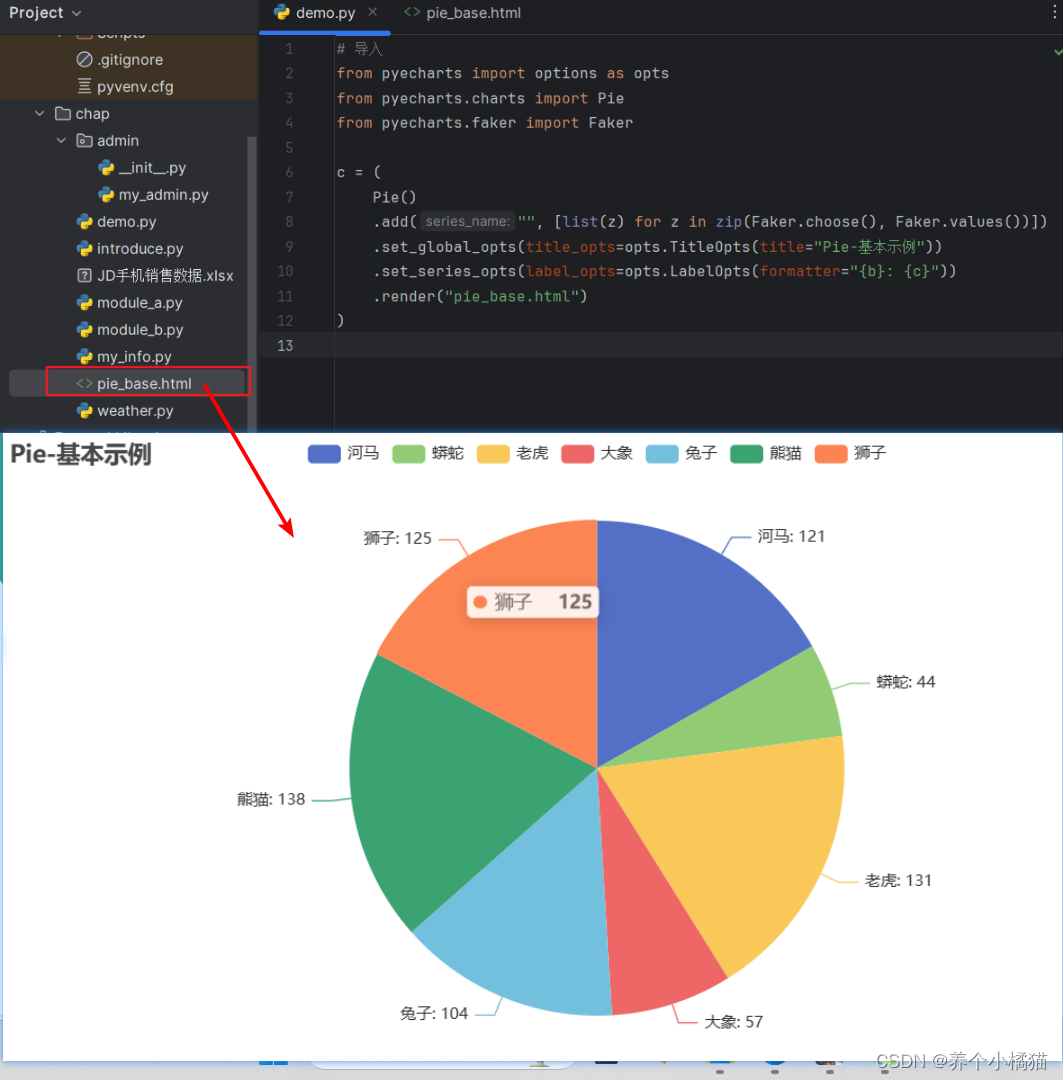
安装上述四个步骤使用PyEcharts模块提供的基本饼图:

将图形模版复制到PyCharm中运行会生成一个html文件,打开后会展示出饼图:
下面分析图形模版,替换成自己的数据:
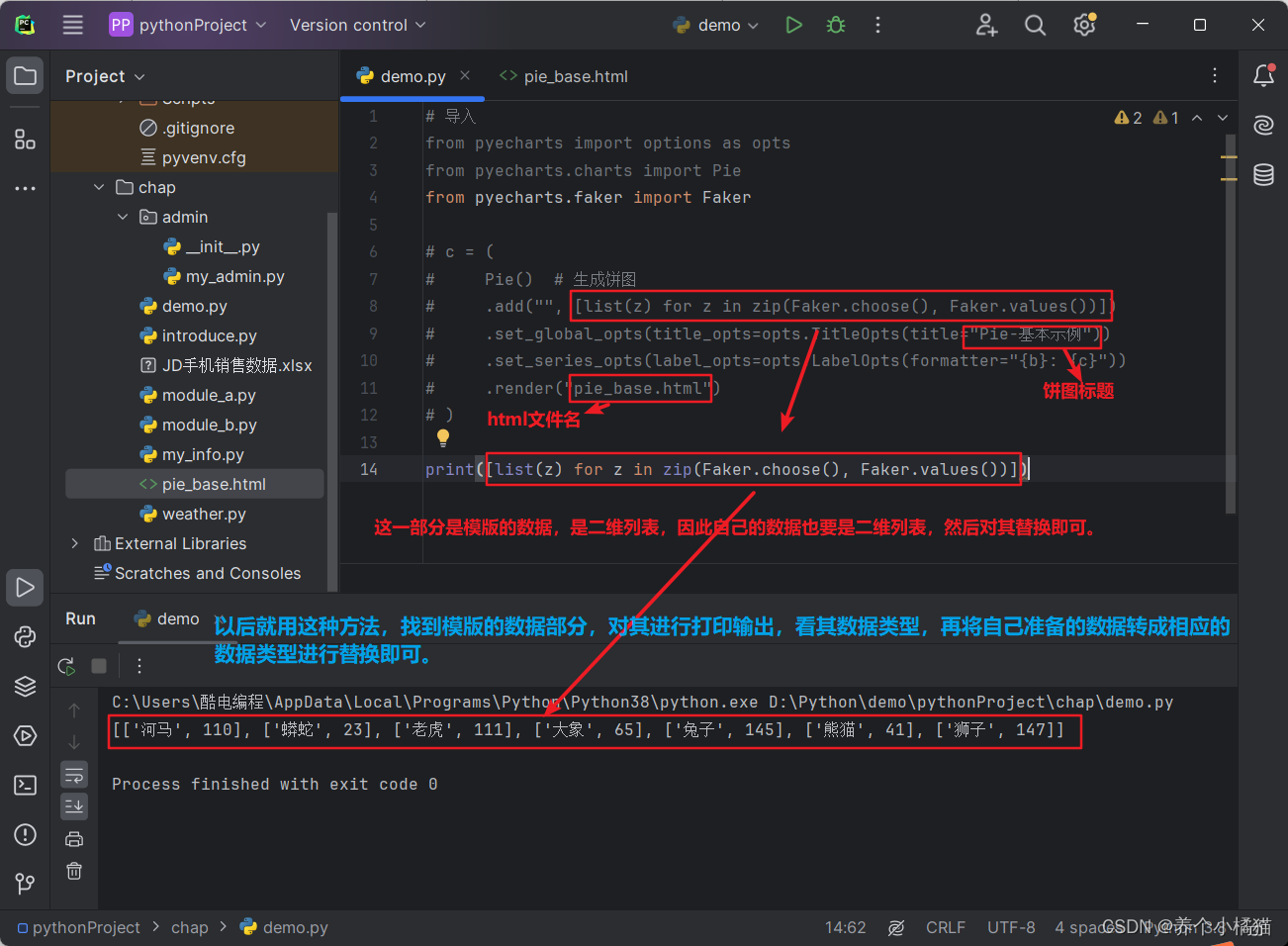
# 导入
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
# 准备数据
lst = [['HUAWEI', 1000], ['OPPO', 800], ['Apple', 900], ['Xiaomi', 950]]
c = (
Pie() # 生成饼图
# .add("", [list(z) for z in zip(Faker.choose(), Faker.values())])
.add('', lst) # 替换数据
.set_global_opts(title_opts=opts.TitleOpts(title="2028年手机出库占比情况"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render("phone.html")
)
# print([list(z) for z in zip(Faker.choose(), Faker.values())])
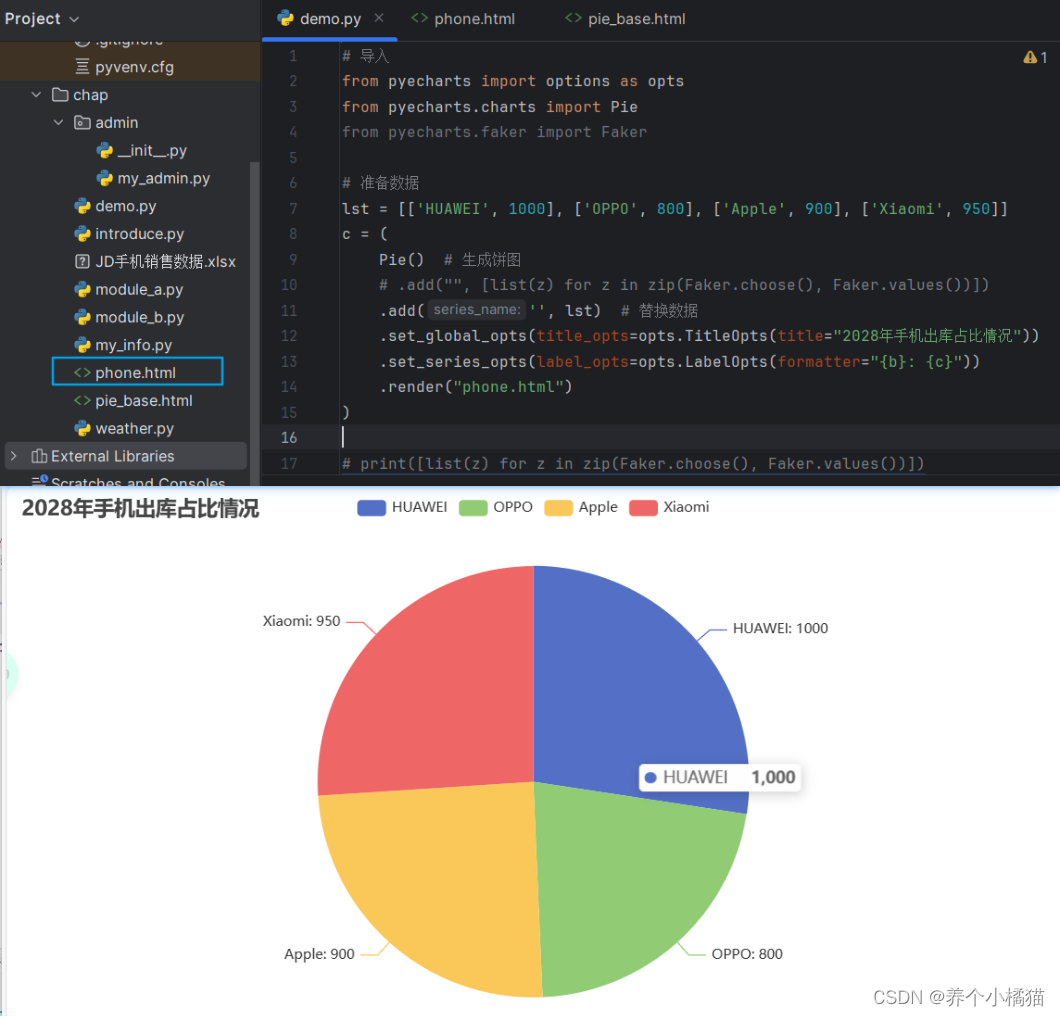
类似的,使用其他图形模版时也按照这个方法即可。同上面的模块一样,PyEcharts模块也属于数据分析的内容,如要更深入的学习这些模块,则需要细致的学习数据分析。
PIL模块图像的处理
PIL是用于图像处理的第三方库,它支持图像存储、处理和显示等操作。
安装:
pip install pillow
PyEcharts模块和Matplotlib模块是绘图、数据可视化的;而PIL是图像处理的。
使用pip命令安装PIL模块(注意语法):
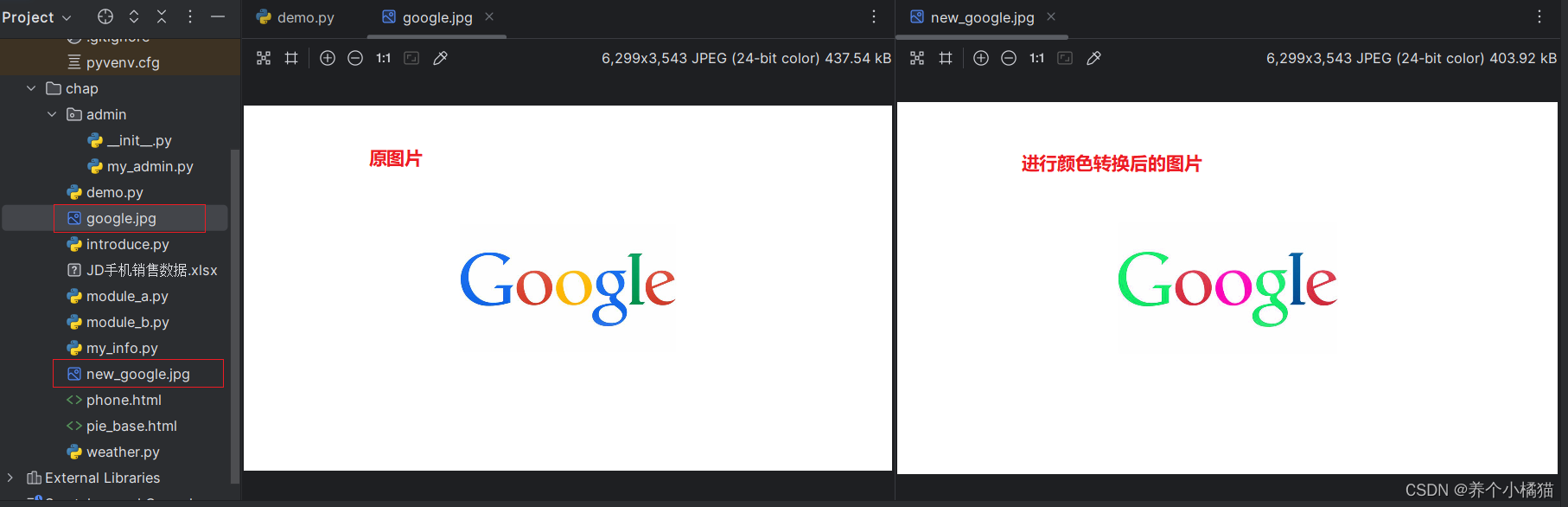
下面使用PIL模块实现图像的颜色交换(同样使用google.jpg这张图片):
from PIL import Image
# 加载图片
im = Image.open('google.jpg')
print(type(im)) # <class 'PIL.JpegImagePlugin.JpegImageFile'>
# im的模式是RGB的,因此就要用RGB的方式去处理
print(im) # <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=6299x3543 at 0x201EDAA7880>
# 提取RGB图像的颜色通道,返回结果是图像的副本
r, g, b = im.split() # 系列解包赋值
print(r) # <PIL.Image.Image image mode=L size=6299x3543 at 0x2AA3CC47160>
print(g) # <PIL.Image.Image image mode=L size=6299x3543 at 0x2AA3CC47280>
print(b) # <PIL.Image.Image image mode=L size=6299x3543 at 0x2AA4E1654F0>
# 合并通道。从(R,G,B)--->(R,B,G),从而实现颜色转换
om = Image.merge(mode='RGB', bands=(r, b, g)) # 关键字赋值
om.save('new_google.jpg') # 保存

jieba模块实现中文分词
jieba是Python中用于对中文进行分词的模块,它可以将一段中文文本分隔成中文词组的序列。
在人工智能中的自然语言处理的时候会用到这个模块。
使用pip命令安装jieba模块:
在Python程序的同目录下放一个名为 手机评价.txt 的文件:
import jieba
# 把文件读进来
with open('手机评价.txt', 'r', encoding='utf-8') as file:
s = file.read()
# print(s)
# 分词
lst = jieba.lcut(s)
# print(lst)
# 去重操作
set1 = set(lst) # 使用集合实现去重
d = {} # key:词,value:出现的次数
for item in set1:
# 词--->字符数>=2
if len(item) >= 2:
d[item] = 0
# print(d)
# 统计词频
for item in lst:
if item in d:
d[item] = d.get(item) + 1
new_lst = []
for item in d:
new_lst.append([item, d[item]])
# print(new_lst)
# 列表排序
new_lst.sort(key=lambda x: x[1], reverse=True) # 匿名函数在列表排序中的使用
print(new_lst[0:3]) # 切片。显示前3项

PyInstaller模块打包源文件
第三方库Pyinstaller可以在Windows操作系统中将Python源文件打包成 .exe 的可执行文件。还可以在Linux和MacOS操作系统中对源文件进行打包操作。
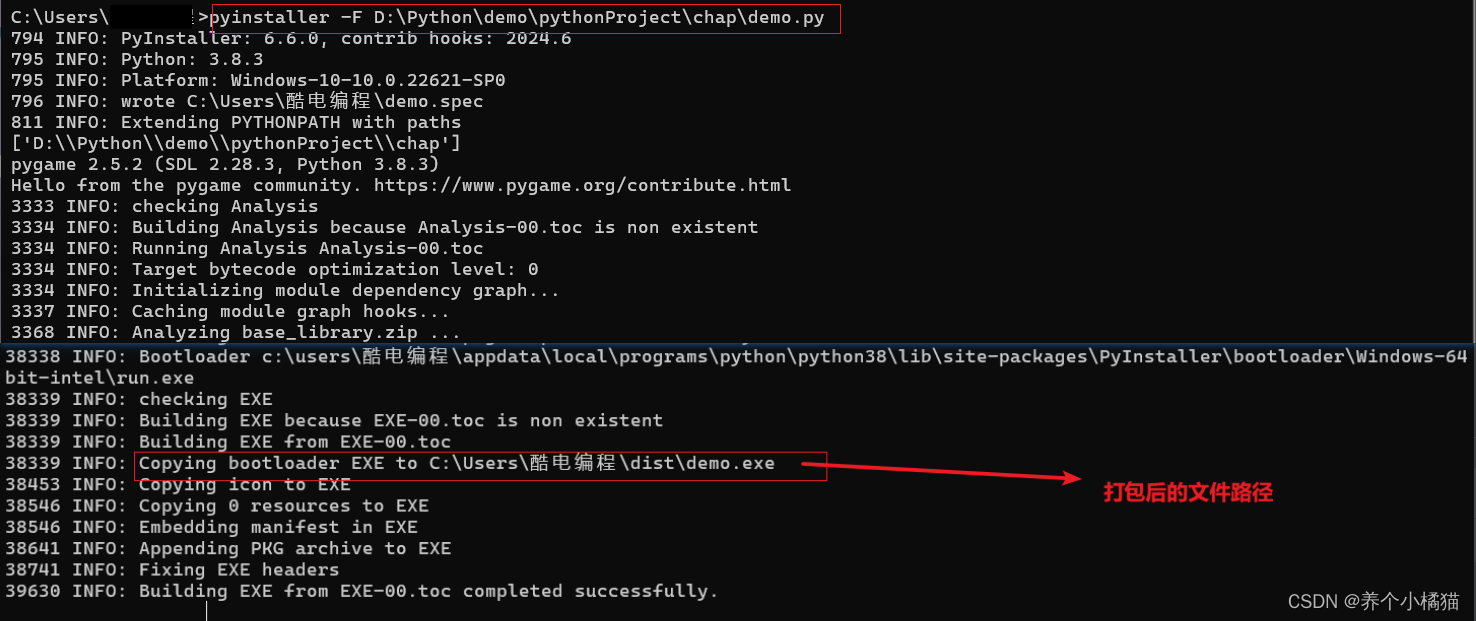
打包的语法结构(在命令行中):
pyinstaller -F 源文件文件名
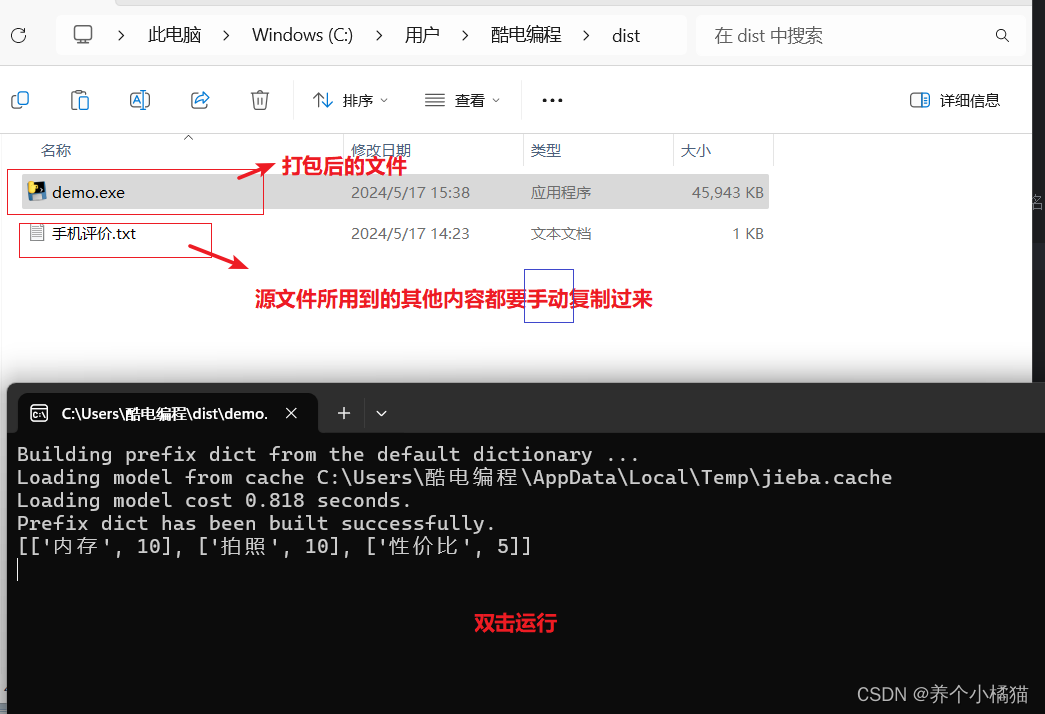
其中 -F 表示会在 dist 文件夹中会生成独立的打包文件。
注意事项:
在进行文件打包时,需要打包的文件尽量不要有中文,而且需要打包的文件路径也尽量不要有中文,路径中包含中文有可能会导致打包失败。
使用pip命令安装pyinstaller模块:
pyinstaller模块就是在命令行中使用的:
小结
本章中间部分了解了十几个常用的第三方模块,但是Python中的第三方模块有成千上万个,涉及到的领域也非常多,需要根据自己研究的方向去更深入的学习。比如数据分析、人工智能、Python全栈。
练习题
练习一
模拟高铁售票系统。
需求:
假设高铁一节车厢的座位数有6行,每行5列,每个座位初始显示“有票”,用户输入座位位置(如4,3)后,按回车,则该座位显示为“已售”,使用到第三方模块prettytable。
使用pip命令导入prettytable模块:

import prettytable as pt # 起别名
# 显示坐席
def show_ticket(row_num):
tb = pt.PrettyTable() # 创建一张表格
# 设置标题(表格的排头部分)
tb.field_names = ['行号', '座位1', '座位2', '座位3', '座位4', '座位5']
# 遍历有票
for i in range(1, row_num + 1):
lst = [f'第{i}行', '有票', '有票', '有票', '有票', '有票']
tb.add_row(lst)
print(tb)
# 订票
def order_ticket(row_num, row, column):
tb = pt.PrettyTable() # 重新绘制一张表格
# 设置标题(表格的排头部分)
tb.field_names = ['行号', '座位1', '座位2', '座位3', '座位4', '座位5']
for i in range(1, row_num + 1):
if int(row) == i:
lst = [f'第{i}行', '有票', '有票', '有票', '有票', '有票']
lst[int(column)] = '已售'
tb.add_row(lst)
else:
lst = [f'第{i}行', '有票', '有票', '有票', '有票', '有票']
tb.add_row(lst)
print(tb)
if __name__ == '__main__':
row_num = 6
show_ticket(row_num)
# 开始售票
choose_num = input('请输入您选择的坐席:如4,3表示第4排第3列:')
row, column = choose_num.split(',') # 字符串分割,返回列表。进行系列解包赋值
order_ticket(row_num, row, column)

练习二
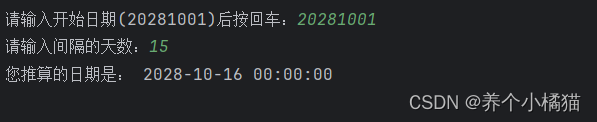
推算几天后的日期。
需求:
编写一个程序,输入开始日期和间隔天数,可以推算出结束日期,使用内置的datetime模块。
import datetime
# 输入日期的函数
def input_date():
inputdate = input('请输入开始日期(20281001)后按回车:')
datestr = inputdate[0:4] + '-' + inputdate[4:6] + '-' + inputdate[6:] # 字符串切片操作。切出年、月、日
# 类型转换。字符串--->datetime类型
dt = datetime.datetime.strptime(datestr, '%Y-%m-%d')
return dt
# 主程序运行
if __name__ == '__main__':
# print(input_date())
date = input_date()
# 输入间隔的天数
in_num = eval(input('请输入间隔的天数:'))
date = date + datetime.timedelta(days=in_num)
print('您推算的日期是:', date)
练习三
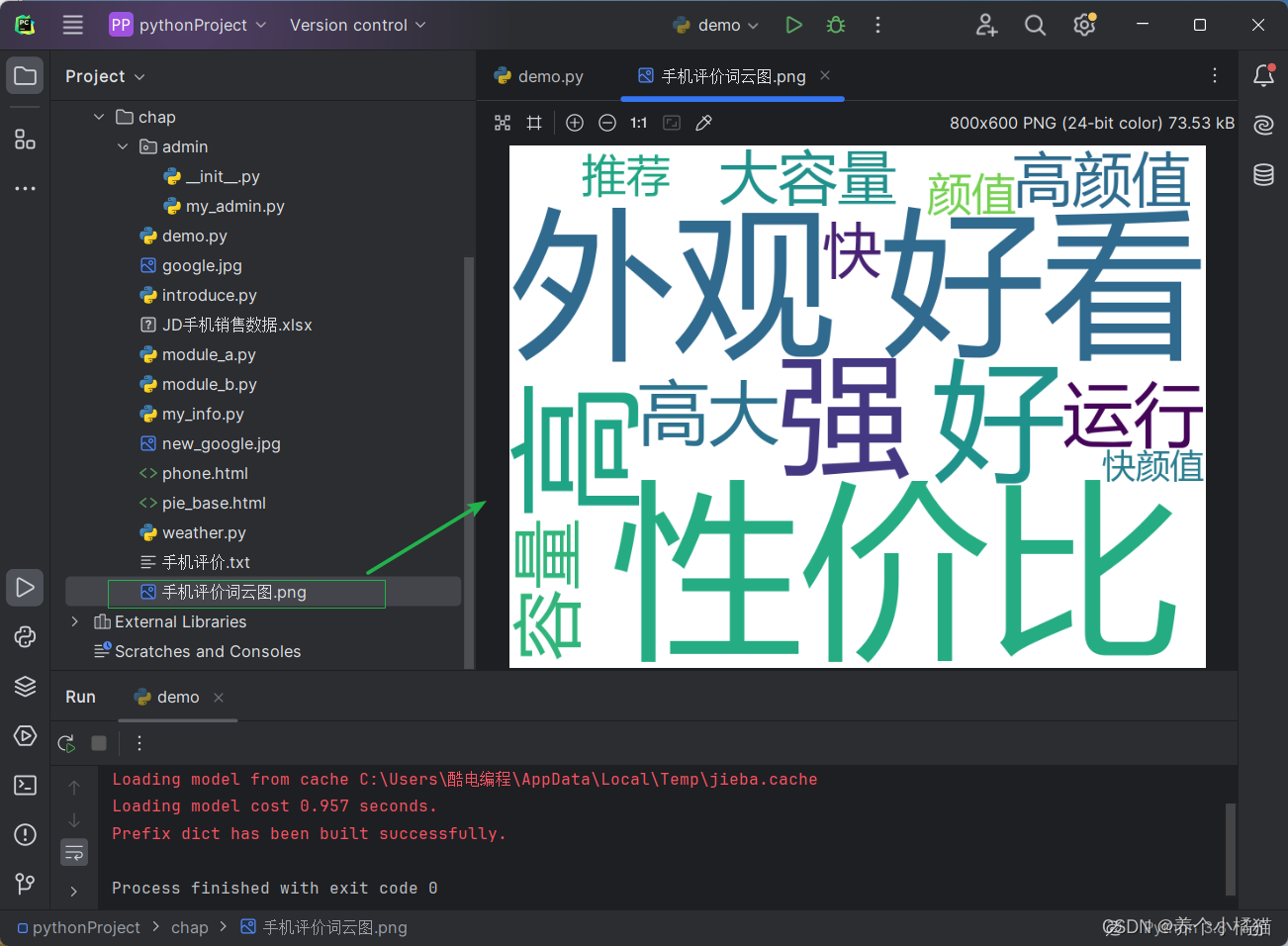
词云图。
需求:
使用Python第三方库jieba与wordcloud实现对 “手机评价” 的词云图。
使用pip命令安装wordcloud模块:
import jieba
from wordcloud import WordCloud
# 读取数据
with open('手机评价.txt', 'r', encoding='utf-8') as file:
s = file.read()
# 中文分词
lst = jieba.lcut(s)
# 排除词-->不能显示在词云图上的词
stopword = ['内存', '拍照']
txt = ' '.join(lst)
# 绘制词云图
wordcloud = WordCloud(background_color='white', font_path='msyh.ttc', stopwords=stopword,
width=800, height=600)
# 由txt生成词云图
wordcloud.generate(txt)
# 保存图片
wordcloud.to_file('手机评价词云图.png')

















 1996
1996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









