







Description
小 W 很喜欢序列,尤其喜欢“W”形的和“M”形的序列。定义“M”形
的序列为一个长度为 T 的序列{Si},满足:存在 1 < x < y < z < N,使得S1 < ... <
Sx > ... > Sy < ... < Sz > ... > ST。
一天他看到了一个长度为N 的整数序列{Ai},他想通过一些修改把序列变成
“M”形的。但这时小 X 过来了,说这个序列是他的,小 W 如果想要修改就要
支付一定的费用。每支付一单位的费用,小 W 都可以进行这样的操作:将一段
连续的数同时加上 1,即选定i, j 满足1 ≤ i ≤ j ≤ N 并令Ai, Ai+1, ..., Aj均加上1。
小 W 想用最小的费用将序列变成“M”形的。但是有个条件:如果他修改
成的目标是序列{Bi}满足B1 < ... < Bx > ... > By < ... < Bz > ... > BN, 那么必须有Ay=
By。
现在,他希望你来帮他计算最小费用。
Input
第一行包含一个整数 N,表示序列A的长度。
第二行有 N 个整数给出初始的序列{Ai}。
Output
仅包含一行,为最小的花费。
Sample Input
5
2 1 2 2 3
2 1 2 2 3
Sample Output
4
HINT
对于100%的数据满足 5 ≤ N ≤ 100 000,0 ≤ Ai ≤ 10 ^9。
f[i]表示把1~i改为递增的最小代价,g[i]表示把i~n改为递减的最小代价。
不难求出f和g数组(而且他们是满足可减性的)。
然后考虑固定一个中点,左边和右边答案分别是什么
比如说把1~i改成一个倒V的最小代价是 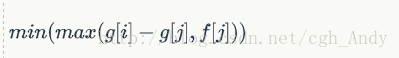
i~n的也同理啊。
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
typedef long long LL;
int a[110000];
LL f[110000],g[110000];
//f[i]把1~i改为递增的最小代价,g[i]把i~n改为递减的最小代价
LL l[110000],r[110000];
int main()
{
int n;
scanf("%d",&n);
for(int i=1;i<=n;i++) scanf("%d",&a[i]);
a[0]=-1;
for(int i=1;i<=n;i++) f[i]=f[i-1]+max(a[i-1]-a[i]+1,0);
for(int i=n;i>=1;i--) g[i]=g[i+1]+max(a[i+1]-a[i]+1,0);
int k=2;
for(int i=3;i<=n-2;i++)//i为中点
{
while(k<i-1 && max(f[k+1],g[k+1]-g[i])<=max(f[k],g[k]-g[i])) k++;
l[i]=max(f[k],g[k]-g[i]);
}
k=n-1;
for(int i=n-2;i>=3;i--)
{
while(k>i+1 && max(g[k-1],f[k-1]-f[i])<=max(g[k],f[k]-f[i])) k--;
r[i]=max(g[k],f[k]-f[i]);
}
LL ans=999999999999999;//记得开大点,小宝贝~~~
for(int i=3;i<=n-2;i++) ans=min(ans,l[i]+r[i]);
printf("%lld\n",ans);
return 0;
}














 1282
1282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









