







 本文通过构建线性、多项式、岭回归和套索回归模型,分析丰田卡罗拉数据集,探讨了不同模型在预测售价方面的性能,并通过可视化展示模型的R²分数和RMSE,揭示各模型优劣。
本文通过构建线性、多项式、岭回归和套索回归模型,分析丰田卡罗拉数据集,探讨了不同模型在预测售价方面的性能,并通过可视化展示模型的R²分数和RMSE,揭示各模型优劣。
使用丰田卡罗拉数据集构建了4个回归模型。这些是线性回归、多项式回归、岭回归、套索回归,然后衡量并可视化模型的性能。借鉴黄海广老师的课件资料。
1. 概述
数据列:
Age: 车龄
KM: 累计里程
FuelType: 燃油类型 (Petrol, Diesel, CNG)
HP: 功率
MetColor: 是否金属漆 (Yes=1, No=0)
Automatic: 是否自动挡( (Yes=1, No=0)
CC: 排量
Doors: 车门数量
Weight: 整车重量
Price: 售价(欧元)
2、导入库并导入数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import cross_val_score
from collections import Counter
from IPython.core.display import display, HTML
sns.set_style('white')
import warnings
warnings.filterwarnings("ignore")#忽略警告
dataset = pd.read_csv('data/ToyotaCorolla.csv')
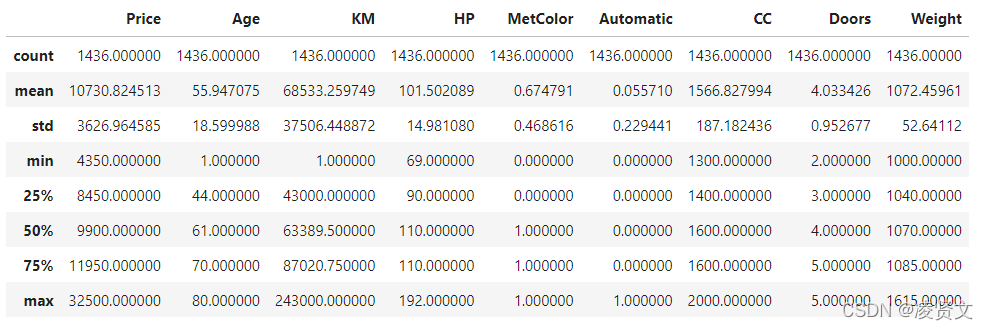
dataset.head()
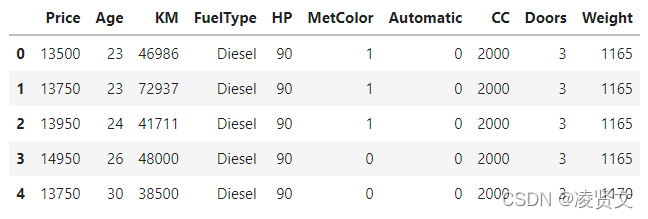
dataset.count()
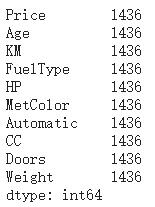
dataset.describe()
3、数据处理和可视化
dataset.isnull().sum()

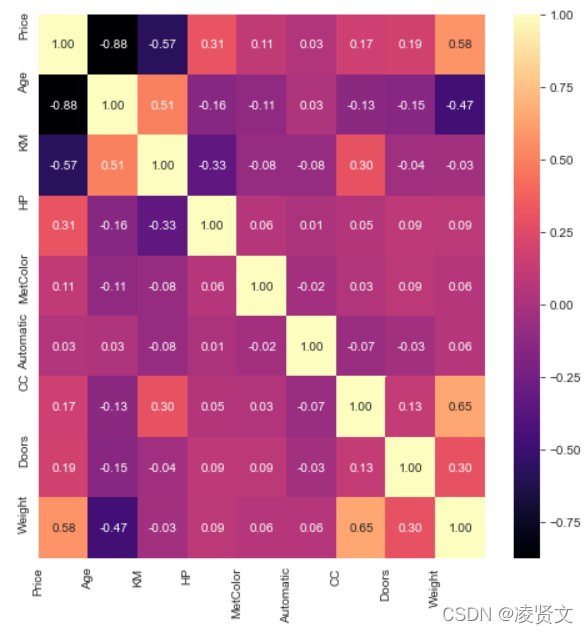
corr = dataset.corr()
#Plot figsize
fig, ax = plt.subplots(figsize=(8, 8))
#Generate Heat Map, allow annotations and place floats in map
sns.heatmap(corr, cmap='magma', annot=True, fmt=".2f")
#Apply xticks
plt.xticks(range(len(corr.columns)), corr.columns);
#Apply yticks
plt.yticks(range(len(corr.columns)), corr.columns)
#show plot
plt.show()
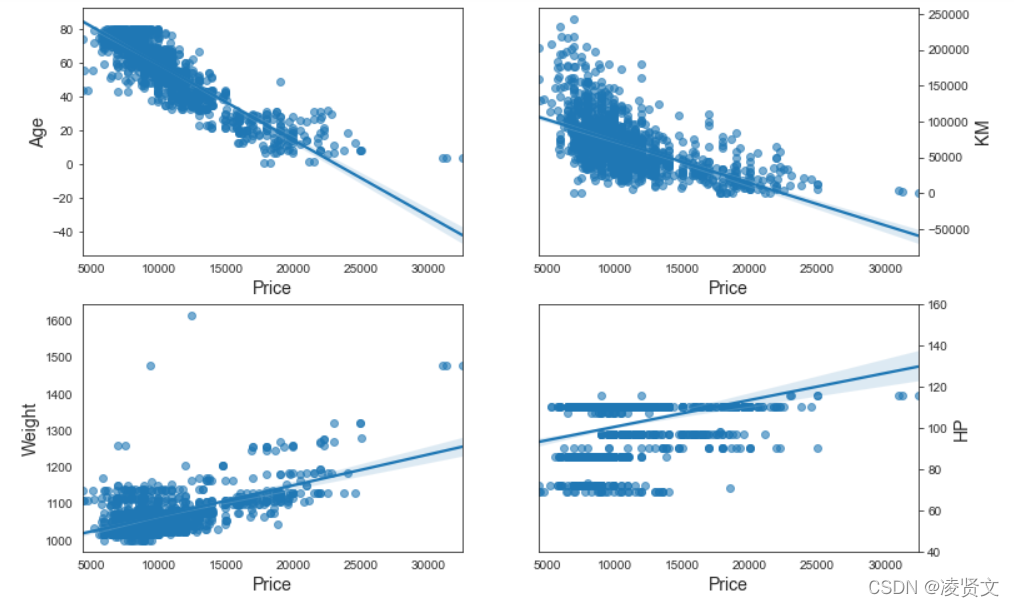
f, axes = plt.subplots(2, 2, figsize=(12, 8))
sns.regplot(x='Price',
y='Age',
data=dataset,
scatter_kws={'alpha': 0.6},
ax=axes[0, 0])
axes[0, 0].set_xlabel('Price', fontsize=14)
axes[0, 0].set_ylabel('Age', fontsize=14)
axes[0, 0].yaxis.tick_left()
sns.regplot(x='Price',
y='KM',
data=dataset,
scatter_kws={'alpha': 0.6},
ax=axes[0, 1])
axes[0, 1].set_xlabel('Price', fontsize=14)
axes[0, 1].set_ylabel('KM', fontsize=14)
axes[0, 1].yaxis.set_label_position("right")
axes[0, 1].yaxis.tick_right()
sns.regplot(x='Price',
y='Weight',
data=dataset,
scatter_kws={'alpha': 0.6},
ax=axes[1, 0])
axes[1, 0].set_xlabel('Price', fontsize=14)
axes[1, 0].set_ylabel('Weight', fontsize=14)
sns.regplot(x='Price',
y='HP',
data=dataset,
scatter_kws={'alpha': 0.6},
ax=axes[1, 1])
axes[1, 1].set_xlabel('Price', fontsize=14)
axes[1, 1].set_ylabel('HP', fontsize=14)
axes[1, 1].yaxis.set_label_position("right")
axes[1, 1].yaxis.tick_right()
axes[1, 1].set(ylim=(40, 160))
plt.show()
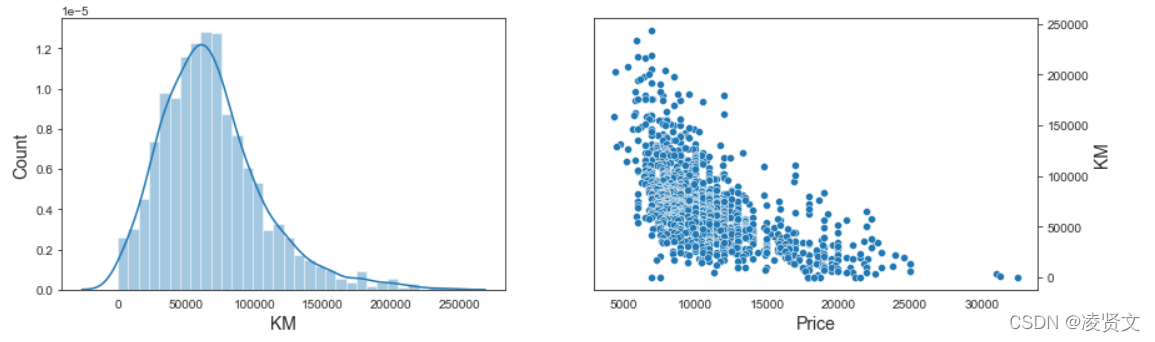
f, axes = plt.subplots(1,2,figsize=(14,4))
sns.distplot(dataset['KM'], ax = axes[0])
axes[0].set_xlabel('KM', fontsize=14)
axes[0].set_ylabel('Count', fontsize=14)
axes[0].yaxis.tick_left()
sns.scatterplot(x = 'Price', y = 'KM', data = dataset, ax = axes[1])
axes[1].set_xlabel('Price', fontsize=14)
axes[1].set_ylabel('KM', fontsize=14)
axes[1].yaxis.set_label_position("right")
axes[1].yaxis.tick_right()
plt.show()
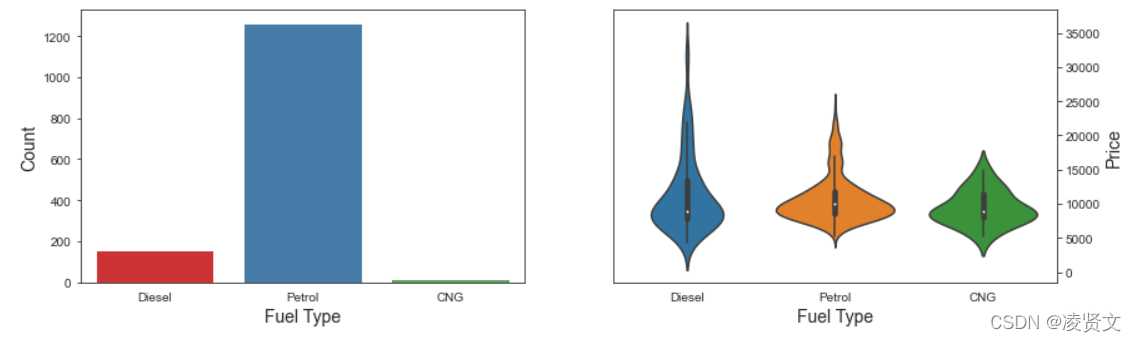
fuel_list= Counter(dataset['FuelType'])
labels = fuel_list.keys()
sizes = fuel_list.values()
f, axes = plt.subplots(1,2,figsize=(14,4))
sns.countplot(dataset['FuelType'], ax = axes[0], palette="Set1")
axes[0].set_xlabel('Fuel Type', fontsize=14)
axes[0].set_ylabel('Count', fontsize=14)
axes[0].yaxis.tick_left()
sns.violinplot(x = 'FuelType', y = 'Price', data = dataset, ax = axes[1])
axes[1].set_xlabel('Fuel Type', fontsize=14)
axes[1].set_ylabel('Price', fontsize=14)
axes[1].yaxis.set_label_position("right")
axes[1].yaxis.tick_right()
plt.show()
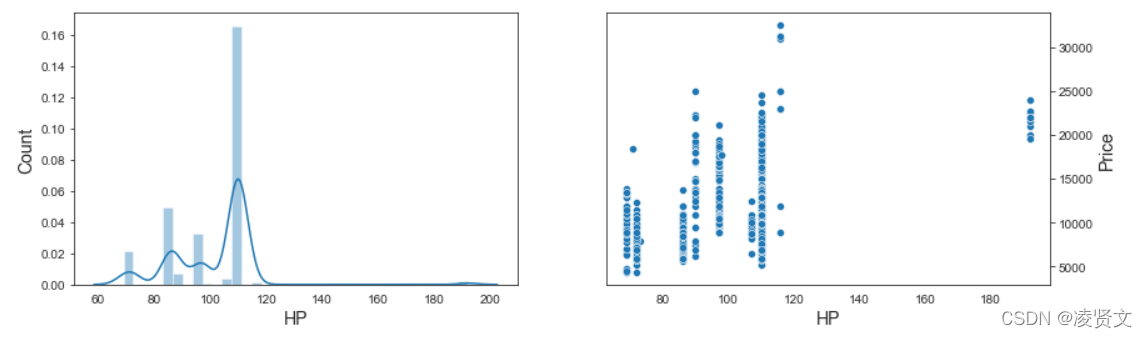
f, axes = plt.subplots(1,2,figsize=(14,4))
sns.distplot(dataset['HP'], ax = axes[0])
axes[0].set_xlabel('HP', fontsize=14)
axes[0].set_ylabel('Count', fontsize=14)
axes[0].yaxis.tick_left()
sns.scatterplot(x = 'HP', y = 'Price', data = dataset, ax = axes[1])
axes[1].set_xlabel('HP', fontsize=14)
axes[1].set_ylabel('Price', fontsize=14)
axes[1].yaxis.set_label_position("right")
axes[1].yaxis.tick_right()
plt.show()
f, axes = plt.subplots(1, 2, figsize=(14, 4))
sns.distplot(dataset['MetColor'], ax=axes[0])
axes[0].set_xlabel('MetColor', fontsize=14)
axes[0].set_ylabel('Count', fontsize=14)
axes[0].yaxis.tick_left()
sns.boxplot(x='MetColor', y='Price', data=dataset, ax=axes[1])
axes[1].set_xlabel('MetColor', fontsize=14)
axes[1].set_ylabel('Price', fontsize=14)
axes[1].yaxis.set_label_position("right")
axes[1].yaxis.tick_right()
plt.show()
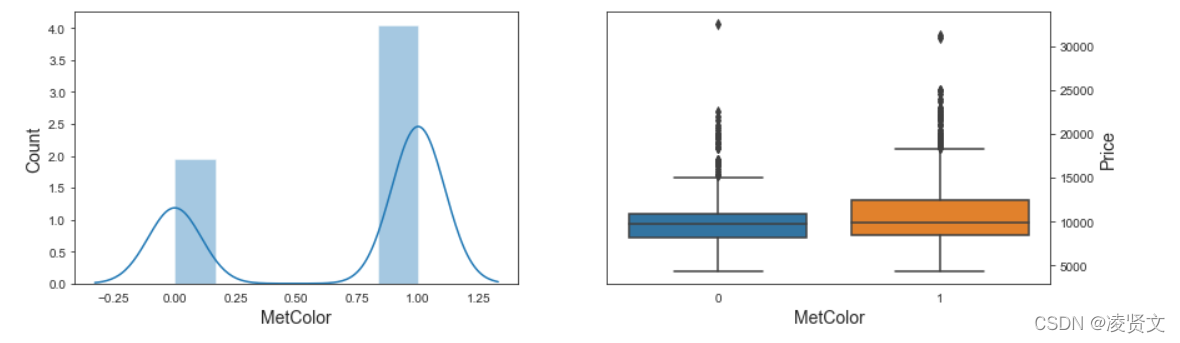
f, axes = plt.subplots(1, 2, figsize=(14, 4))
sns.distplot(dataset['Automatic'], ax=axes[0])
axes[0].set_xlabel('Automatic', fontsize=14)
axes[0].set_ylabel('Count', fontsize=14)
axes[0].yaxis.tick_left()
sns.boxenplot(x='Automatic', y='Price', data=dataset, ax=axes[1])
axes[1].set_xlabel('Automatic', fontsize=14)
axes[1].set_ylabel('Price', fontsize=14)
axes[1].yaxis.set_label_position("right")
axes[1].yaxis.tick_right()
plt.show()
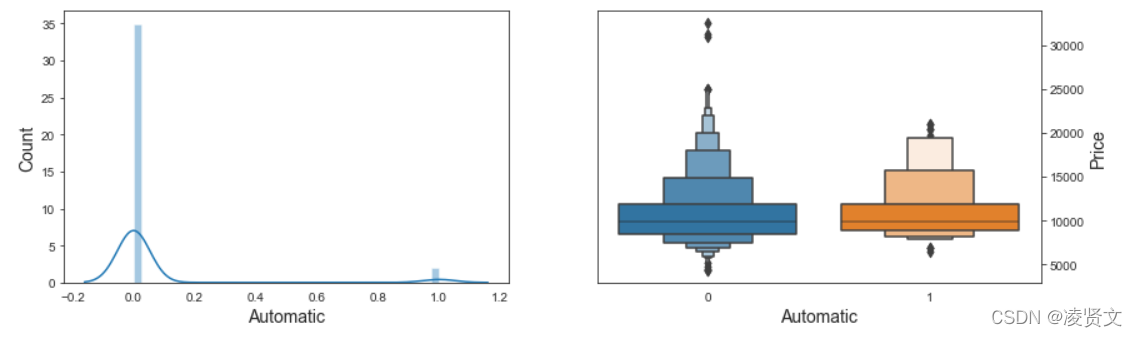
f, axes = plt.subplots(1, 2, figsize=(14, 4))
sns.distplot(dataset['CC'], ax=axes[0])
axes[0].set_xlabel('CC', fontsize=14)
axes[0].set_ylabel('Count', fontsize=14)
axes[0].yaxis.tick_left()
sns.boxplot(x='CC', y='Price', data=dataset, ax=axes[1])
axes[1].set_xlabel('CC', fontsize=14)
axes[1].set_ylabel('Price', fontsize=14)
axes[1].yaxis.set_label_position("right")
axes[1].yaxis.tick_right()
plt.show()
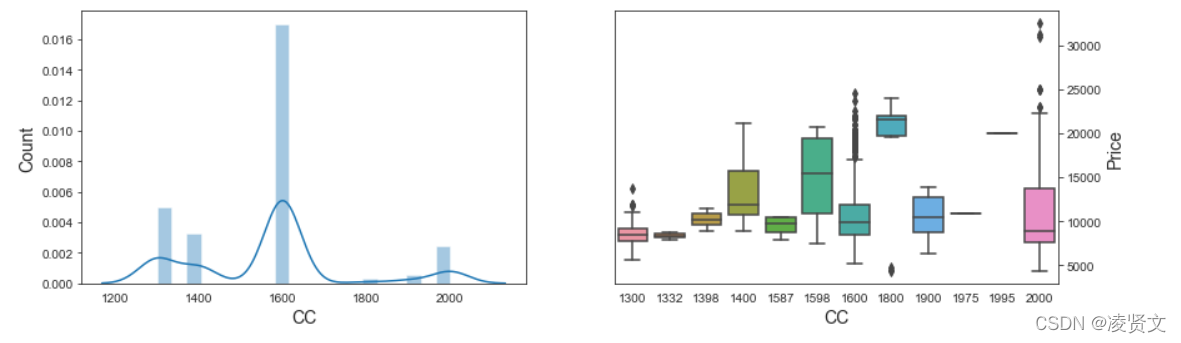
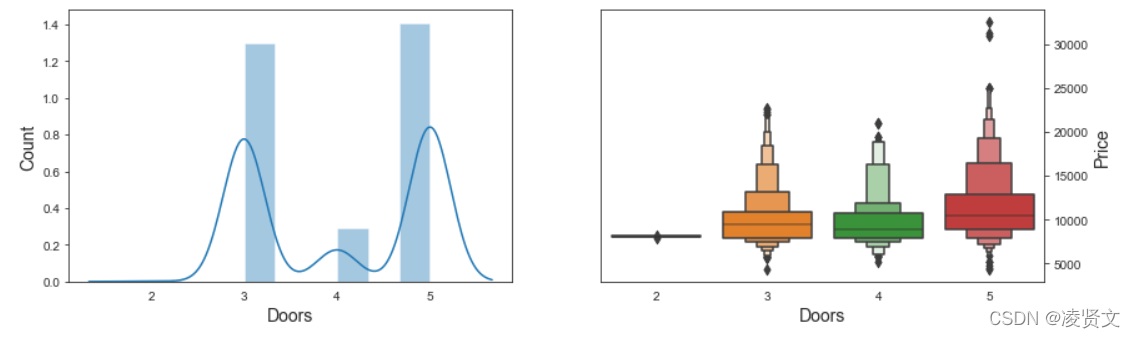
f, axes = plt.subplots(1, 2, figsize=(14, 4))
sns.distplot(dataset['Doors'], ax=axes[0])
axes[0].set_xlabel('Doors', fontsize=14)
axes[0].set_ylabel('Count', fontsize=14)
axes[0].yaxis.tick_left()
sns.boxenplot(x='Doors', y='Price', data=dataset, ax=axes[1])
axes[1].set_xlabel('Doors', fontsize=14)
axes[1].set_ylabel('Price', fontsize=14)
axes[1].yaxis.set_label_position("right")
axes[1].yaxis.tick_right()
plt.show()
dataset = pd.get_dummies(dataset)
dataset.head()
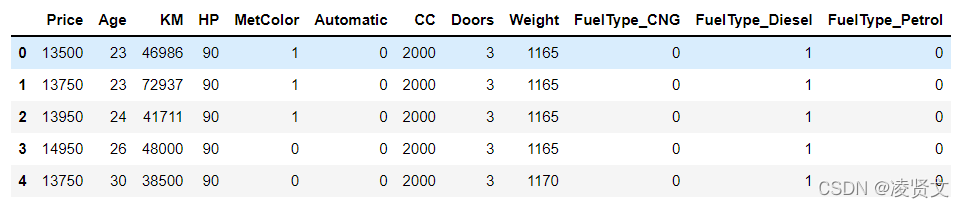
X = dataset.drop('Price', axis = 1).values
y = dataset.iloc[:, 0].values.reshape(-1,1)
#Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.25,
random_state=42)
print("Shape of X_train: ",X_train.shape)
print("Shape of X_test: ", X_test.shape)
print("Shape of y_train: ",y_train.shape)
print("Shape of y_test",y_test.shape)
Shape of X_train: (1077, 11)
Shape of X_test: (359, 11)
Shape of y_train: (1077, 1)
Shape of y_test (359, 1)
4.回归模型
线性回归
from sklearn.linear_model import LinearRegression
regressor_linear = LinearRegression()
regressor_linear.fit(X_train, y_train)
LinearRegression()
from sklearn.metrics import r2_score
#Predicting Cross Validation Score the Test set results
cv_linear = cross_val_score(estimator=regressor_linear,
X=X_train,
y=y_train,
cv=10)
#Predicting R2 Score the Train set results
y_pred_linear_train = regressor_linear.predict(X_train)
r2_score_linear_train = r2_score(y_train, y_pred_linear_train)
#Predicting R2 Score the Test set results
y_pred_linear_test = regressor_linear.predict(X_test)
r2_score_linear_test = r2_score(y_test, y_pred_linear_test)
#Predicting RMSE the Test set results
rmse_linear = (np.sqrt(mean_squared_error(y_test, y_pred_linear_test)))
print("CV: ", cv_linear.mean())
print('R2_score (train): ', r2_score_linear_train)
print('R2_score (test): ', r2_score_linear_test)
print("RMSE: ", rmse_linear)
CV: 0.8480754345159047
R2_score (train): 0.8702260786694702
R2_score (test): 0.8621869690956068
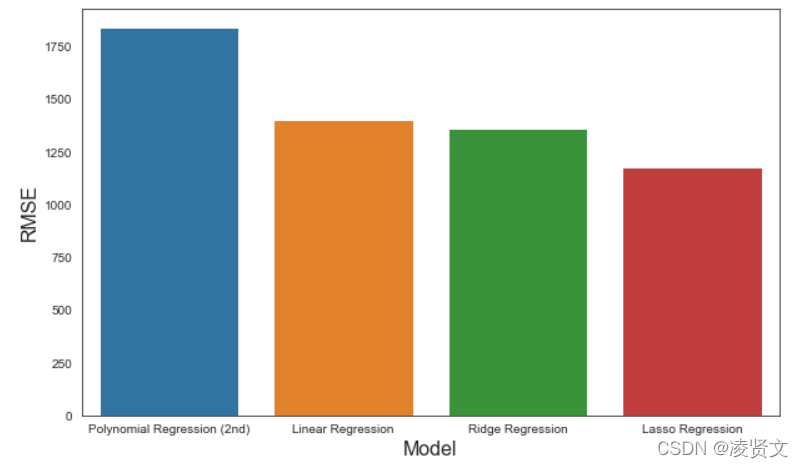
RMSE: 1398.4596051422188
二阶多项式回归
from sklearn.preprocessing import PolynomialFeatures
poly_reg = PolynomialFeatures(degree = 2)
X_poly = poly_reg.fit_transform(X_train)
poly_reg.fit(X_poly, y_train)
regressor_poly2 = LinearRegression()
regressor_poly2.fit(X_poly, y_train)
LinearRegression()
from sklearn.metrics import r2_score
#Predicting Cross Validation Score the Test set results
cv_poly2 = cross_val_score(estimator = regressor_poly2, X = X_train, y = y_train, cv = 10)
#Predicting R2 Score the Train set results
y_pred_poly2_train = regressor_poly2.predict(poly_reg.fit_transform(X_train))
r2_score_poly2_train = r2_score(y_train, y_pred_poly2_train)
#Predicting R2 Score the Test set results
y_pred_poly2_test = regressor_poly2.predict(poly_reg.fit_transform(X_test))
r2_score_poly2_test = r2_score(y_test, y_pred_poly2_test)
#Predicting RMSE the Test set results
rmse_poly2 = (np.sqrt(mean_squared_error(y_test, y_pred_poly2_test)))
print('CV: ', cv_poly2.mean())
print('R2_score (train): ', r2_score_poly2_train)
print('R2_score (test): ', r2_score_poly2_test)
print("RMSE: ", rmse_poly2)
CV: 0.8480754345159047
R2_score (train): 0.9157086185553889
R2_score (test): 0.7619825755103794
RMSE: 1837.8461795439769
岭回归
from sklearn.linear_model import Ridge
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
steps = [
('scalar', StandardScaler()),
('poly', PolynomialFeatures(degree=3)),
('model', Ridge(alpha=1777, fit_intercept=True))
]
ridge_pipe = Pipeline(steps)
ridge_pipe.fit(X_train, y_train)
Pipeline(steps=[('scalar', StandardScaler()),
('poly', PolynomialFeatures(degree=3)),
('model', Ridge(alpha=1777))])
from sklearn.metrics import r2_score
#Predicting Cross Validation Score the Test set results
cv_ridge = cross_val_score(estimator = ridge_pipe, X = X_train, y = y_train.ravel(), cv = 10)
#Predicting R2 Score the Test set results
y_pred_ridge_train = ridge_pipe.predict(X_train)
r2_score_ridge_train = r2_score(y_train, y_pred_ridge_train)
#Predicting R2 Score the Test set results
y_pred_ridge_test = ridge_pipe.predict(X_test)
r2_score_ridge_test = r2_score(y_test, y_pred_ridge_test)
#Predicting RMSE the Test set results
rmse_ridge = (np.sqrt(mean_squared_error(y_test, y_pred_ridge_test)))
print('CV: ', cv_ridge.mean())
print('R2_score (train): ', r2_score_ridge_train)
print('R2_score (test): ', r2_score_ridge_test)
print("RMSE: ", rmse_ridge)
CV: 0.7785178588873436
R2_score (train): 0.87000985560043
R2_score (test): 0.8697806448706517
RMSE: 1359.3852529159908
套索回归
from sklearn.linear_model import Lasso
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
steps = [('scalar', StandardScaler()), ('poly', PolynomialFeatures(degree=3)),
('model',
Lasso(alpha=2.36, fit_intercept=True, tol=0.0199, max_iter=2000))]
lasso_pipe = Pipeline(steps)
lasso_pipe.fit(X_train, y_train)
Pipeline(steps=[('scalar', StandardScaler()),
('poly', PolynomialFeatures(degree=3)),
('model', Lasso(alpha=2.36, max_iter=2000, tol=0.0199))])
from sklearn.metrics import r2_score
# Predicting Cross Validation Score
cv_lasso = cross_val_score(estimator = lasso_pipe, X = X_train, y = y_train, cv = 10)
# Predicting R2 Score the Test set results
y_pred_lasso_train = lasso_pipe.predict(X_train)
r2_score_lasso_train = r2_score(y_train, y_pred_lasso_train)
# Predicting R2 Score the Test set results
y_pred_lasso_test = lasso_pipe.predict(X_test)
r2_score_lasso_test = r2_score(y_test, y_pred_lasso_test)
# Predicting RMSE the Test set results
rmse_lasso = (np.sqrt(mean_squared_error(y_test, y_pred_lasso_test)))
print('CV: ', cv_lasso.mean())
print('R2_score (train): ', r2_score_lasso_train)
print('R2_score (test): ', r2_score_lasso_test)
print("RMSE: ", rmse_lasso)
CV: 0.7427712620107894
R2_score (train): 0.9273633923675705
R2_score (test): 0.9022945020939632
RMSE: 1177.509135460343
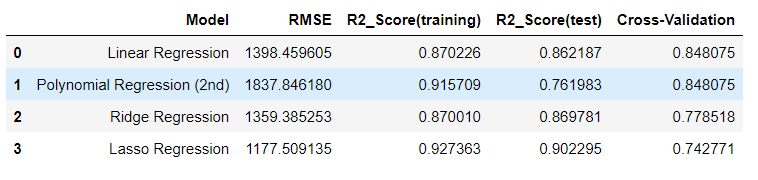
5.衡量误差
models = [
('Linear Regression', rmse_linear, r2_score_linear_train,
r2_score_linear_test, cv_linear.mean()),
('Polynomial Regression (2nd)', rmse_poly2, r2_score_poly2_train,
r2_score_poly2_test, cv_poly2.mean()),
('Ridge Regression', rmse_ridge, r2_score_ridge_train, r2_score_ridge_test,
cv_ridge.mean()),
('Lasso Regression', rmse_lasso, r2_score_lasso_train, r2_score_lasso_test,
cv_lasso.mean()),
]
predict = pd.DataFrame(data = models, columns=['Model', 'RMSE', 'R2_Score(training)', 'R2_Score(test)', 'Cross-Validation'])
predict
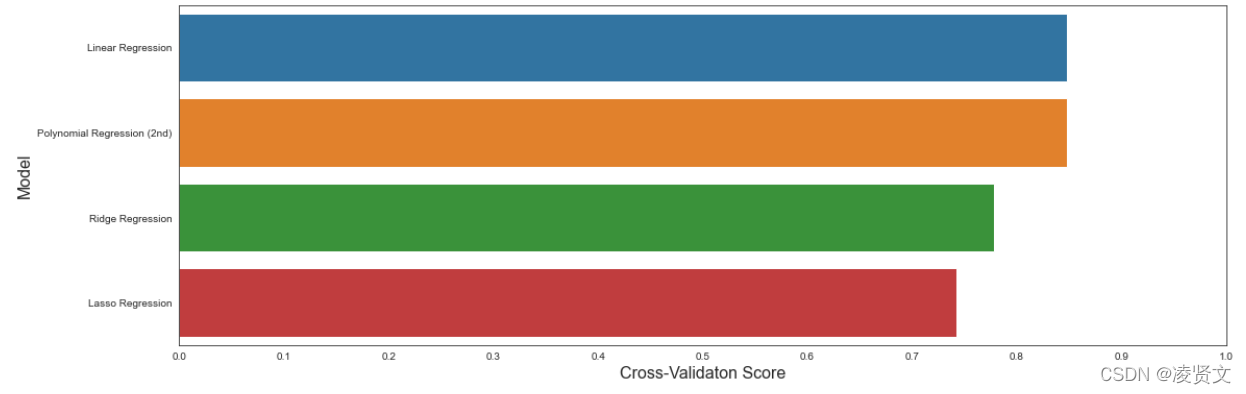
5、模型性能可视化
f, axe = plt.subplots(1,1, figsize=(18,6))
predict.sort_values(by=['Cross-Validation'], ascending=False, inplace=True)
sns.barplot(x='Cross-Validation', y='Model', data = predict, ax = axe)
#axes[0].set(xlabel='Region', ylabel='Charges')
axe.set_xlabel('Cross-Validaton Score', size=16)
axe.set_ylabel('Model',size=16)
axe.set_xlim(0,1.0)
axe.set_xticks(np.arange(0, 1.1, 0.1))
plt.show()
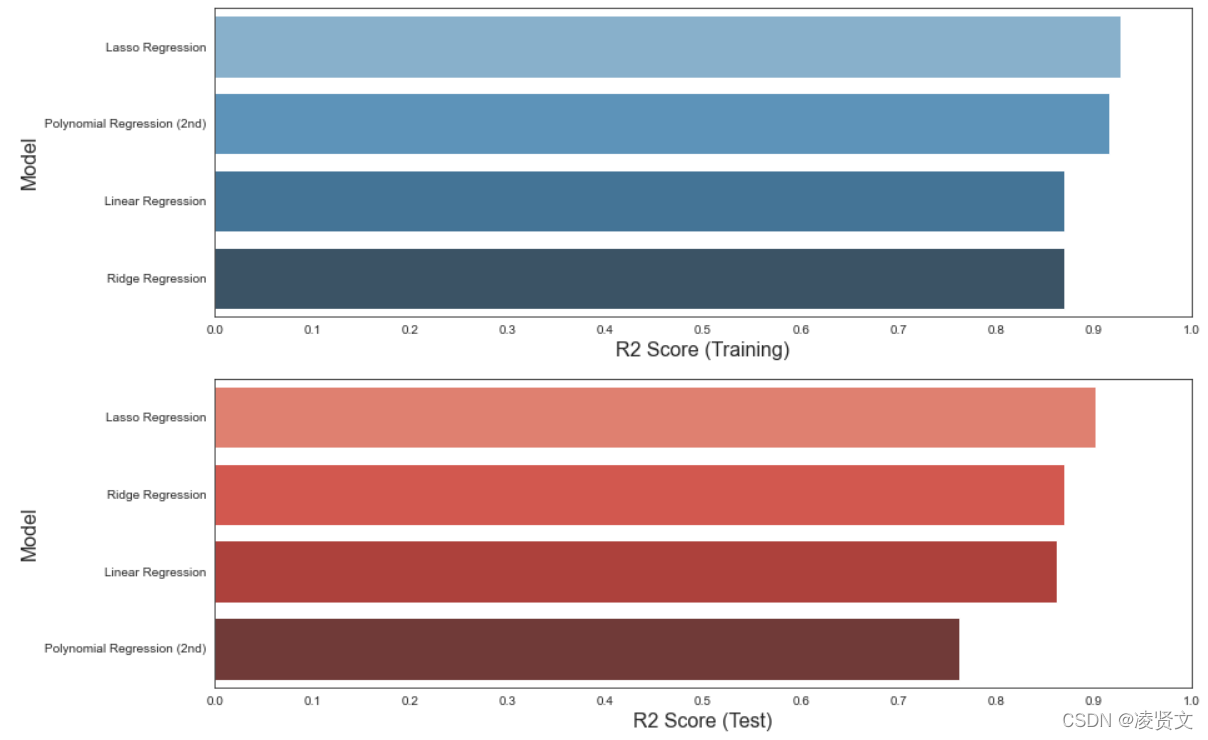
f, axes = plt.subplots(2, 1, figsize=(14, 10))
predict.sort_values(by=['R2_Score(training)'], ascending=False, inplace=True)
sns.barplot(x='R2_Score(training)',
y='Model',
data=predict,
palette='Blues_d',
ax=axes[0])
#axes[0].set(xlabel='Region', ylabel='Charges')
axes[0].set_xlabel('R2 Score (Training)', size=16)
axes[0].set_ylabel('Model', size=16)
axes[0].set_xlim(0, 1.0)
axes[0].set_xticks(np.arange(0, 1.1, 0.1))
predict.sort_values(by=['R2_Score(test)'], ascending=False, inplace=True)
sns.barplot(x='R2_Score(test)',
y='Model',
data=predict,
palette='Reds_d',
ax=axes[1])
#axes[0].set(xlabel='Region', ylabel='Charges')
axes[1].set_xlabel('R2 Score (Test)', size=16)
axes[1].set_ylabel('Model', size=16)
axes[1].set_xlim(0, 1.0)
axes[1].set_xticks(np.arange(0, 1.1, 0.1))
plt.show()
predict.sort_values(by=['RMSE'], ascending=False, inplace=True)
f, axe = plt.subplots(1, 1, figsize=(10, 6))
sns.barplot(x='Model', y='RMSE', data=predict, ax=axe)
axe.set_xlabel('Model', size=16)
axe.set_ylabel('RMSE', size=16)
plt.show()
6.结论
在这段代码中,我使用丰田卡罗拉数据集构建了4个回归模型。这些是线性回归、多项式回归、岭回归、套索回归,然后衡量并可视化模型的性能。



















 1358
1358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











