









1.特征表示

如图1(参考[理学和计算机的手段研究视觉问题(1995,Bruno Olshausen和 David Field)])所示,图片特征的提取过程可以如下:收集黑白照片->提取400个小碎片Si->随机提取另一个碎片->目标:Si合成T。
过程如下
1)选择一组 S[k],然后调整 a[k],使得Sum_k (a[k] * S[k]) 最接近 T。
2)固定住 a[k],在 400 个碎片中,选择其它更合适的碎片S’[k],替代原先的 S[k],使得Sum_k (a[k] * S’[k]) 最接近 T。
经过几次迭代后,最佳的 S[k] 组合,被遴选出来了。令人惊奇的是,被选中的 S[k],基本上都是照片上不同物体的边缘线,这些线段形状相似,区别在于方向。
不仅图像存在这个规律,声音也存在。他们从未标注的声音中发现了20种基本的声音结构,其余的声音可以由这20种基本结构合成
由此可选出结论:其它对象也可以由一些基本的结构合成
2.结构性特征表示
对于更结构化、更复杂的,具有概念性的对象的表示要更为复杂,以文为例,文本的表示如下:
Word(百万量级)->Term(10万量级)->Topic(千量级)->Doc
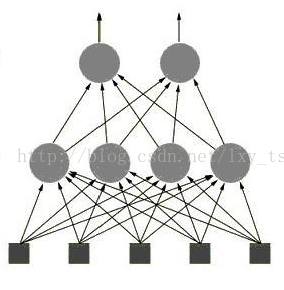
以图2所示网络为例,可以想像为最底层输入Word,经过中间层的特征表示(Term,Topic),最后输出Doc。
网络中的每个节点可视为一个人工神经细胞,如图3所示。
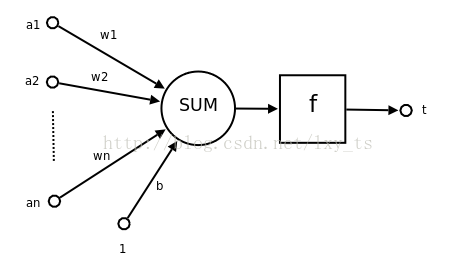
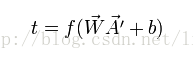
单个人工神经细胞的功能是求得输入向量与权向量的内积后,经一个非线性传递函数得到一个标量结果。
3.Deep Learning的基本思想
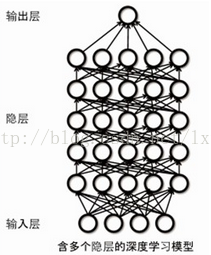
Deep Learning的目标可理解为对信息的分层表示(如图4):input->S1->S2->...->Sn->output
基本思想可理解为:堆叠多个层,即上一 层的输出作为下层的输入,实现输入信息的分级表达
4.Deep Learning训练过程
Deep Learning的训练过程可理解为分两步走:
- 训练网络(非监督学习)
- 调优(监督学习)
 (5)
(5)
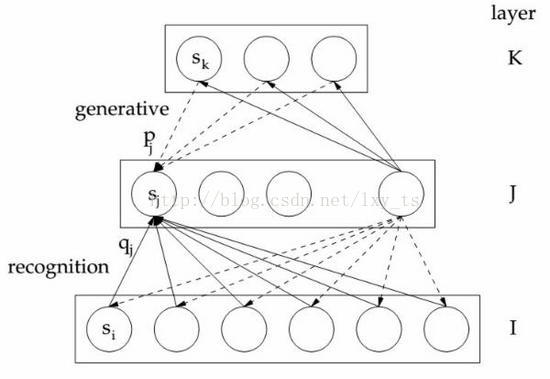
- Wake阶段(让想象接近现实):结点状态->调整向下权重->Target:输入
- Sleep阶段(让现实接近想象):输入->调整向上权重->Target:结点状态
 (6)
(6)















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









