







这周开始研究局部自相似描述子,由于网上关于这方面的研究比较少,所以决定自己研读两篇主要的文献,然后在这里记录下自己的理解。如果我能清楚记录应该算是学明白了吧~
第一篇是2007年CVPR《Matching Local Self-Similarities across Images and Videos》
http://www.vision.cs.chubu.ac.jp/CV-R/pdf/EliCVPR2007.pdf
第二篇是2009年ICCV上关于上一篇文章的延伸及详细细节改善《Efficient Retrieval of Deformable Shape Classes using Local Self-Similarities》
http://www.robots.ox.ac.uk/~vgg/publications-new/Public/2009/Chatfield09/chatfield09.pdf
所以,为什么要有局部自相似描述子呢?

上图中,除了这个爱心的形状,我们无法找到另外的四张图的相似点,所以为了在其他的图中找到爱心,大牛们发明了局部自相似描述子,也就是说按我的理解,这是一种同传统的灰度边缘都不相同的类似于骨架的匹配:)
一.《Matching Local Self-Similarities across Images and Videos》
图像中的每一个像素点有一个自相似描述子dq(dq怎么得到下边详细说),这是通过以q为中心的图像块和这个图像块周边更大的一个图像块相关联得到的(怎么个关联方式也在下面说),然后得到一个correlation surface,再将这个correlation surface转换到对数极坐标bin表示。
1.构造局部自相似描述子dq:
(1)以像素点q为中心,取一个小图像块(文中取5*5)再与一个更大的图像块(半径为40);
(2)对比5*5的patch与半径为40的region,计算SSD;
(3)将SSD转换为一个“correlation surface” Sq(x,y):
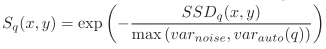
其中var(noise)是一个表示可接受光照变化的常数,var(auto)是以q为中心的周边非常小领域内所有patch(半径1)差的最大方差;
(4)接着,“correlation surface” Sq(x,y)被转换到对数极坐标中,然后分割成80个bins(20个角度,4个径向间隔)。对于每一个bin,选取bin中的最大值作为这个bin的值;
(5)由这80个bin构成了点q的局部自相似描述子dq,最后将这个描述子向量归一化到[0,1]范围内。
2.局部自相似描述子的特性与优势:
(1)局部自相似描述子表示图像的局部特性,而非全局,这使描述子能应用于更多有挑战性的图像;
(2)对数极坐标导致了局部仿射变形;
(3)选取bin中的最大值作为bin的值,使得描述子对于最佳匹配位置表现不敏感;
(4)运用patch而非单个pixel能获取更多的图像信息;
(5)局部自相似描述子不仅包含了目标的骨架,更包含了颜色、边缘等丰富信息。
3.检测步骤:
(1)分别在template F中和待检测的图像G中计算各自的局部自相似描述子;
(2)F中的全部描述子组成“描述集(ensemble of descriptor)”,当在G中能找到一个与F相似的“描述集”就意味着在G中能够检测到F(这里的相似并不局限于描述子的值更是相对几何位置的相似);
(3)不是描述集中的每一个描述子都是有信息量的(文中提到两种“saliency”和“homogeneity”),所以我们要在归一化描述子之前筛除掉那些没有信息量的描述子;
(4)匹配方法:改进了文章《Detecting irregularities in images and in video》中的“ensemble matching”算法。实践中,将F的描述子聚合为一个简单的描述集,然后运用《Detecting Irregularities in Images and in Video》中的方法在G中找寻相似的描述集,文章中用基于曼哈顿距离(L1 distance)的逻辑S函数(sigmoid function)衡量描述子之间的相似性,ensemble matching 在G中构造了一个密集的似然地图(likelihood map),每一点对应于与F的相似度,其中相似度最高的那一点便是F在G中的匹配位置了。
4.尺度处理:
由于自相似性可能出现在不同的尺度和不同大小的区域上,所以文中采用了高斯图像金字塔来获得多个尺度的描述子。对所有的尺度采用相同大小的参数(patch size,surrounding region),每个尺度各自生成自己的描述集,并且独立搜索而生成各自的似然图。
不同尺度描述子的组合:1)首先将每个对数似然图根据在其尺度中的的描述符的数目进行归一化;2)然后根据每个似然面的稀疏度使用加权平均来组合。















 7433
7433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









