






SQLite,是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。它能够支持Windows/Linux/Unix等等主流的操作系统,同时能够跟很多程序语言相结合,比如C、Java、Python等,同样比起Mysql、PostgreSQL这两款开源的世界著名数据库管理系统来讲,它的处理速度比他们都快。

一、数据库
1. 数据库中的表
一个数据库文件里可以有多张表。比如 students.db 里包含"学生信息表"和"课程信息表"。
表由记录构成, 比如“学生信息表”里的每个记录,代表一个学生的信息。
记录由字段构成,描述一个事物的多个属性。比如学生记录,可以由name ,id,age, gender,gpa 等字段构成。
2.字段
字段是有"类型"的。比如
字段名 数据类型
name text 字符串
gpa real 小数
age integer 整数
profile text
photo blob 二进制数据(如图片)
birthday date 日期(本质上就是text)
register time datetime 日期+时间(本质上就是text)
3. SQL语句
SQL即结构化查询语言(Structured Query Language),是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。SQL语句无论是种类还是数量都是繁多的,很多语句也是经常要用到的,SQL查询语句就是一个典型的例子,无论是高级查询还是低级查询,SQL查询语句的需求是最频繁的。
SQLite虽然很小巧,但是支持的SQL语句不会逊色于其他开源数据库,它支持的SQL包括:
ATTACH DATABASE
BEGIN TRANSACTION
comment
COMMIT TRANSACTION
COPY
CREATE INDEX
CREATE TABLE
CREATE TRIGGER
CREATE VIEW
DELETE
DETACH DATABASE
DROP INDEX
DROP TABLE
DROP TRIGGER
DROP VIEW
END TRANSACTION
EXPLAIN
expression
INSERT
ON CONFLICT clause
PRAGMA
REPLACE
ROLLBACK TRANSACTION
SELECT
UPDATE
常用命令

CREATE

INSERT

二、python控制SQLite数据库
sqlite3 数据库是 Python 自带的数据库,甚至不需要额外安装模块,而且操作简单。
1. 需要的模块
import sqlite32. 创建数据库并写入数据
import sqlite3db = sqlite3.connect("c:/tmp/test2.db") #连接数据库,若不存在则自动创建#文件夹 c:/tmp 必须事先存在,connect不会创建文件夹cur = db.cursor() #获取光标,要操作数据库一般要通过光标进行sql = '''CREATE TABLE if not exists students (id integer primary key,name text, gpa real, birthday date, age integer, picture blob)''' #如果表 students 不存在就创建它cur.execute(sql) # 执行SQL命令cur.execute("insert into students values(1600, '张三', 3.81, '2000-09-12', 18,null)") #插入一个记录mylist = [(1700, '李四', "3.25",'2001-12-01',17,None),(1800, '王五', "3.35",'1999-01-01',19,None)]for s in mylist: # 依次插入mylist中的每个记录cur.execute('INSERT INTO students VALUES(?,?,?,?,?,?)',(s[0], s[1], s[2],s[3],s[4],s[5])) # ?对应于后面某项db.commit() # 真正写入,写入操作都需要这个cur.close() # 关闭光标db.close() # 关闭数据库
3. 数据库的查询和修改
SELECT语句

检索数据框
import sqlite3db = sqlite3.connect("c:/tmp/test2.db")cur = db.cursor()sql = 'select * from students' #检索全部记录cur.execute(sql)x = cur.fetchone() #fetchone 取满足条件的第一条记录print(x) #=>(1600, '张三', 3.81, '2000-09-12', 18, None)print(x[1]) #=>张三for x in cur.fetchall(): #fetchall取得所有满足条件的记录print(x[:-2]) #age和picture字段不打出cur.execute("SELECT * FROM students WHERE name='Jack'")x = cur.fetchone()if x == None:print("can't find Jack")cur.close()db.close()
查找gpa > 3.3的记录,题取其中三个字段,按年龄降序排列
import sqlite3db = sqlite3.connect("c:/tmp/test2.db")cur = db.cursor()sql = 'select name, gpa, age from students where gpa > 3.3order by age desc'#查找gpa > 3.3的记录,题取其中三个字段,按年龄降序排列cur.execute(sql)x = cur.fetchall()if x != []:print("total: ", len(x)) #=>2for r in x:print(r)cur.close()db.close()
4. 数据库的更新
UPDATE
UPDATE students SET gpa = 3.9将所有记录的gpa设置成3.9UPDATE students SET gpa = 3.9, age = 18 WHERE name = '李四'
修改 李四 的gpa和年龄 。若李四不存在,则无效果
import sqlite3db = sqlite3.connect("c:/tmp/test2.db")cur = db.cursor()sql = 'UPDATE students SET gpa = ?, age = ? WHERE name = ?'cur.execute(sql,(4.0,20,'李四')) #元组三个元素分别对应三个 ?#修改 李四 的gpa和年龄 。若李四不存在,则无效果db.commit() #写入操作必须cur.close()db.close()
删除年龄小于18的记录
DELETE FROM students WHERE age < 18删除年龄小于18的记录DELETE FROM students删除全部记录别忘了最后 commit
删除表
DROP TABLE IF EXISTS students删除students 表别忘了最后 commit
列出数据库中所有表和表的结构
列出数据库中所有的表和表的结构import sqlite3db = sqlite3.connect("c:/tmp/test3.db")cur = db.cursor()sql = 'CREATE TABLE if not exists table2 (id integer, name text)'cur.execute(sql) #执行SQL命令sql = 'CREATE TABLE if not exists table1 (id integer, schook text)'cur.execute(sql)db.commit()cur.execute('select name from SQLITE_MASTER where type="table" order by NAME')x = cur.fetchall()if x != []:print(x)cur.execute("PRAGMA TABLE_INFO (table1)")print (cur.fetchall())cur.close()db.close()
5.注意事项
1.对于修改表的操作,如插入,删除,更新,关闭数据库前不要忘了commit,否则可能无效。
2. 必要时用 try...except语句来避免数据库不存在,表不存在时的导致的 runtimeerror。
三、实战操作 (Fasta序列存入SQLite中)
创建数据库,读取Fasta序列并导入
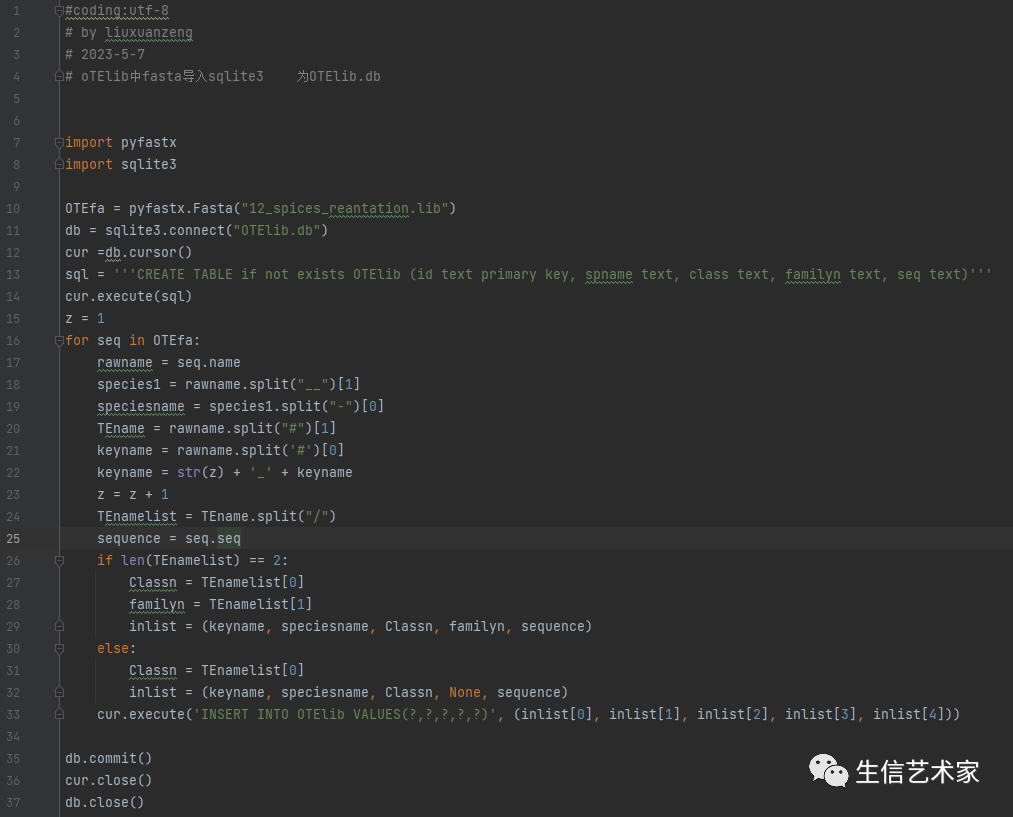
在数据库中根据关键词挑选想要的序列
import sqlite3db = sqlite3.connect("OTElib.db")cur =db.cursor()cur.execute("SELECT * FROM OTElib WHERE class='RC'")x = cur.fetchall()
最后
在python中 处理Fasta或者Fastq时,这里强烈推荐一个很好用的模块
Pyfastx,文章发表在生信顶刊《Briefings in Bioinformatics》上,Li Heng大神亲测推荐。
Pyfastx模块的特点
-
随机访问压缩的FASTA/Q文件
-
逐条迭代读取FASTA文件
-
计算FASTA文件的N50和L50
-
计算序列的GC含量和核酸组成
-
计算反向互补序列
-
良好的兼容性,支持分析非标准的FASTA文件
-
支持FASTQ文件的碱基质量值转换
-
提供命令行接口用于拆分FASTA/Q文件
之后可以在公众号中详细介绍Pyfastx模块。
以上内容仅为个人总结,如有错误之处敬请批评!
联系我们:
生信艺术家














 6566
6566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









