







简单来解释的话 :索引就像书的目录一样,目的是为了增加查询效率。
索引是存储引擎用于快速找到记录的一种数据结构。索引对数据库优化非常关键。尤其在数据量比较大的时候更加明显,在数据量小的时候不恰当的索引对性能影响比较小,但当数据量逐渐增大时,性能则会急剧下降。
select name from user where id=5;假设id列上有索引,那么MySQL会直接使用该索引找到id=5这一行数据并返回,也就是MySQL会先在索引上按值进行查找,然后返回包含该列的值的数据行。
索引可以包含一个或者多个列,包含多个列的时候要注意顺序(联合索引),因为MySQL有最左前缀原则。
最左前缀原则:mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,=和in可以乱序
select * from where test a=1 and b=2 and c>3 and b=5;
假设联合索引为(a,b,c,d) 那么d就不会用到索引,因为C用了>,所有不会再去匹配索引
(a,b,d,c)那么都会用到索引
MySQL索引类型
在MySQL中不同的存储引擎索引方式是不同的,不是所有的存储引擎都支持所有类型索引。
索引基础知识:引用https://juejin.im/post/5b55b842f265da0f9e589e79
首先Mysql的基本存储结构是页(记录都存在页里边):
各个数据页可以组成一个双向链表
而每个数据页中的记录又可以组成一个单向链表:
每个数据页都会为存储在它里边儿的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录,以其他列(非主键)作为搜索条件:只能从最小记录开始依次遍历单链表中的每条记录。
所以说,如果我们写select * from user where username = 'Java3y'这样没有进行任何优化的sql语句,默认会这样做:
- 定位到记录所在的页
- 需要遍历双向链表,找到所在的页
- 从所在的页内中查找相应的记录
- 由于不是根据主键查询,只能遍历所在页的单链表了
很明显,在数据量很大的情况下这样查找会很慢!
索引做了些什么可以让我们查询加快速度呢?其实就是将无序的数据变成有序(相对):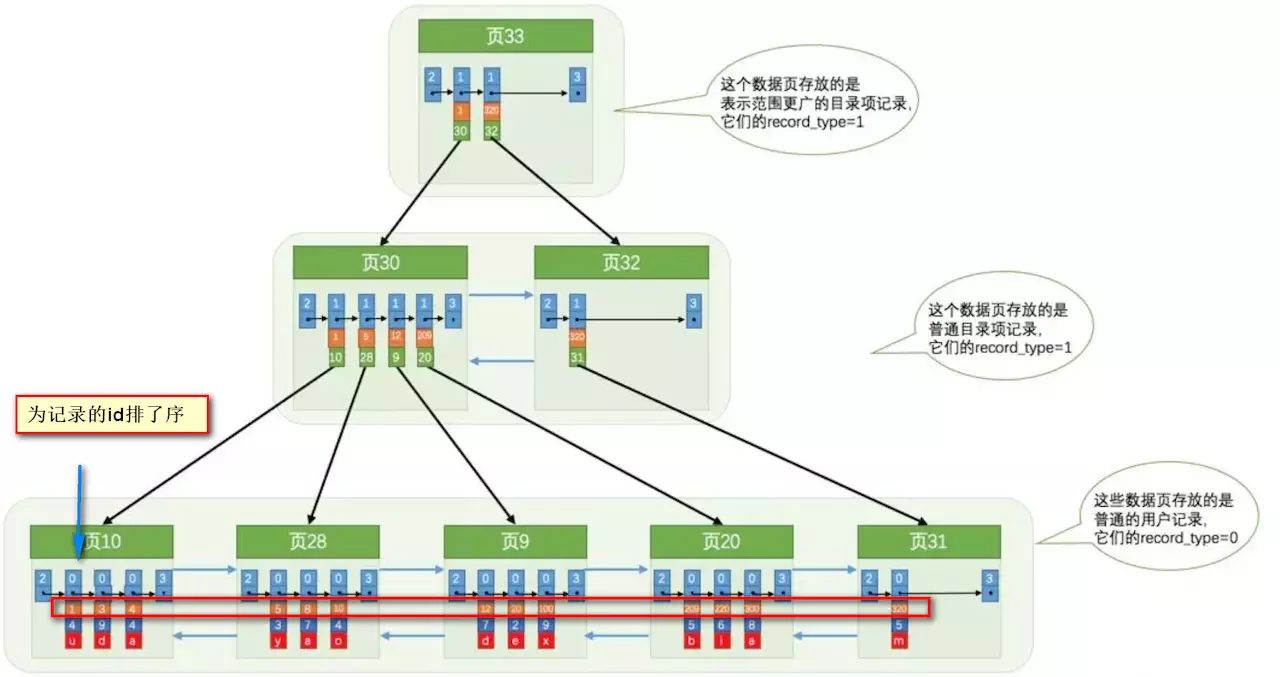
要找到id为8的记录简要步骤:
如果没有索引需要遍历整个双向链表,但是如果从索引中通过二分查找的 速度明显就快很多
底层结构就是B+树,B+树作为树的一种实现,能够让我们很快地查找出对应的记录。
B-Tree索引
使用B树的存储结构,大多数存储引擎都支持该索引 上图演示的就是B树索引。
哈希索引
哈希索引,InnoDB是自适应哈希索引的(hash索引的创建由InnoDB存储引擎引擎自动优化创建,我们干预不了)!
















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









