







992. K 个不同整数的子数组
-
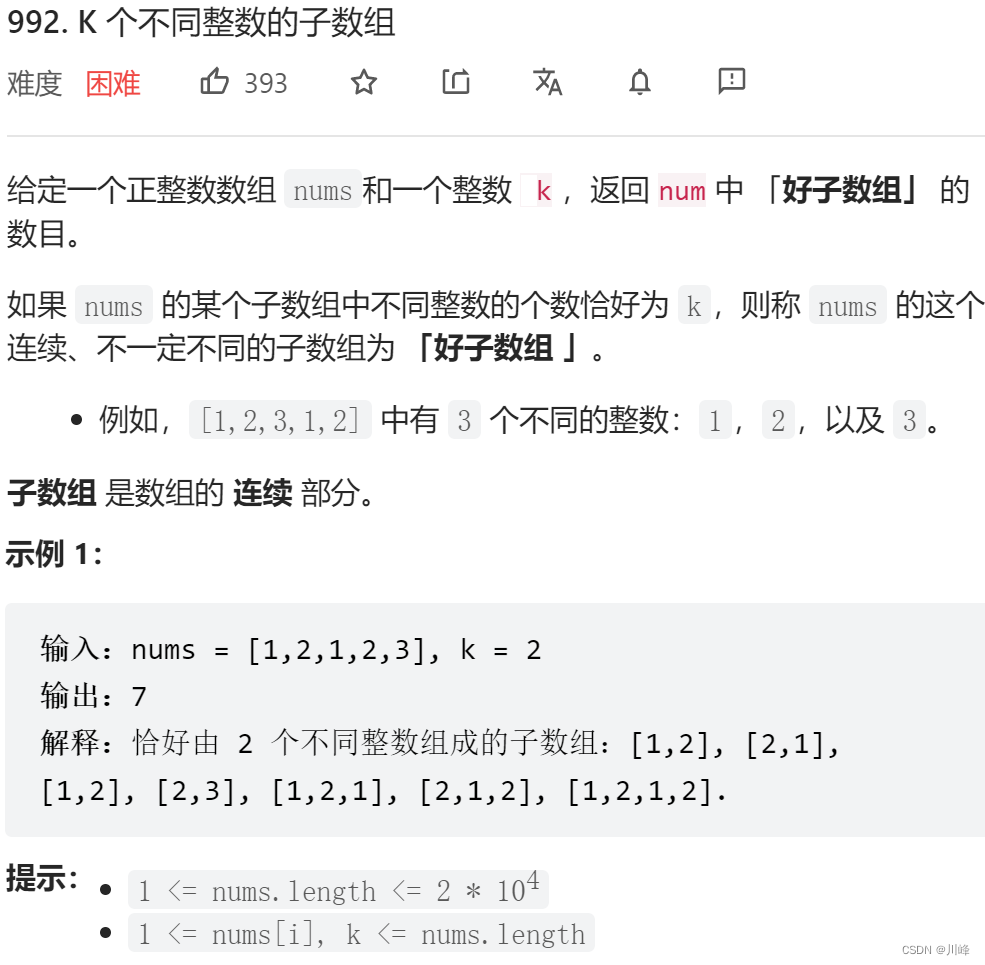
滑动窗口 , 题目问题转化为: 求 「最多存在 K 个不同整数的子数组的个数」 与 「最多存在 K - 1 个不同整数的子数组的个数」 之差, 就是题目所求的 「恰好存在 K 个不同整数的子数组的个数」 , 最终问题就变成求解滑动窗口内,以 R 为右边界的、包含 k 个不同整数 的子数组个数,它其实就是窗口区间的长度 R - L + 1 。
-
注意:这个题没有相关经验根本做不出来,之所以求 最多 而不是求 恰好 ,是因为求 恰好 的话, 左边界 固定时, 右边界是不固定 ,也就是 R可能往回走 ,这样不符合滑动窗口的逻辑,所以求 最多 ,这时 R是固定的,而左边界L也可以向右移动来计算 ,记住, 滑动窗口不能走回头路 。
对于一个固定的左边界来说,满足「恰好存在 K 个不同整数的子区间」的右边界 不唯一,且形成区间。
示例1:左边界固定的时候,恰好存在2个不同整数的子区间为 [1,2],[1,2,1],[1,2,1,2] ,总数为 3。其值为下标 3 - 1 + 1,即区间 [1..3] 的长度。

需要找到左边界固定的情况下,满足「恰好存在 K 个不同整数的子区间」最小右边界和最大右边界。对比以前我们做过的,使用双指针解决的问题的问法基本都会出现「最小」、「最大」这样的字眼。
把原问题转换成为容易求解的问题
友情提示:这里把「恰好」转换成为「最多」需要一点求解「双指针(滑动窗口)」问题的经验。建立在熟练掌握这一类问题求解思路的基础上。
把「恰好」改成「最多」就可以使用双指针一前一后交替向右的方法完成,这是因为对于每一个确定的左边界,最多包含 K 种不同整数的右边界是唯一确定的,并且在左边界向右移动的过程中,右边界或者在原来的地方,或者在原来地方的右边。
而「最多存在 K 个不同整数的子区间的个数」与「恰好存在 K 个不同整数的子区间的个数」的差恰好等于「最多存在 K - 1 个不同整数的子区间的个数」。

因此原问题就转换成为求解「最多存在 K 个不同整数的子区间的个数」与「最多存在 K - 1 个不同整数的子区间的个数」,它们其实是一个问题。
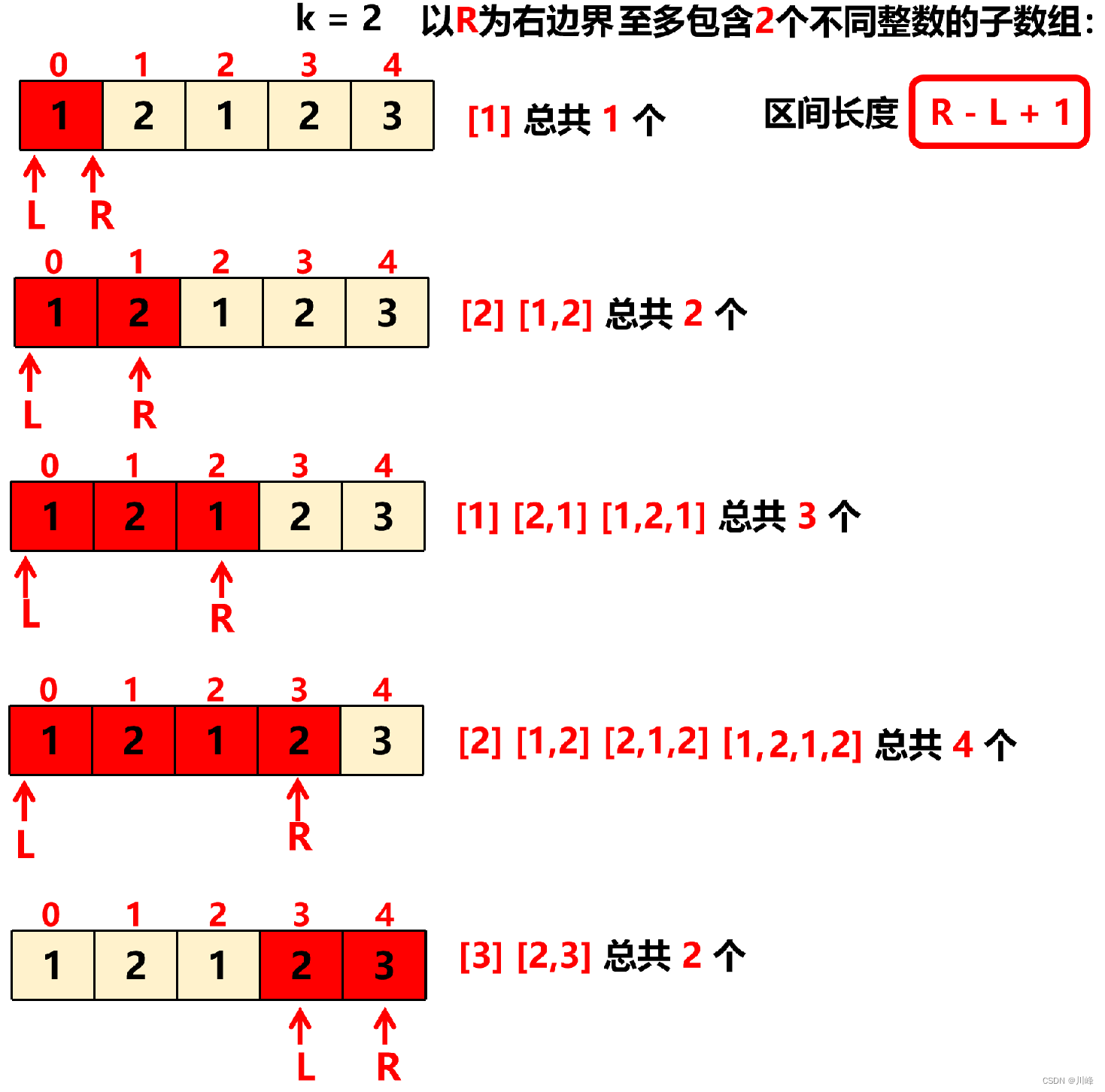


如果你单看这个代码,貌似也不是很难,但是本题难的是如何才能想的到用 最多 (K) - 最多 (K - 1) = 恰好 (K) 的思想来解决,我觉得如果不是做过这道题的,应该一般人想不出来。而且还有一个关键的点就是 最多 (K) 的答案就是窗口 [L, R] 区间的长度。这一点也是需要观察出来的。这两个点应该是本题最大的难点了。
注意:上面代码使用的是数组 map 来计数统计的,你也可以直接使用原生的 HashMap,只是代码会稍微更长一些。
30. 串联所有单词的子串


-
滑动窗口 ,先对 words数组进行词频计数统计 ,记作 wordsMap , 将 words 中每个 单词长度记为 N , i 遍历 [0, N) 以 每个字符为起始点进行一次滑动窗口遍历 。
-
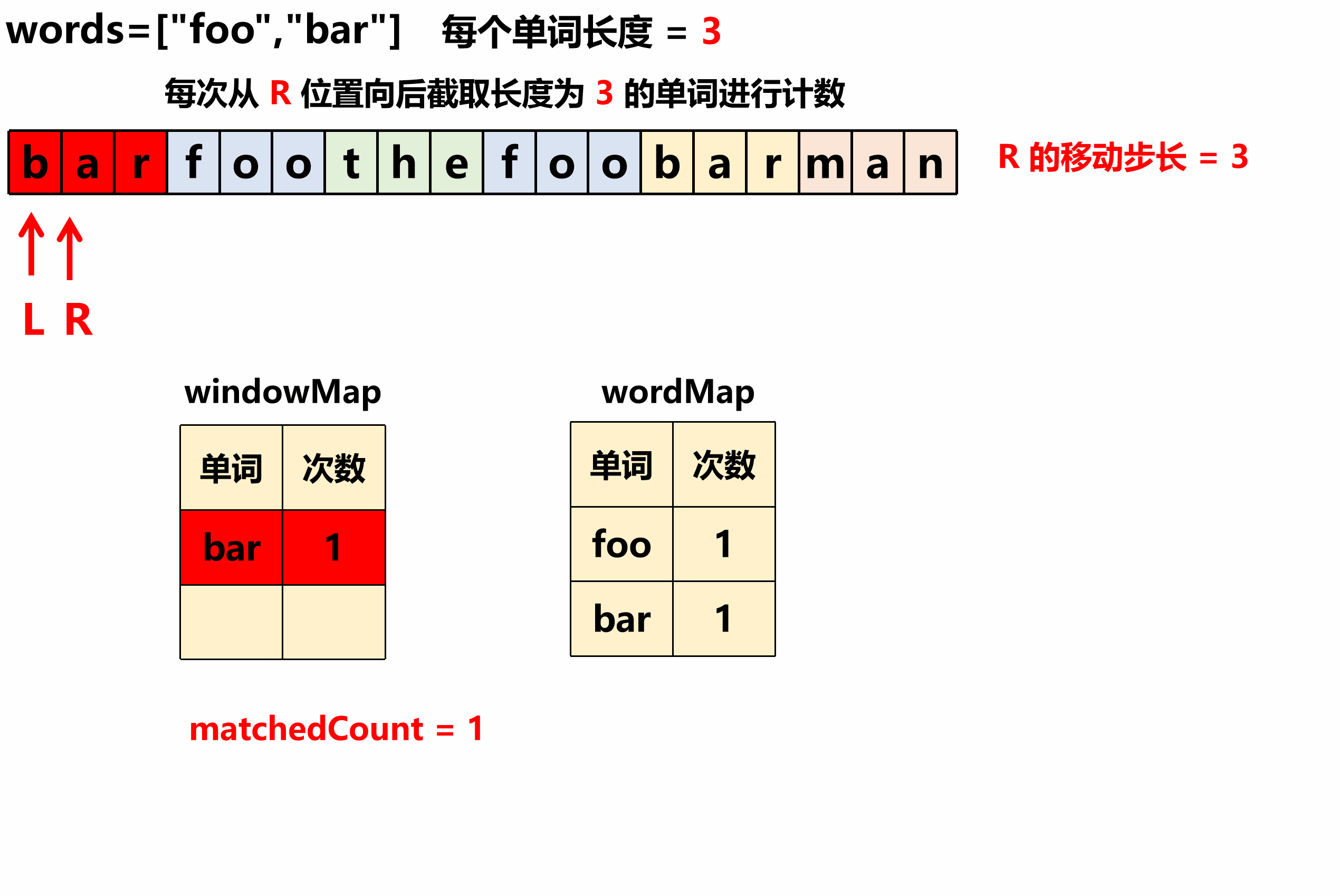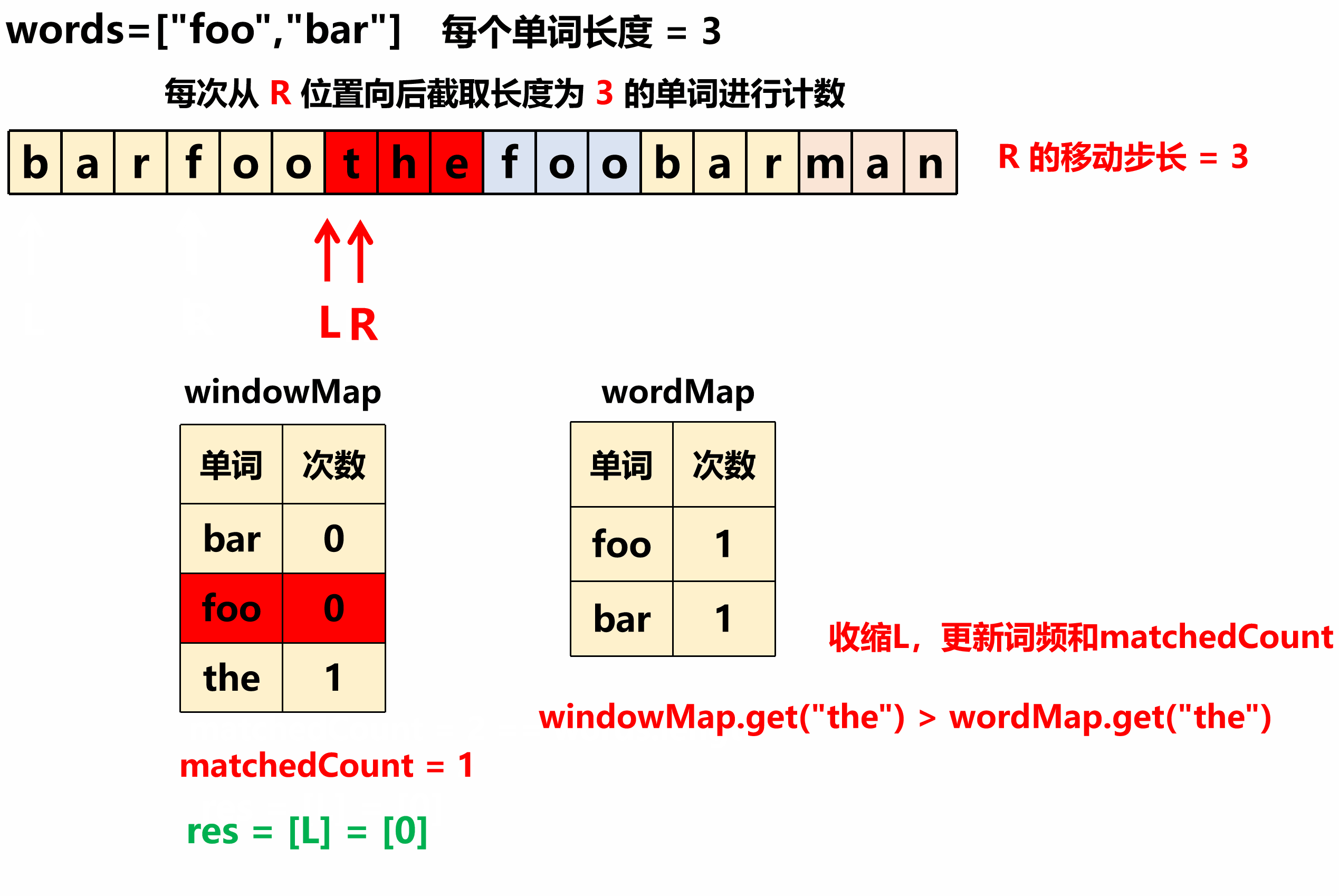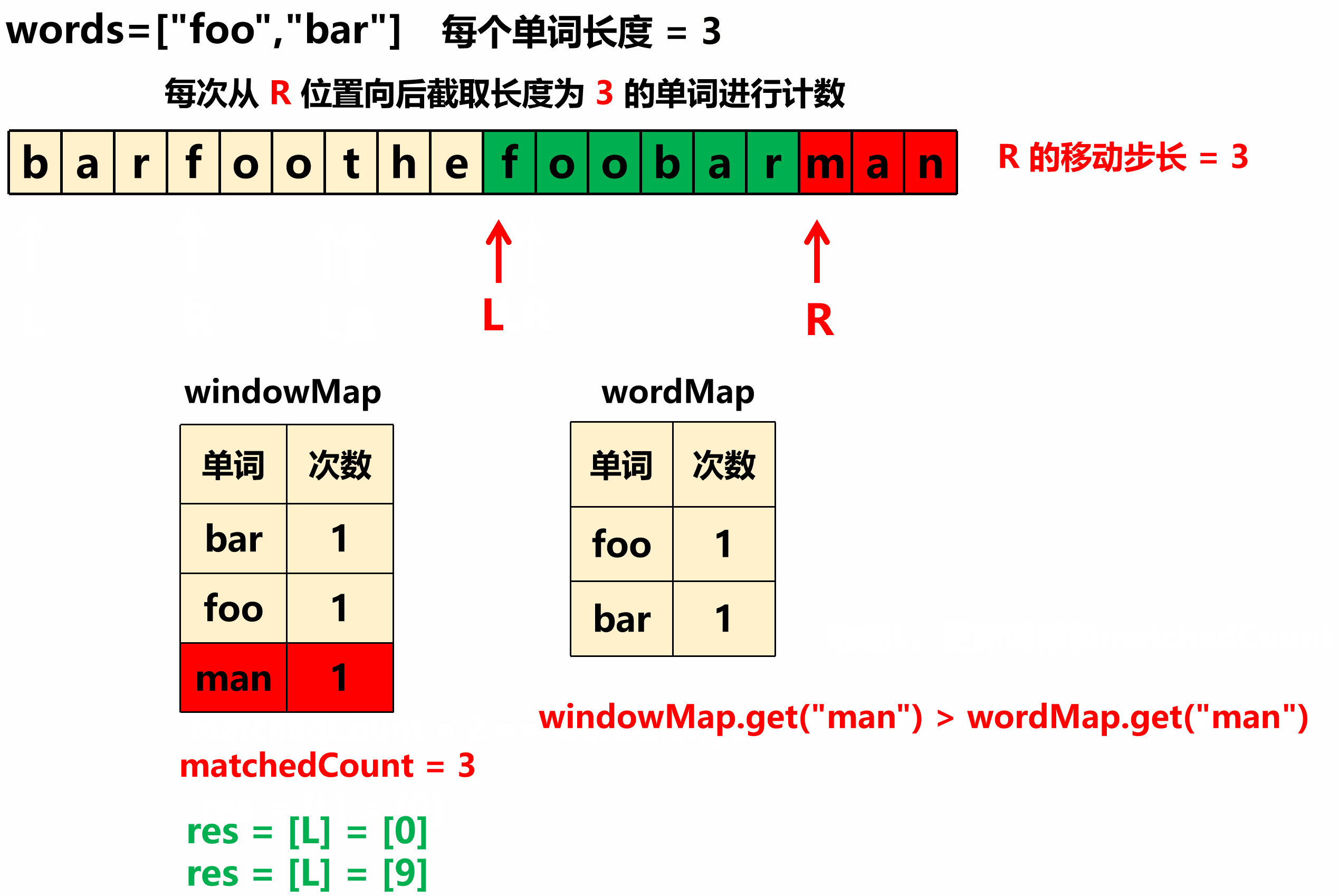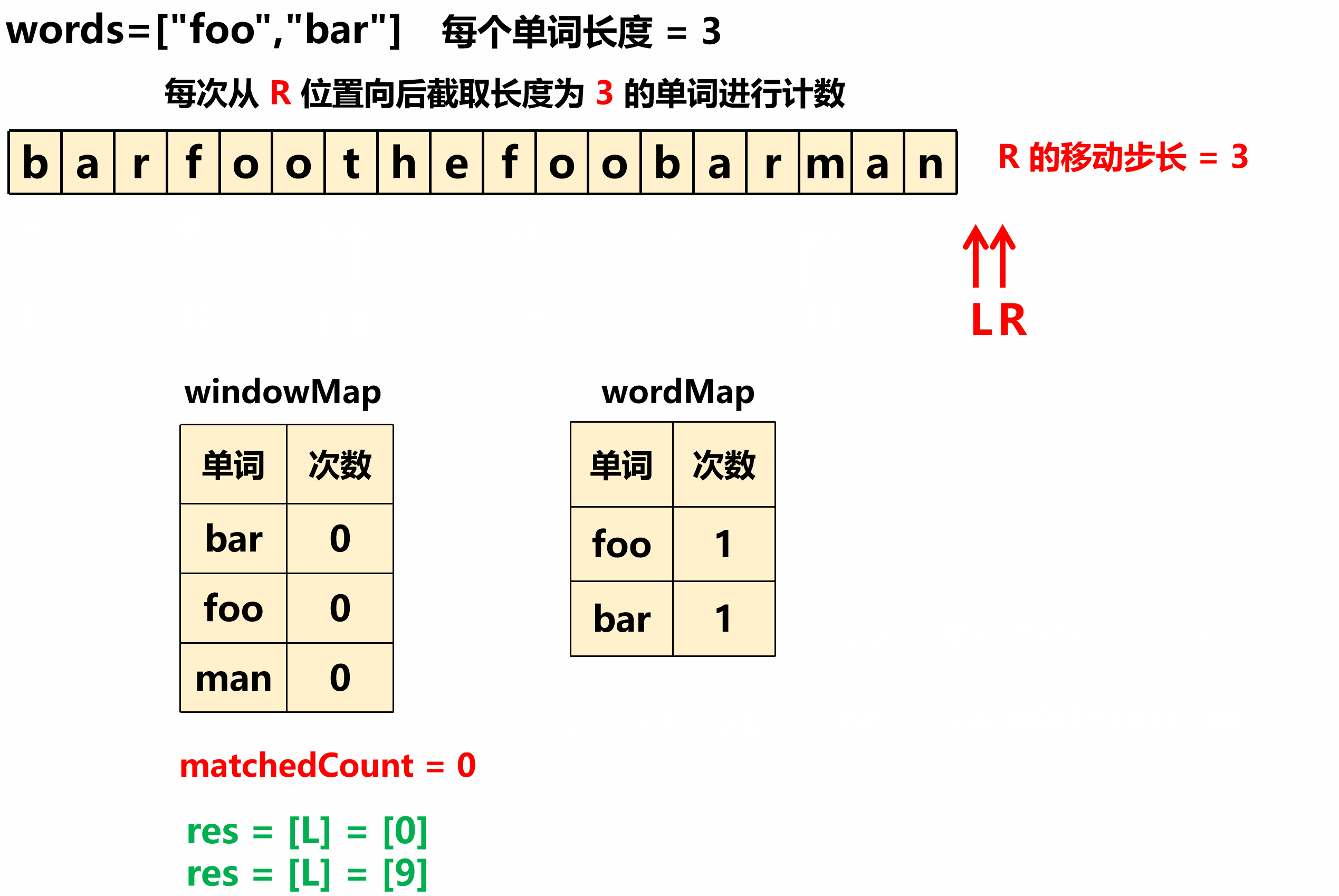
窗口的左右边界 L 和 R 起始点从 i 开始, R 每次的步长为一个单词的长度 N ,用一个 windowMap 对窗口内的每个单词进行 词频计数统计,
-
每次从 R 开始向后截取 长度为 N 的一个单词,然后对该单词用 windowMap 进行计数,每计数一个单词就将总的 匹配数量 matchedCount++ 。
-
1)如果当前单词词频数 windowMap["curWord"] > wordsMap ["curWord"] ,就不断的循环从窗口 左边界 移出一个长度 N 的单词,对应 windowMap 中的 词频减1 (在移动 L 之前减) ,同时总匹配数量 matchedCount -- ;直到当前单词 在两个map中的词频数相等 为止;
-
2) 如果 当前单词在两个map中的词频数相等 ,这时判断一下如果 总匹配数量 matchedCount == 单词总个数 ,则找到一个解,将 左边界L下标 收集答案即可。
要理解这个算法有两个关键点:一个是 words 数组中的每个单词的词频数和窗口内的词频数必须相等,另一个是窗口内的单词个数必须和 words 数组中的单词个数相等。 例如,words=["foo", "bar", "foo"],某个时刻窗口内是“foofoobar”,此时foo在窗口内出现2次,在words中也出现2次,bar在窗口内出现1次,在words中也出现1次,并且窗口内单词个数是3恰好等于words数组的长度,这就是符合答案要求的一个窗口,记录窗口的左边界即可。
下面是这个算法过程的执行动画示意:
收集答案的时机是:遇到的每个单词在两个词频Map中的计数都相等,并且窗口内单词个数等于words数组的长度时。

这个代码与常规的滑动窗口不同的一个点是在滑窗的 for 循环外面又套了一层 for 循环,常规的滑窗相当于是从左到右执行一趟滑窗算法,而这个题是会执行 N 趟滑窗算法(其中 N 是 words 里每个单词的长度) 。
-
如果只是从 0 位置开始进行一次滑动窗口遍历( R 步长为 N 、每次从 R 截取长度 N 的单词),则有可能完全错过正确答案。如下图所示:

如上图所示,上面例子如果只进行一次滑动窗口遍历,则会完美滴错过所有正确答案。为什么会这样呢?这是因为在常规的滑窗算法中,都是逐个遍历字符处理的,R 的步长是 1,但是本题滑窗遍历的步长是一个单词的长度,所以为了不会漏掉答案,就必须以一个单词长度的每个位置为出发点,进行一次滑窗。
763. 划分字母区间
-
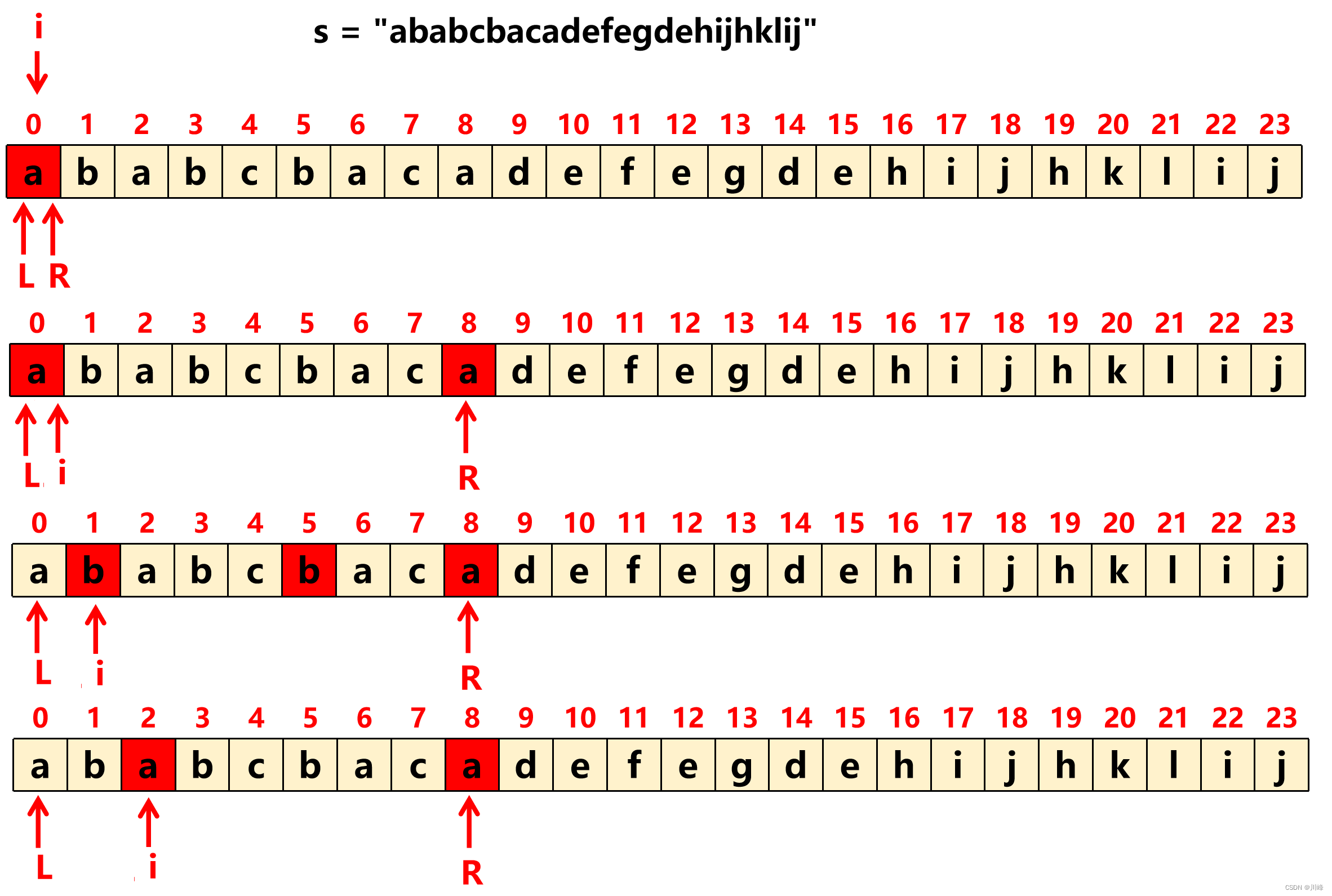
滑动窗口 ,先用一个 Map 记录 s 中 每个字符出现的最远位置下标 , 然后遍历 s 中的每个字符:
-
对遇到的每一个字符,尝试将窗口右边界 R 移动到当前 s[i] 字符出现的 最远位置 ,R = max(R, map[s[i]]),
-
每当 i 追上 R 时( i==R ),收集答案为窗口长度 R - L + 1 ,此时 [L,R] 范围内的字符都没有超出 R 右边,同时移动 L 到 R 的下一个位置 L = R + 1 。
-
每次都将 R 更新为当前字符出现最远位置的含义:如果当前字符 a 出现的最远位置在后面,说明后面存在着重复的 a,而题目 要求 是让相同字符只能出现在同一个窗口内,重复的字符不能夸窗口存在,因此需要向右扩充窗口右边界 R ,以便使后面与当前重复的字符被包含进当前窗口内 。


剑指 Offer 57 - II. 和为s的连续正数序列
-
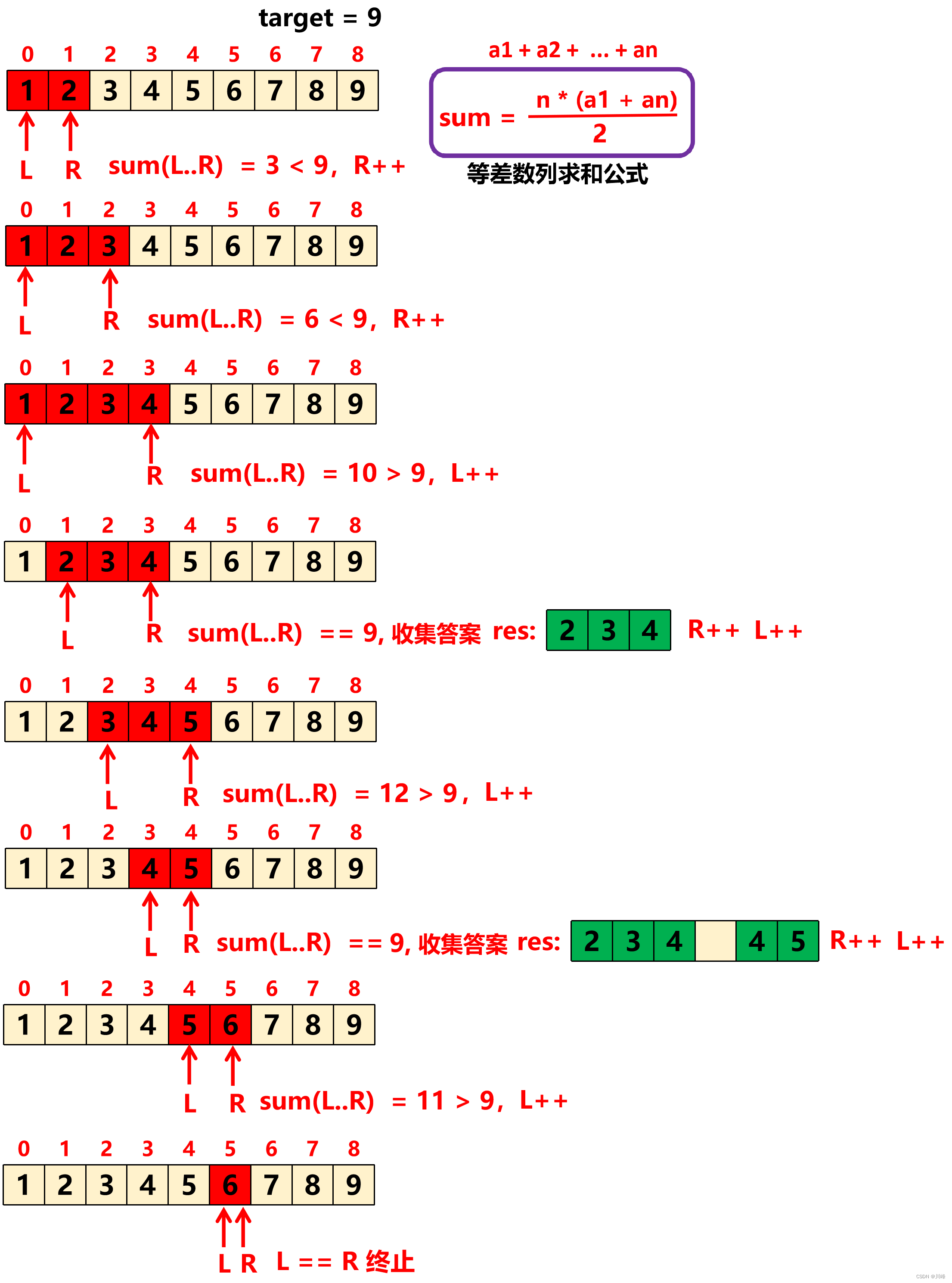
1. 滑动窗口 / 双指针 + 求和公式 , 初始化 窗口左边界 L = 1, 右边界 R = 2 ,只要 L < R ,就不断的利用等差数列求和公式 s = a1+a2+..+an = n * (a1 + an) / 2 计算出当前 [L..R] 范围内的和, sum = (R - L + 1) * (L + R) / 2 ,
-
① 如果 sum==target ,将 [L..R] 范围内的数输出到结果中保存,同时向右移动 L 和 R 到下一个位置继续。
-
② 如果 sum < target ,说明 sum 不够大,向右移动 R 使 sum 变得更大,
-
③ 如果 sum > target , 说明 sum 太大, 向右移动 L 使用 sum 变得更小。
-
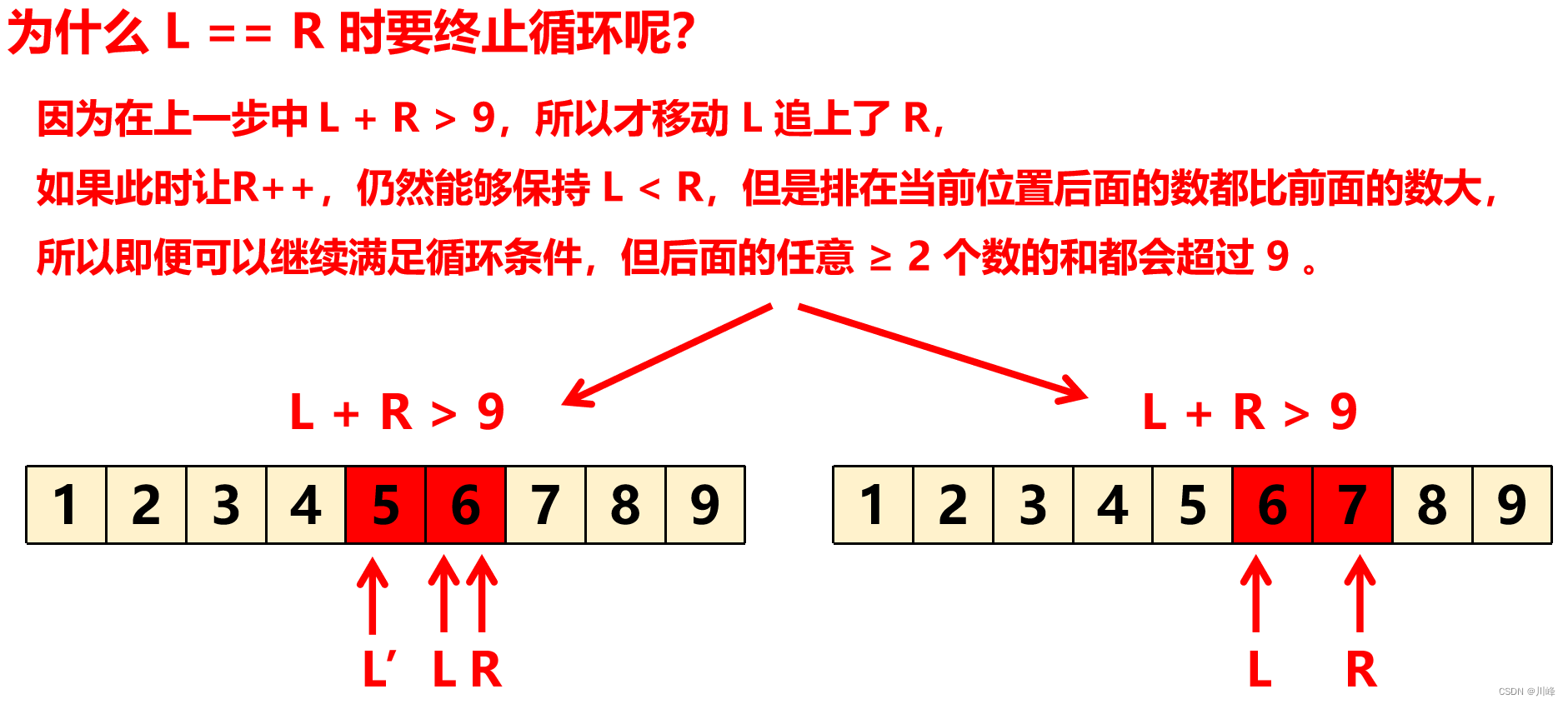
注意:整个过程中窗口是向右移动的, L 和 R 都是不回退的,当 L ≥ R 时,退出循环,这时无法形成窗口,因为题目要求 至少含有两个数,所以窗口大小至少为2 。
这个题不得不提一下高中学过的一个简单的数学公式:

要不是刷题,我都不记得还学过这个公式。。。

-
2. 滑动窗口 , 小优化: 两个超过target一半的数相加肯定会超过target ,所以循环条件可以由 L < R 改为 L ≤ target / 2 , 初始 L = 1,R = 2, sum = 3 ,
-
① 当 sum==target 时,输出 [L..R] 范围内的数到结果中,然后同时向右移动 L++ 和 R++ ,更新 sum = sum - L + R,
-
② 当 sum < target 时, 向右移动 R++ ,同时 更新 sum = sum + R,
-
③ 当 sum > target 时,向右移动 L++ ,同时 更新 sum = sum - L (在移动之前减)。

这个写法给出了计算连续数字区间和的另一种方式,即先初始化一个 sum 值,然后每当移出一个左边界的数时(L++),从 sum 中减去 L, 每当扩充一个右边界时(R++),从 sum 中加上 R。
845. 数组中的最长山脉

-
滑动窗口</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











