







 LeetCode刷题笔记之前缀树篇。
LeetCode刷题笔记之前缀树篇。
208. 实现 Trie (前缀树)

解题思路:
-
1. 前缀树 Map实现 ,使用一个 Map<Character, Trie> 来存储 每个字符 对应的 若干子节点 ,在构造函数中初始化 根节点 root 为 当前对象实例 ,
-
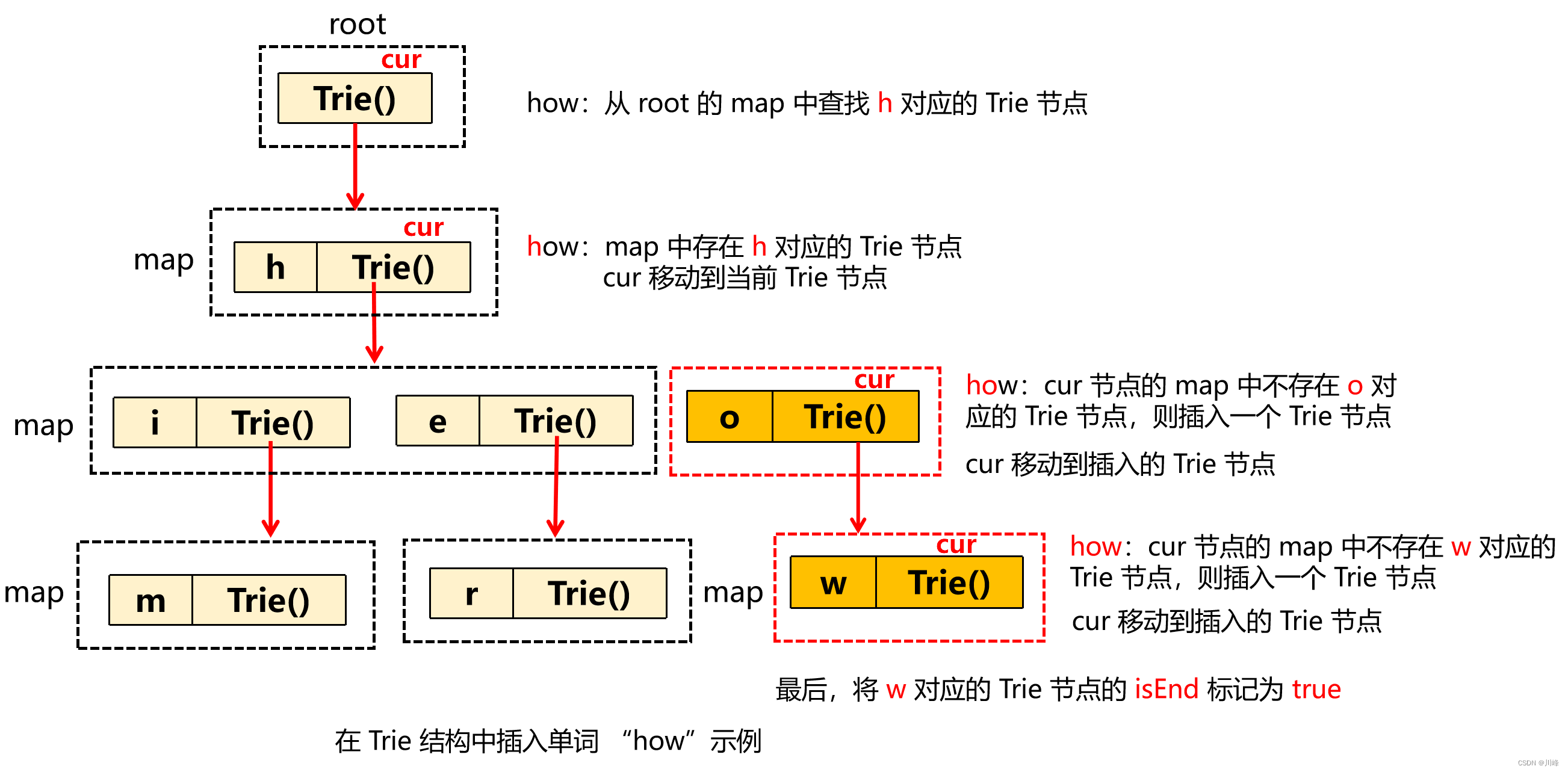
在 插入 单词字符串时,当前节点 cur 从根节点 root 开始搜索,遍历单词的 每一个字符 ,从 cur 存放子节点的 map 中取出该字符对应的节点,如果当前字符在 map 中不存在,就先创建一个子节点放入 map 中,然后再让 cur 节点移动到取出的对应子节点上。 循环遍历完单词的所有字符后,将 cur 节点,也就是最后一个节点的结尾标识符设为 true 。
-
在 查找 字符串时,同样让当前节点 cur 从 root 开始搜索,遍历要查找字符串的每个字符,如果该字符在 map 中不存在,就返回 null , 说明不存在该前缀字符串,如果 map 中存在,就让 cur 移动到该子节点,遍历完所有字符后,判断最后一个节点的结尾标识符是不是 true , 就可以知道要搜索的单词是否存在。
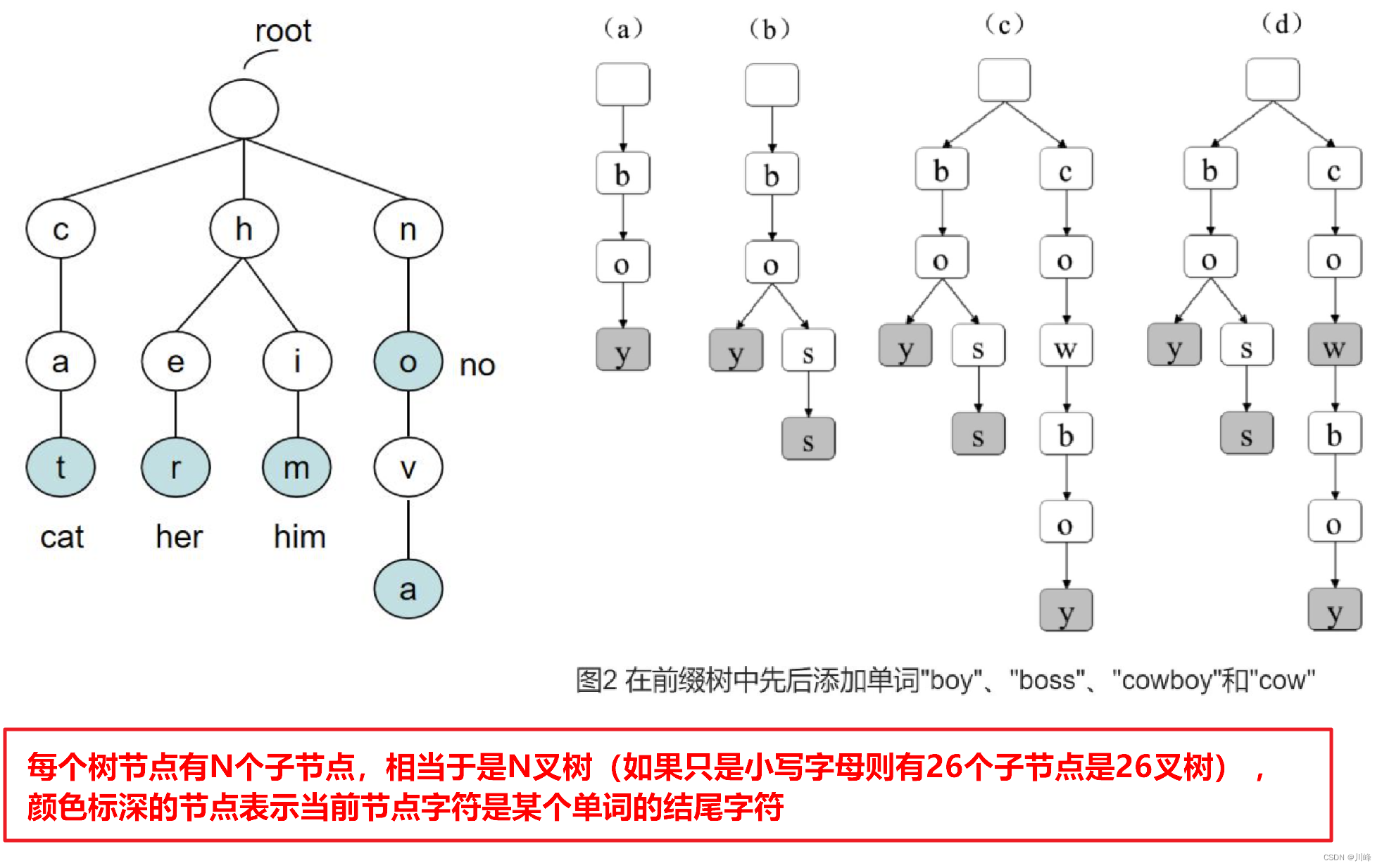

每个 Trie 实例持有一个 Map,Map 中存储了属于该实例的所有子节点(字符)对应的 Trie 节点,而这些 Trie 子节点又会持有 Map 来存储其子节点,因此形成一个嵌套的树形结构,可参考下图理解:
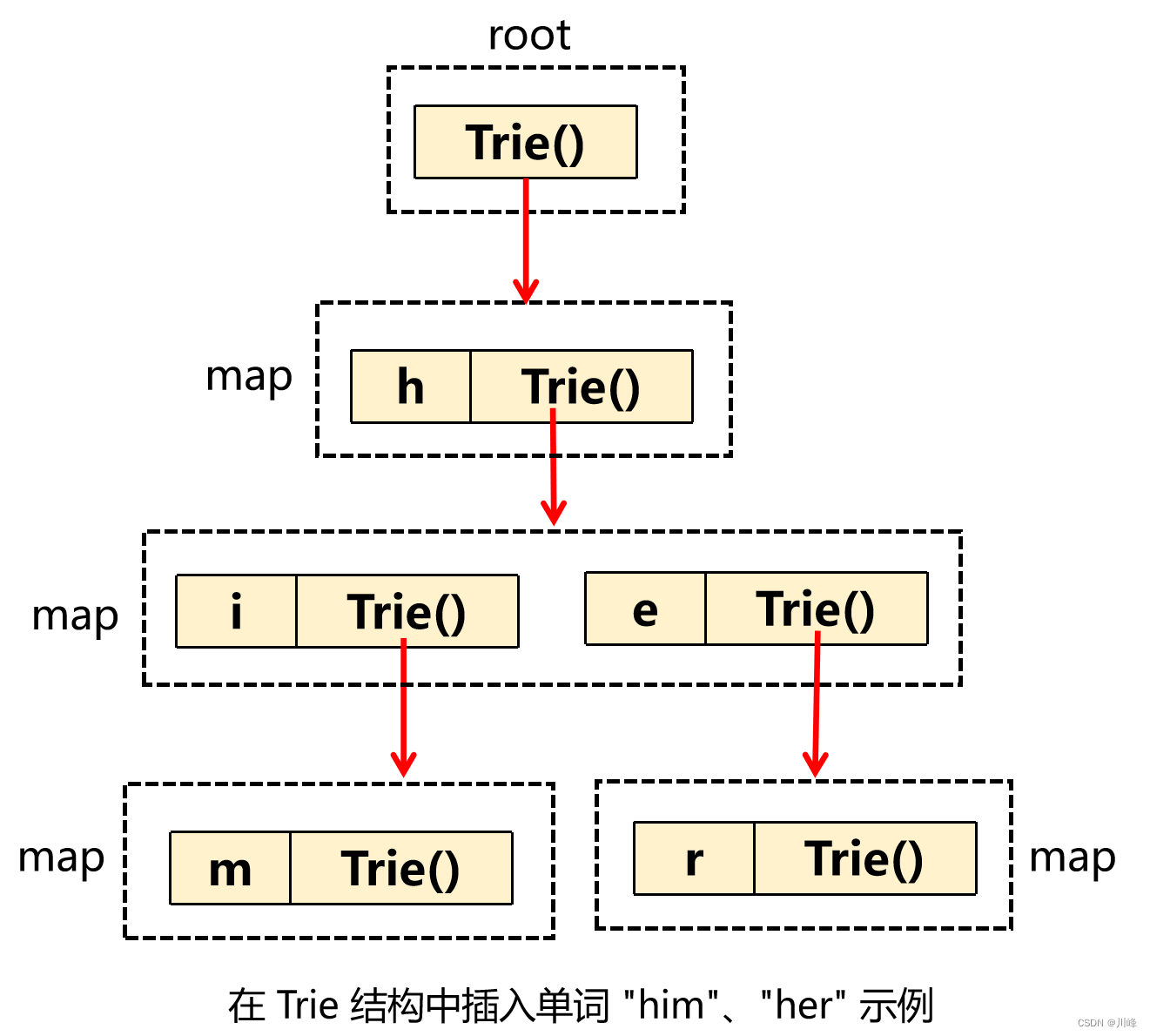
解题思路:
-
2. 前缀树 数组实现 ,由于题目单词只包含 小写字母 ,因此可以使用一个长度 26 的 数组 代替方法1中的 map ,代码逻辑与方法1相同。

212. 单词搜索 II

解题思路:
-
1. DFS + 前缀树 ,首先创建前缀树的 根节点 ,参考208将所有单词加入前缀树中,方便后面查找,然后从二维矩阵的每一个格子开始进行一次 DFS 搜索,
-
每次递归中,查找当前坐标对应的字符在当前字典树节点的 children 中是否存在,如果不存在就返回,如果存在就取出字典树中对应的 child 节点,
-
如果该 child 节点结尾标识符是 true ,说明该节点是单词的结尾,收集该节点上存储的单词作为答案保存到结果集中。
-
如果该 child 节点不是单词的结尾,就将当前坐标处的字符置为 "#" 表示 已访问 ,然后看当前坐标的 四个邻居 ,如果邻居 未越界 且 未访问 ,则对邻居进行 DFS ,将当前 child 节点作为下一层的 根节点 向下传递。
-
在访问完四个邻居之后,要做 回溯 处理,将之前置为 "#" 的字符再 改回去 ,因为从其他起点 DFS 搜索路径时,可能使用到该格子。
-
注意点:在保存答案的使用 Set 去重 ,因为同一个单词可能在多个不同的搜索路径中出现。


需要特别注意:在上面代码中,往四个邻居方向进行DFS时,Trie节点必须传递当前遍历到的
child
节点,否则可能漏掉答案,比如下图所示,如果搜索到cow后,继续往邻居节点搜索时,传的还是root节点,那么就会错过
boy
这个答案,因为 root 的第一层子节点中不包含
b
节点,它在
w
节点的下面。这是因为前缀树中每个标记为
isEnd=true
的节点不一定就是叶子节点,其下面还可能继续挂别的节点。
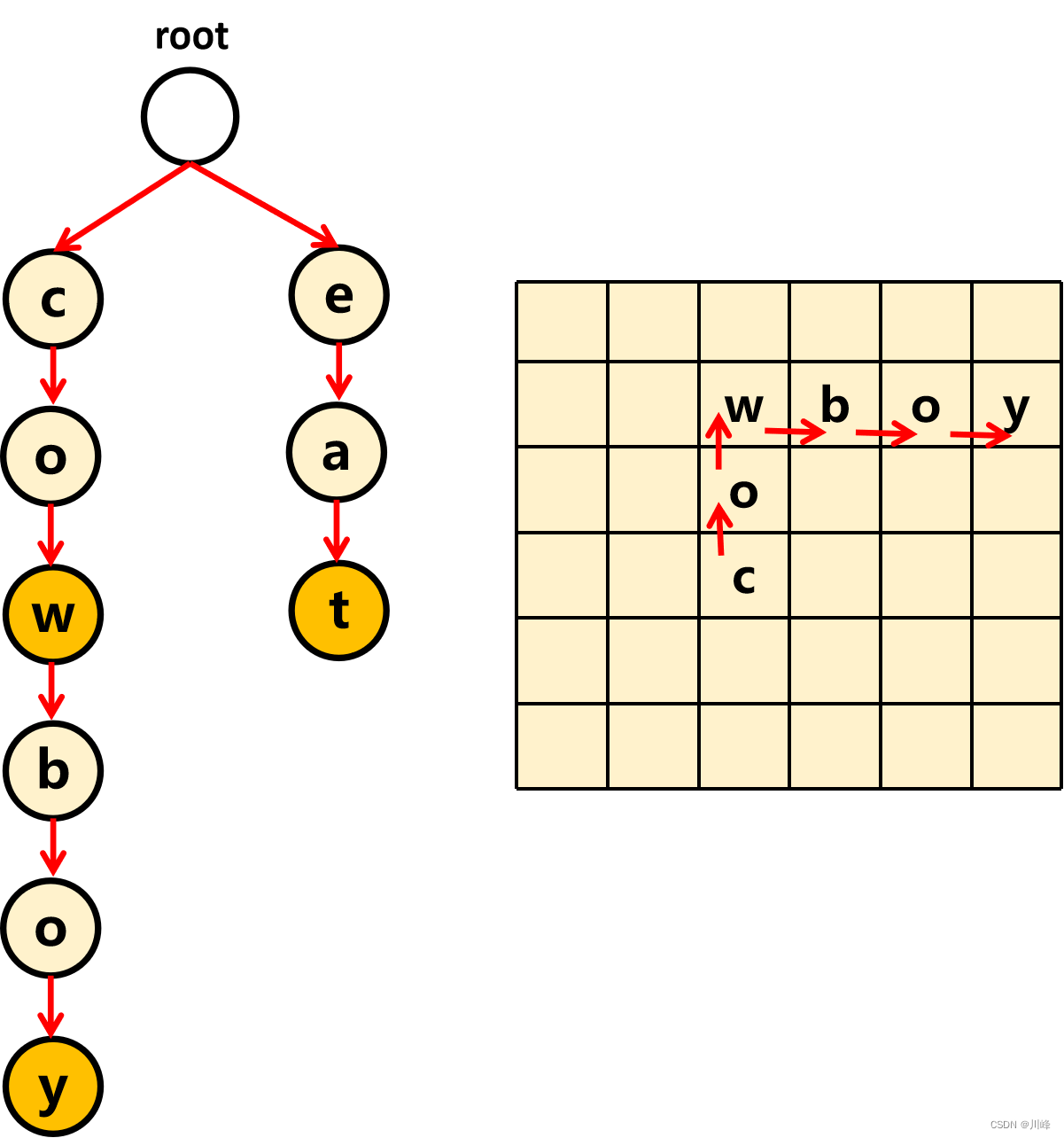
其实在递归过程中,不断传递 child 节点作为下一层递归根节点的过程,就是相当于在 208 题中遍历前缀树查找单词时,移动 cur 到其 map 中对应子节点的过程,只不过这个题是将 “移动 cur” 的操作放在了传递递归调用的参数上面。
解题思路:
-
2. DFS + 前缀树 优化 ,考虑以下情况
-
假设二维网格所有单元格都是 a ,单词列表是 ["a", "aa", "aaa", "aaaa"] 。当我们找出所有同时在二维网格和单词列表中出现的单词时,我们需要遍历每一个单元格的所有路径,会找到大量重复的单词。
-
为了缓解这种情况,我们可以 将匹配到的单词从前缀树中移除 ,来 避免重复寻找相同的单词 。因为这种方法可以保证 每个单词只能被匹配一次 ;所以我们也不需要再对结果集 去重 了。
-
具体地,在 DFS 中收集答案后,将对应节点的 isEnd 标记为 false , 表示删除,在访问邻居四个坐标之前,判断当前 child 节点的 子节点是否为空 ,如果为空,说明是 叶子节点 ,不用继续 DFS 了,从 root 中 移除 该节点
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1171
1171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











