










返回:SQLite—系列文章目录
上一篇:SQLite 查询优化器概述(九)
下一篇:SQLite的架构(十一)

1. 引言
“查询规划器”的任务是弄清楚 找出完成 SQL 语句的最佳算法或“查询计划”。 从 SQLite 版本 3.8.0 (2013-08-26) 开始, 查询规划器组件已 重写,使其运行得更快并生成更好的计划。这 重写被称为“下一代查询规划器”或“NGQP”。
本文概述了查询规划的重要性,介绍了一些 查询规划固有的问题,并概述了 NGQP 如何 解决了这些问题。
NGQP 几乎总是比传统的查询规划器更好。 但是,可能存在遗留应用程序,这些应用程序在不知不觉中依赖于 旧查询规划器中的未定义和/或次优行为,以及 在这些遗留应用程序上升级到 NGQP 可能会降低性能 回归。考虑了这种风险,并提供了一份清单 用于降低风险并解决出现的任何问题。
本文档重点介绍 NGQP。有关 包含 SQLite 整个历史记录的 SQLite 查询规划器,请参阅 “SQLite 查询优化器概述”和 “索引的工作原理”文档。
2. 背景
对于针对索引很少的单个表的简单查询,通常有 最佳算法的明显选择。 但对于更大、更复杂的查询,例如 具有多个索引的多路联接 而子查询,可以有数百个、数千个或数百万个 用于计算结果的合理算法。 查询规划器的工作是从中选择单个“最佳”查询计划 这种可能性多种多样。
查询计划器使 SQL 数据库引擎如此有用和强大。 (所有 SQL 数据库引擎都是如此,而不仅仅是 SQLite。 查询规划器将程序员从选择的苦差事中解放出来 一个特定的查询计划,从而允许程序员 将更多的精力集中在更高层次的应用问题上,并专注于 为最终用户提供更多价值。对于简单的查询,选择 的查询计划是显而易见的,这很方便,但不是很重要。 但是,随着应用程序、架构和查询变得越来越复杂, 聪明的查询规划器可以大大加快和简化应用程序的工作 发展。 即将讲述有惊人的力量 数据库引擎需要什么内容,然后让数据库 引擎找出检索该内容的最佳方法。
编写一个好的查询规划器与其说是科学,不如说是一门艺术。 查询计划器必须处理不完整的信息。 它无法确定任何特定计划需要多长时间 没有实际运行该计划。所以在比较两个时 或者更多的计划来弄清楚哪个是“最好的”,查询计划者必须做出 一些猜测和假设,这些猜测和假设会 有时是错的。一个好的查询计划器是一个可以 经常找到正确的解决方案,使应用程序足够多 程序员很少需要参与其中。
2.1. SQLite中的查询规划
SQLite 使用嵌套循环计算联接, 每个表一个循环 在联接中。(可能会为 IN 插入其他循环 和 WHERE 子句中的 OR 运算符。SQLite也考虑了这些, 但为了简单起见,我们将在本文中忽略它们。 可以在每个循环上使用一个或多个索引来加快搜索速度, 或者循环可能是“全表扫描”,读取 桌子。因此,查询计划分解为两个子任务:
- 选择各种循环的嵌套顺序
- 为每个循环选择好的索引
选择嵌套顺序通常是更具挑战性的问题。 一旦建立了连接的嵌套顺序,索引的选择 对于每个循环通常是显而易见的。
2.2. SQLite Query Planner稳定性保证
启用查询规划器稳定性保证 (QPSG) 时 SQLite将始终为任何查询选择相同的查询计划 给定 SQL 语句,只要:
- 数据库架构不会发生重大变化,例如 添加或删除索引,
- 不重新运行 ANALYZE 命令,
- 使用相同版本的 SQLite。
默认情况下,QPSG 处于禁用状态。它可以在编译时启用 使用 SQLITE_ENABLE_QPSG 编译时选项,或在运行时通过 调用 sqlite3_db_config(db,SQLITE_DBCONFIG_ENABLE_QPSG,1,0)。
QPSG 意味着,如果所有查询都能高效运行 在测试期间,如果应用程序未更改架构, 那么 SQLite 不会突然决定开始使用不同的 查询计划,可能会导致应用程序后出现性能问题 已发布给用户。如果您的应用程序在实验室中工作,则 部署后将继续以相同的方式工作。
企业级客户端/服务器 SQL 数据库引擎通常不 做出此保证。 在客户端/服务器 SQL 数据库引擎中,服务器跟踪 关于表格大小和索引质量的统计 查询计划器使用这些统计信息来帮助选择最佳计划。 在数据库中添加、删除或更改内容时,统计信息 将不断发展,并可能导致查询计划器开始使用不同的 某些特定查询的查询计划。通常新计划会更好 用于不断发展的数据结构。但有时新的查询计划会 导致性能下降。使用客户端/服务器数据库引擎,有 通常是数据库管理员 (DBA) 来处理这些问题 出现罕见的问题。但是 DBA 无法解决问题 在像 SQLite 这样的嵌入式数据库中,因此 SQLite 会小心翼翼地 确保计划在部署后不会意外更改。
需要注意的是,更改 SQLite 版本可能会导致 查询计划中的更改。 相同版本的 SQLite 将 始终选择相同的查询计划,但如果重新链接应用程序以使用 使用不同版本的 SQLite,则查询计划可能会更改。在罕见的 在这种情况下,SQLite 版本更改可能会导致性能回归。 这是原因之一 您应该考虑将应用程序静态链接到 SQLite 而不是使用系统范围的 SQLite 共享库,这可能 在你不知情或无法控制的情况下改变。
3. 一个棘手的案例
“TPC-H Q8”是来自事务处理性能的测试查询 理事会。SQLite 版本 3.7.17 及更早版本中的查询规划器 不要为 TPC-H Q8 选择好的计划。并且已经确定 没有金额 对旧版查询规划器的调整将解决这个问题。为了找到 TPC-H Q8 查询的良好解决方案,并继续改进 SQLite查询规划器的质量,有必要重新设计 查询规划器。本节试图解释为什么这种重新设计是 必要以及 NGQP 的不同之处并解决了 TPC-H Q8 问题。
3.1. 查询详细信息
TPC-H Q8 是八路连接。 如上所述,查询规划器的主要任务是 找出八个循环的最佳嵌套顺序,以便最小化 完成联接所需的工作。 图中显示了TPC-H Q8问题的简化模型 如下图所示
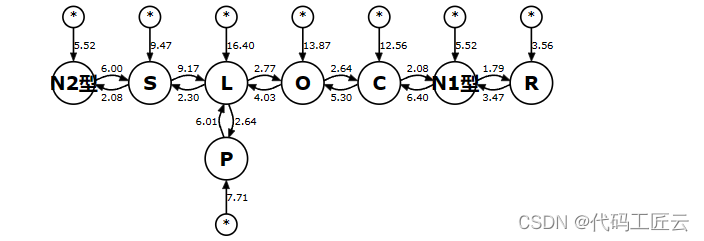
在图中,查询的 FROM 子句中的 8 个表中的每一个都是 用一个大圆圈标识,带有 FROM 子句术语的标签: N2、S、L、P、O、C、N1 和 R。 图中的圆弧表示计算每个项的估计成本 假设圆弧的原点位于外环中。例如, 将 S 循环作为 L 的内循环运行的成本为 2.30,而 将 S 环路作为 L 的外环运行的成本为 9.17。
这里的“成本”是对数的。使用嵌套循环,工作 是相乘的,而不是相加的。但人们习惯于考虑图表 使用加法权重,因此该图显示了 各种费用。该图显示了 S 在 L 约为 6.87,但这转化为运行的查询 当 S 环路位于 L 环路内而不是 置身事外。
标有“*”的小圆圈中的箭头表示成本 运行每个循环,没有依赖关系。最外层的循环必须使用这个 *-成本。内部循环可以选择使用 *-cost 或成本假设 其他项之一位于外循环中,以最佳为准 结果。可以将 *-costs 视为表示 多个弧,一个来自 图。因此,该图是“完整的”,这意味着存在弧线 (有些是明确的,有些是暗示的)在每对 图中的节点。
查找最佳查询计划的问题等同于查找 通过访问每个节点的图形的最低成本路径 正好一次。
(旁注:上图TPC-H Q8中的成本估算是计算得出的 由 SQLite 3.7.16 中的查询规划器使用自然对数进行转换。
3.2. 复杂化
上面对查询规划器问题的介绍是一种简化。 成本是估计值。我们不能 在我们实际运行循环之前,要知道运行循环的真正成本是多少。 SQLite根据以下因素对运行循环的成本进行猜测 在 WHERE 中找到的索引和约束的可用性 第。这些猜测通常很好,但有时也可以 关闭。使用 ANALYZE 命令收集其他统计信息 有关数据库的信息有时可以使SQLite变得更好 猜测成本。
成本由多个数字组成,而不是单个数字 如图所示。 SQLite 为每个循环计算几个不同的估计成本,这些成本适用于 不同的时间。例如,会产生“设置”成本 查询开始时仅一次。设置成本是计算成本 尚未建立的表的自动索引 有一个索引。然后那里 是运行循环中每个步骤的成本。最后,有一个估计 循环生成的行数,这是 估算内部循环的成本。分拣成本可能会发挥作用 如果查询具有 ORDER BY 子句。
在一般查询中,依赖项不需要位于单个循环上,因此 依赖关系矩阵可能无法表示为图形。 例如,其中一个 WHERE 子句约束可能是 S.a=L.b+P.c,这意味着 S 环必须是两者的内环 L 和 P。这种依赖关系不能绘制为图形 因为 ARC 无法起源于两个或多个节点 一次。
如果查询包含 ORDER BY 子句或 GROUP BY 子句,或者如果 查询使用 DISTINCT 关键字,则选择 通过图形的路径,使行自然地按排序顺序显示, 这样就不需要单独的排序步骤。自动消除 ORDER BY 子句 可以产生很大的性能差异,所以这是另一个因素 这需要在完整的实施中加以考虑。
在 TPC-H Q8 查询中,设置成本可以忽略不计, 所有依赖关系都在各个节点之间,没有 ORDER BY, GROUP BY 或 DISTINCT 子句。所以对于TPC-H Q8来说, 上图是需要计算的内容的合理表示。 一般情况涉及许多额外的复杂性,为了清楚起见 在本文的其余部分被忽略。
3.3. 寻找最佳查询计划
在版本 3.8.0 (2013-08-26) 之前,SQLite 始终使用 搜索最佳查询计划时的“最近邻”或“NN”启发式。 NN 启发式对图形进行单次遍历,始终选择 成本最低的电弧作为下一步。 在大多数情况下,NN 启发式方法的效果出奇地好。 而且NN速度很快,所以SQLite能够快速找到好的方案 即使是大型 64 路连接。相比之下,其他 SQL 数据库引擎 进行更广泛的搜索往往会陷入困境,当 联接中的表数超过 10 或 15。
遗憾的是,NN 为 TPC-H Q8 计算的查询计划不是最优的。 使用 NN 计算的计划是 R-N1-N2-S-C-O-L-P,成本为 36.92。 符号 在上一句中表示 R 表在外循环中运行, N1 在下一个内循环中,N2 在第三个循环中,依此类推 到位于最内层循环中的 P。通过的最短路径 图表(通过详尽搜索找到)是 P-L-O-C-N1-R-S-N2 成本为 27.38。差异可能看起来不大,但是 请记住 成本是对数的,因此最短路径接近 750 倍 比使用 NN 启发式找到的路径更快。
这个问题的一个解决方案是将SQLite更改为做一个详尽的 搜索最佳路径。但详尽的搜索需要时间 成比例 K!(其中 K 是联接中的表数),所以当你得到 超越 10 路连接,时间 运行 sqlite3_prepare() 变得非常大。
3.4. N 最近邻或“N3”启发式
NGQP 使用一种新的启发式方法来寻找通过 图:“N 最近邻”(以下简称“N3”)。使用 N3,而不是 每个步骤只选择一个最近的邻居,算法会保持 对于某个小整数 N 的每个步骤,N 的最佳路径的跟踪。
假设 N=4。然后对于 TPC-H Q8 图,第一步找到 访问图中任何单个节点的四条最短路径:
R (cost: 3.56)
N1 (cost: 5.52)
N2 (cost: 5.52)
P (cost: 7.71)
第二步找到访问两个节点的四条最短路径 从上一步的四条路径之一开始。在 两条或多条路径等效的情况(它们具有相同的一组 访问节点,尽管可能以不同的顺序)只有 保留第一条和最低成本的路径。我们有:
R-N1 (cost: 7.03)
R-N2 (cost: 9.08)
N2-N1 (cost: 11.04)
R-P {cost: 11.27}
第三步从四个最短的双节点路径开始,找到 四条最短的三节点路径:
R-N1-N2 (cost: 12.55)
R-N1-C (cost: 13.43)
R-N1-P (cost: 14.74)
R-N2-S (cost: 15.08)
等等。TPC-H Q8 查询中有 8 个节点, 所以这个过程总共重复了 8 次 次。在 K-way 连接的一般情况下,存储要求 是 O(N),计算时间为 O(K*N),明显更快 比 O(2K) 精确解。
但是 N 选择什么值呢?可以尝试 N=K。这使得 算法 O(K2) 这实际上仍然非常有效,因为 K 的最大值为 64,K 很少超过 10。 但对于TPC-H Q8来说,这还不够 问题。在 TPC-H Q8 上 N=8 时,N3 算法发现 解决方案R-N1-C-O-L-S-N2-P,成本为29.78。 这比 NN 有了很大的改进,但它仍然如此 不是最佳的。N3 为 TPC-H Q8 找到最佳解决方案 当 N 为 10 或更大时。
NGQP 的初始实现选择 N=1 进行简单查询,N=5 对于双向联接,对于具有三个或更多表的所有联接,N=10。这 选择 N 的公式可能会在后续版本中更改。
4. 升级到 NGQP 的危害
2018-11-24更新:本节很重要 当 NGQP 是新的时。但五年过去了,NGQP已经 成功部署到数十亿台设备,每个人都进行了升级。 升级危险已经消失。 保留此部分仅供历史参考。 新式读取可以跳到查询计划器清单。
对于大多数应用程序,从旧版查询规划器升级到 NGQP 几乎不需要思考或努力。 只需将较旧的 SQLite 版本替换为较新版本的 SQLite 即可 并重新编译,应用程序将运行得更快。 没有 API 更改或修改 到编译程序。
但是,与任何查询规划器更改一样,升级到 NGQP 确实会带来 引入性能回归的风险很小。这里的问题是 并不是说 NGQP 不正确或有缺陷或不如旧查询 计划。给定有关索引选择性的可靠信息, NGQP应该始终选择一个比以前更好或更好的计划。 问题是某些应用程序可能使用低质量和 低选择性指数,无需运行 ANALYZE。较旧的查询 规划人员会查看每个查询的可能实现,并且 所以他们可能因为愚蠢的运气偶然发现了一个好计划。NGQP,在 另一方面,查看更多查询计划的可能性,它可能 选择其他查询计划 理论上效果更好,假设指数良好,但性能良好 在实践中回归,因为数据的形状。
要点:
-
与 先前的查询规划者,只要它 可以访问SQLITE_STAT1文件中的准确 ANALYZE 数据。
-
NGQP总能找到一个好的查询方案 只要架构不包含大于 大约 10 或 20 行,在最左边的列中具有相同的值 指数。
并非所有应用程序都满足这些条件。幸运 即使没有这些条件,NGQP 通常仍然会找到好的查询计划。 但是,确实会出现(很少)可能发生性能回归的情况。
4.1. 案例研究:将 Fossil 升级到 NGQP
Fossil DVCS 是该版本 用于跟踪所有SQLite源代码的控制系统。 Fossil 存储库是一个 SQLite 数据库文件。 (请读者将这种递归作为一个独立的练习来思考。 Fossil 既是 SQLite 的版本控制系统,也是测试 SQLite的平台。每当对 SQLite 进行增强时, Fossil 是最早测试和评估这些应用程序的应用程序之一 增强。因此,Fossil 是 NGQP 的早期采用者。
不幸的是,NGQP 导致了 Fossil 中的性能回归。
Fossil 提供的众多报告之一是 对单个分支的更改显示该分支的所有合并。请参阅 SQLite: Timeline 了解典型的 此类报告的示例。生成这样的报告通常只需要 几毫秒。但是在升级到 NGQP 后,我们注意到 这一份报告需要将近 10 秒的时间才能完成 存储 库。
用于生成分支时间线的核心查询如下所示。 (读者不应了解此查询的详细信息。 评论将随之而来。
SELECT
blob.rid AS blobRid,
uuid AS uuid,
datetime(event.mtime,'localtime') AS timestamp,
coalesce(ecomment, comment) AS comment,
coalesce(euser, user) AS user,
blob.rid IN leaf AS leaf,
bgcolor AS bgColor,
event.type AS eventType,
(SELECT group_concat(substr(tagname,5), ', ')
FROM tag, tagxref
WHERE tagname GLOB 'sym-*'
AND tag.tagid=tagxref.tagid
AND tagxref.rid=blob.rid
AND tagxref.tagtype>0) AS tags,
tagid AS tagid,
brief AS brief,
event.mtime AS mtime
FROM event CROSS JOIN blob
WHERE blob.rid=event.objid
AND (EXISTS(SELECT 1 FROM tagxref
WHERE tagid=11 AND tagtype>0 AND rid=blob.rid)
OR EXISTS(SELECT 1 FROM plink JOIN tagxref ON rid=cid
WHERE tagid=11 AND tagtype>0 AND pid=blob.rid)
OR EXISTS(SELECT 1 FROM plink JOIN tagxref ON rid=pid
WHERE tagid=11 AND tagtype>0 AND cid=blob.rid))
ORDER BY event.mtime DESC
LIMIT 200;此查询不是 特别复杂,但即便如此,它还是取代了数百或 也许是数千行程序代码。 查询的要点是这样的:向下扫描 EVENT 表,查看 对于满足以下三个条件之一的最近 200 次签到:
- 签到有一个“trunk”标签。
- 签到时有一个带有“trunk”标签的子项。
- 签入具有具有“trunk”标记的父级。
第一个条件将导致显示所有中继签入,并且 第二个和第三个导致签入合并或分叉 行李箱也包括在内。 这三个条件由三个 OR 连接实现 查询的 WHERE 子句中的 EXISTS 语句。 NGQP 发生的减速是由第二个和 第三个条件。每个问题都是一样的,所以我们要检查一下 只是第二个。 第二个条件的子查询可以重写(带有 minor 和无形的简化)如下:
SELECT 1
FROM plink JOIN tagxref ON tagxref.rid=plink.cid
WHERE tagxref.tagid=$trunk
AND plink.pid=$ckid;PLINK 表保存 办理登机手续。TAGXREF 表将标记映射到签入中。 作为参考,架构的相关部分 对于这两个表,如下所示:
CREATE TABLE plink(
pid INTEGER REFERENCES blob,
cid INTEGER REFERENCES blob
);
CREATE UNIQUE INDEX plink_i1 ON plink(pid,cid);
CREATE TABLE tagxref(
tagid INTEGER REFERENCES tag,
mtime TIMESTAMP,
rid INTEGER REFERENCE blob,
UNIQUE(rid, tagid)
);
CREATE INDEX tagxref_i1 ON tagxref(tagid, mtime);只有两种合理的方法可以实现此查询。 (还有许多其他可能的算法,但没有一个 其他人则是“最佳”算法的竞争者。
-
找到所有的孩子 check-in $ckid 并测试每个孩子是否 它有 $trunk 标签。
-
查找所有带有 $trunk 标签的签到,并测试每个签到,看看是否 它是$ckid的孩子。
凭直觉,我们人类明白算法 1 是最好的。 每次入住时都可能有几个孩子(一个孩子是 最常见的情况),每个孩子都可以接受 $trunk 个对数时间标记。事实上,算法 1 是 在实践中更快地选择。但NGQP没有直觉。这 NGQP 必须使用硬数学,而算法 2 略有 在数学上更好。这是因为,在没有其他信息的情况下, NGQP 必须假定索引 PLINK_I1 和 TAGXREF_I1 为 同等质量,同等选择性。算法 2 使用一个字段 TAGXREF_I1索引和PLINK_I1索引的两个字段,而 algorithm-1 仅使用每个索引的第一个字段。因为 算法 2 使用较多的索引材料,NGQP 正确 判断它是更好的算法。比分很接近,而且 算法 2 在算法 1 之前几乎没有吱吱作响。但 Algorithm-2 确实是正确的选择。
不幸的是,算法 2 比算法 1 慢 此应用程序。
问题在于索引的质量不相等。 办理入住手续可能只有一个孩子。所以第一个 PLINK_I1字段通常会将搜索范围缩小到只有一个 排。但是有成千上万的签到标有“trunk”, 因此,TAGXREF_I1的第一个领域将是 对缩小搜索范围几乎没有帮助。
NGQP无法知道TAGXREF_I1在这方面几乎毫无用处 查询,除非已在数据库上运行 ANALYZE。ANALYZE 命令 收集有关各种索引质量的统计数据并存储这些统计数据 表SQLITE_STAT1统计信息。 能够访问这些统计信息, NGQP 很容易选择算法 1 作为最佳算法,通过广泛的 边缘。
为什么旧版查询规划器不选择算法 2? 简单:因为 NN 算法 甚至从未考虑过算法 2。规划图 问题如下所示:
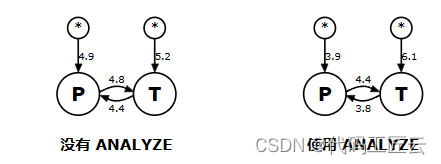
在左侧的“without ANALYZE”情况下,NN 算法选择 环路 P (PLINK) 作为外环路,因为 4.9 小于 5.2,导致 在路径 P-T 中,即算法 1。NN 只看单一的最佳选择 在每一步中,它完全忽略了这样一个事实 5.2+4.4 比 4.9+4.8 稍微便宜一些。但是 N3 算法 跟踪 2 向联接的 5 条最佳路径,因此它最终会 选择路径 T-P 是因为它的总成本略低。 路径 T-P 是算法 2。
请注意,使用 ANALYZE 时,成本估算为 更符合现实和算法 1 的是 由 NN 和 N3 选择。
(旁注:最近两张图中的成本估算 由 NGQP 使用以 2 为基数的对数计算,略有不同 与旧版查询计划器相比的成本假设。 因此,成本估算 后两张图不能直接与成本估算进行比较 在 TPC-H Q8 图中。
4.2. 解决问题
在存储库数据库上运行 ANALYZE 立即修复了 性能问题。但是,我们希望 Fossil 能够保持强大并始终 无论其存储库是否经过分析,都可以快速工作。 因此,查询已修改为使用 CROSS JOIN 运算符 而不是普通的 JOIN 运算符。 SQLite 不会对 CROSS JOIN 的表重新排序。 这是专门设计的SQLite的长期功能 允许知识渊博的程序员 强制执行特定的循环嵌套顺序。一旦加入 更改为 CROSS JOIN(添加单个关键字),NGQP 是 被迫选择更快的算法-1,无论是否 统计信息是使用ANALYZE收集的。
我们说算法 1 “更快”,但是这个 严格来说并非正确。算法 1 在常见存储库中速度更快,但 可以构建一个存储库,其中 每次签到都在不同的唯一名称的分支上,并且 所有签入都是根签入的子项。 在这种情况下,TAGXREF_I1将变得更加有选择性 比PLINK_I1和算法 2 确实是更快的选择。 但是,此类存储库不太可能出现在 练习,然后使用 CROSS JOIN 语法是一个合理的解决方案 在这种情况下,问题。
4.3. 2017 更新:更好的修复
之前的文本写于 2013 年初,在 SQLite 版本 3.8.0。这一段是在 2021 年年中添加的。 虽然之前的所有讨论仍然是正确的,但有很多改进 已对查询计划器进行处理,使整个部分在很大程度上没有实际意义。
2017 年,Fossil 进行了增强,以使用新的 PRAGMA 优化语句。每当 Fossil 即将关闭 数据库连接到其存储库,它首先运行 “PRAGMA optimize”,这反过来将导致 ANALYZE 运行,如果它 是需要的。通常不需要 ANALYZE,因此没有 这样做会造成可衡量的性能损失。但时不时地 然后 ANALYZE 可能会在存储库中的几个表上运行 数据库。因为如果这样,查询诸如 这里描述的不再出现在化石中。事实上,ANALYZE 定期运行,使sqlite_stat1表保持最新均值 不再需要手动调整查询。我们没有 以年龄为单位调整 Fossil 中的查询。
因此,目前建议避免诸如此类的问题 因为这个只是简单地运行“PRAGMA optimize”(可能之前有 “PRAGMA analysis_limit=200”),就在关闭每个数据库之前 连接。CROSS JOIN hack 仍然可用,但如果您保留 查询规划器在sqlite_stat1表中的统计信息是最新的, 通常没有必要。
5. 避免或修复查询规划器问题的清单
-
不要惊慌!查询规划器选择劣质计划的情况实际上相当 罕见。您不太可能在应用程序中遇到任何问题。 如果您没有遇到性能问题,则无需担心 关于任何一个。
-
创建适当的索引。大多数 SQL 性能问题不是由于查询规划器问题而产生的 而是由于缺乏适当的索引。确保索引是 可用于协助所有大型查询。大多数性能问题可能是 由一个或两个 CREATE INDEX 命令解决,并且不对 应用程序代码。
-
避免创建低质量的索引。 低质量指数(就本清单而言)是指以下情况 表中有 10 或 20 个以上的行具有相同的值 表示索引的最左边列。特别是,避免使用 布尔值或“枚举”列作为索引的最左侧列。
上一节中描述的 Fossil 性能问题 这份文件之所以出现,是因为有 TAGXREF 表中的一万个条目,其值相同 TAGXREF_I1索引的最左边列(TAGID 列)。
-
如果必须使用低质量索引,请务必运行 ANALYZE。低质量的索引不会混淆查询规划器,只要 查询规划器知道索引质量较低。和方式 查询规划器通过SQLITE_STAT1表的内容知道这是 由 ANALYZE 命令计算。
当然,ANALYZE 只有在您有重要的 首先是数据库中的内容量。创建 你期望积累大量数据的新数据库,你可以运行 命令“ANALYZE sqlite_schema”创建SQLITE_STAT1表, 然后预填充 sqlite_stat1 表(使用普通的 INSERT 语句) 内容描述典型的 应用程序的数据库 - 可能是您在之后提取的内容 在实验室中填充良好的模板数据库上运行 ANALYZE。 或者,您可以在关闭之前运行“PRAGMA optimize” 数据库连接,以便 ANALYZE 将自动运行为 需要使sqlite_stat1表保持最新状态。
-
检测代码。添加逻辑,让您快速轻松地了解正在执行哪些查询 时间太多了。然后只处理这些特定的查询。
-
使用 unlikely() 和 likelihood() SQL 函数。SQLite 通常假定 WHERE 子句中的术语不能使用 按索引很有可能是真的。如果这个假设 不正确,则可能导致查询计划欠佳。unlikely() 和 likelihood() SQL 函数可用于提供 向查询规划器提示有关 WHERE 子句术语的提示,这些术语可能是 不是真的,因此帮助查询规划器选择最佳可能 计划。
-
使用 CROSS JOIN 语法强制执行特定的 在 未分析的数据库。SQLite 专门处理 CROSS JOIN 运算符,强制表 左边是相对于右边表格的外环。
如果可能的话,请避免这一步,因为它破坏了一个巨大的优势 整个SQL语言概念,特别是应用程序 程序员不需要参与查询规划。如果你 请使用 CROSS JOIN,等到开发周期的后期再这样做, 并仔细注释 CROSS JOIN 的使用,以便将其取出 如果可能的话,以后再说。避免在开发早期使用 CROSS JOIN 这样做的周期是一种不成熟的优化,这是众所周知的 成为 万恶百恶。
-
使用一元“+”运算符取消 WHERE 子句术语的资格。如果查询规划器坚持为特定索引选择质量较差的索引 当有更高质量的索引可用时进行查询,然后在 WHERE 子句中谨慎使用一元“+”运算符 可以强制查询计划器远离质量较差的索引。 如果可能的话,避免使用这个技巧,尤其是避免它 在应用程序开发周期的早期。当心 将一元“+”运算符添加到相等表达式可能会更改 如果涉及类型相关性,则该表达式的结果。
-
使用 INDEXED BY 语法强制选择 问题查询的特定索引。与前两个项目符号一样,如果可能,请避免此步骤,并且 尤其要避免在开发早期这样做,因为它显然是一个 过早优化。
6. 总结
SQLite中的查询规划器通常可以出色地选择 用于运行 SQL 语句的快速算法。这 传统的查询规划器,新的 NGQP 更是如此。可能有 偶尔出现的情况,由于信息不完整,查询 计划员选择次优计划。这种情况在 NGQP 比使用旧版查询规划器,但它仍然可能发生。只 在这些极少数情况下,应用程序开发人员需要参与其中,并且 帮助查询规划器做正确的事情。在常见情况下, NGQP 只是 SQLite 的一项新增强功能,它使应用程序运行 速度快一点,不需要新的开发人员思考或行动。















 3318
3318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











