









Spark运行模式
本地运行模式 (单机)
该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,通常用来验证开发出来的应用程序逻辑上有没有问题。
运行该模式非常简单,只需要把Spark的安装包解压后,改一些常用的配置即可使用,而不用启动Spark的Master、Worker守护进程( 只有集群的Standalone方式时,才需要这两个角色),也不用启动Hadoop的各服务(除非你要用到HDFS),这是和其他模式的区别哦,要记住才能理解。
spark-submit 和 spark-submit --master local 效果是一样的
单机模拟集群,这种运行模式和Local[N]很像,不同的是,它会在单机启动多个进程来模拟集群下的分布式场景,而不像Local[N]这种多个线程只能在一个进程下委屈求全的共享资源。通常也是用来验证开发出来的应用程序逻辑上有没有问题,或者想使用Spark的计算框架而没有太多资源。
用法是:提交应用程序时使用local-cluster[x,y,z]参数:x代表要生成的executor数,y和z分别代表每个executor所拥有的core和memory数。
spark-submit --master local-cluster[2, 3, 1024]
(同理:spark-shell --master local-cluster[2, 3, 1024]用法也是一样的
Spark自带Cluster Manager的Standalone Client模式(集群)
启动方式
master sbin/start-master.sh -h master-hostname
slave sbin/start-slave.sh spark:master-hostname:端口
执行命令
spark-submit --master spark://hadoop1:7077
和单机运行的模式不同,这里必须在执行应用程序前,先启动Spark的Master和Worker守护进程。
代表着会在所有有Worker进程的节点上启动Executor来执行应用程序,此时产生的JVM进程如下:(非master节点,除了没有Master、SparkSubmit,其他进程都一样)
基于YARN的Resource Manager的Client模式(集群)
现在大部分环境都是Spark跑在Hadoop集群中,所以为了做到资源能够均衡调度,会使用YARN来做为Spark的Cluster Manager,来为Spark的应用程序分配资源。
在执行Spark应用程序前,要启动Hadoop的各种服务。由于已经有了资源管理器,所以不需要启动Spark的Master、Worker守护进程。可已理解为使用了hadoop的yarn来管理Spark的工作节点
执行命令spark-submit --master yarn
IDEA开发环境
IDEA安装scala插件
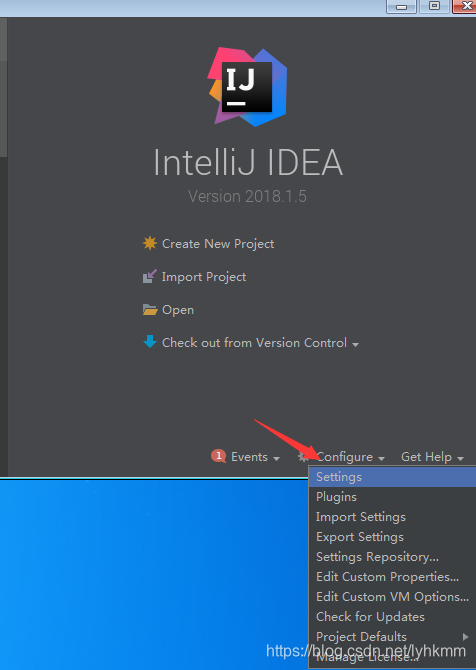
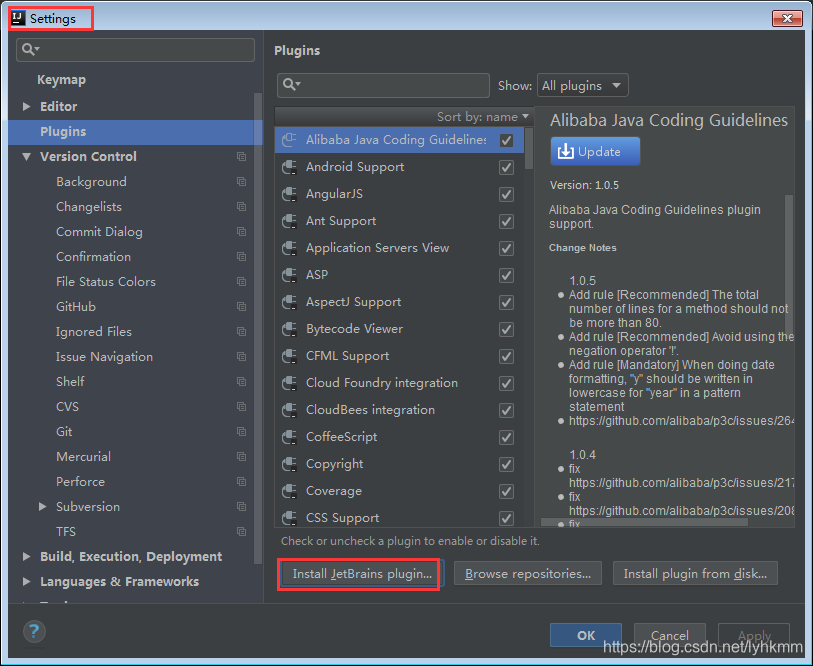

下载sacla2.11.12,msi安装包会自动配置环境变量 https://www.scala-lang.org/download/all.html

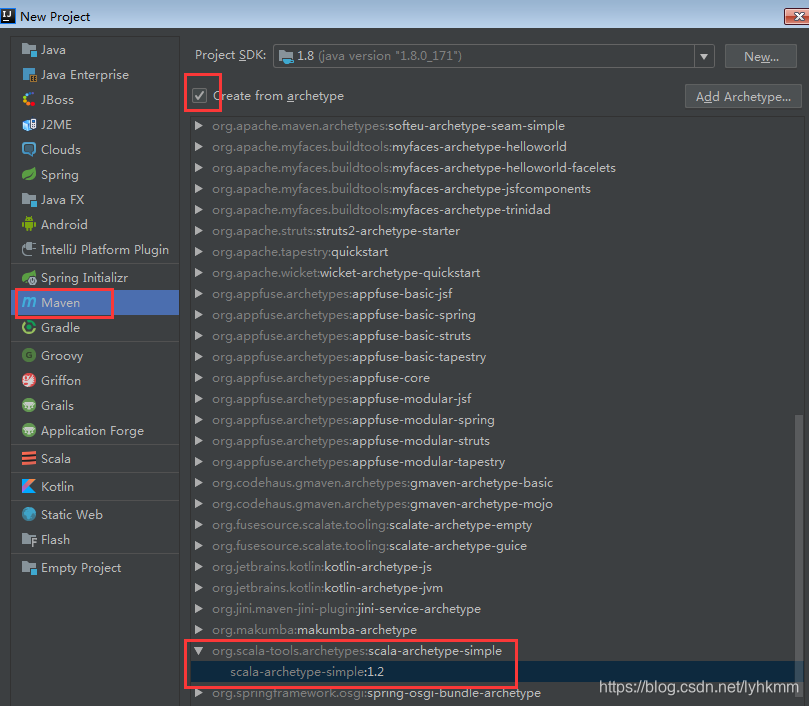
创建项目,这里因为习惯使用maven的方式,也可以使用SBT。
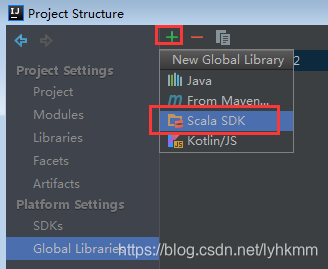
添加Scala SDK
因为IDEA的maven方式会自动设置scala的版本,需要修改pom.xml对应的scala版本和添加Spark依赖包
<properties>
<scala.version>2.11.2</scala.version>
</properties>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.0</version>
</dependency>
创建SparkDemo对象
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object SparkDemo {
def main(args: Array[String]) {
//待处理的文件
// 创建目录 hadoop fs -mkdir -p spark_demo/input/ hadoop fs -mkdir -p spark_demo/input/
// 上传linux本地文件到hdfs
val testFile = "hdfs://hadoop1:9000/spark_demo/input/words.txt"
val conf = new SparkConf().setAppName("SparkDemo Application")
.setMaster("local")
//远程调试spark standalone集群
//.setJars(List("E:\\OneDrive\\study\\spark\\out\\artifacts\\spark_jar\\spark.jar")).setMaster("spark://hadoop1:7077")
val sc = new SparkContext(conf)
val rdd = sc.textFile(testFile)
//处理之后文件路径
val wordcount = rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).map(x => (x._2,x._1)).sortByKey(false).map(x => (x._2,x._1))
wordcount.saveAsTextFile( "hdfs://hadoop1:9000/spark_demo/out/"+System.currentTimeMillis())
sc.stop()
}
}
上传待处理的文档到hdfs。
[hadoop@hadoop1 ~]$ vi /home/hadoop/words.txt
随便输入几个单词保存退出。
[hadoop@hadoop1 ~]$ hadoop fs -put /home/hadoop/words.txt /spark_demo/input/
代码完成之后,右键选择run “SparkApp”,运行程序进行功能测试。
如遇到程序报错java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries,这是因为windows环境变量不兼容的原因。
解决办法:
下载winutils地址https://github.com/srccodes/hadoop-common-2.2.0-bin下载解压
复制winutils.exe winutils.pdb到之前配置好的hadoop/bin目录下
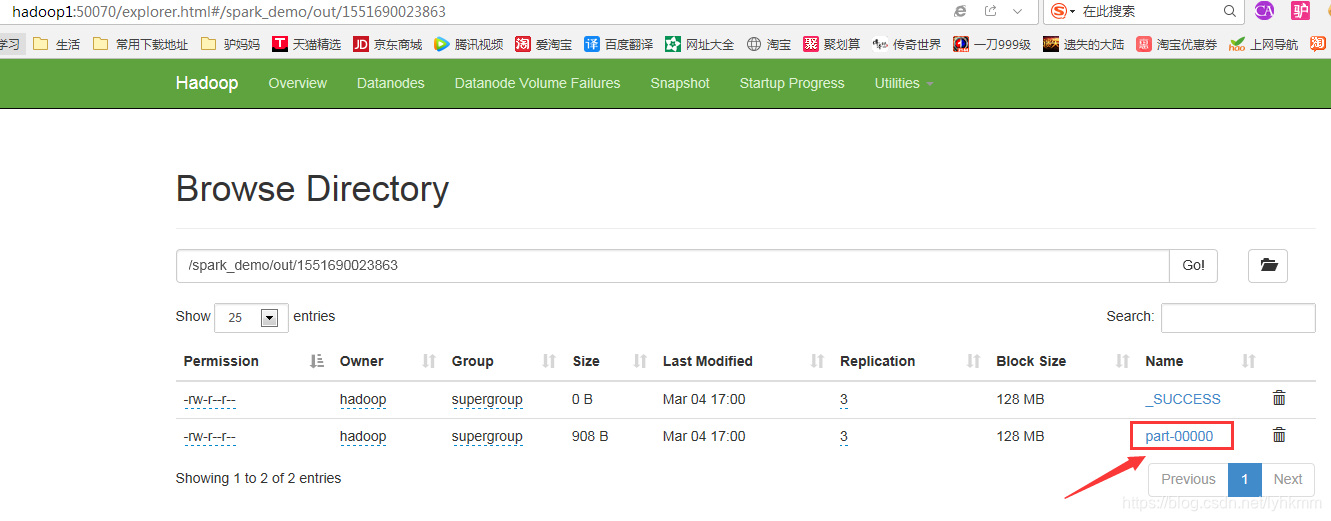
目录 http://hadoop1:50070/explorer.html 查看输出结果
用spark-submit方式
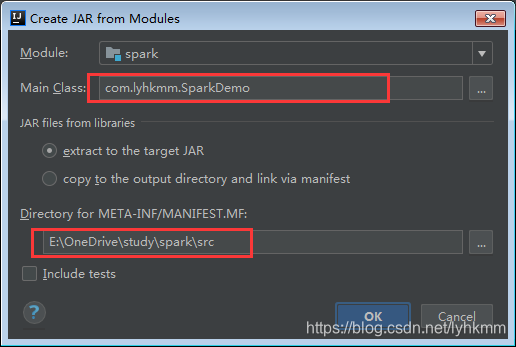
打包SparkApp程序:File—>preject structure —>from modules with dependencies:

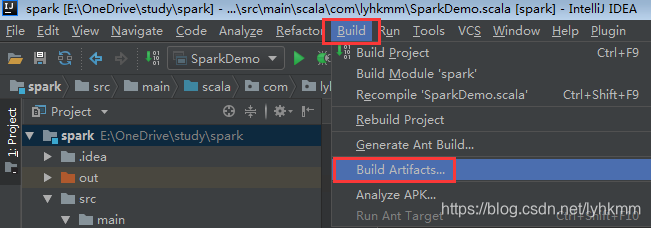
可以看到spark.jar编译打包在项目out文件,然后上传spark.jar到/home/hadoop/下,用spark-submit方式测试jar包:
[hadoop@hadoop1 ~]$ cd /app/hadoop/spark-2.4.0-bin-hadoop2.7/
[hadoop@hadoop1 spark-2.4.0-bin-hadoop2.7]$ bin/spark-submit --master yarn --deploy-mode client /home/hadoop/spark.jar
远程调试spark standalone集群
启动spark standalone集群模式
[hadoop@hadoop1 spark-2.4.0-bin-hadoop2.7]$ cd sbin/./start-all.sh
[hadoop@hadoop1 sbin]$ ./start-all.sh
将SparkDemo中的
val conf = new SparkConf().setAppName("SparkDemo Application")
.setMaster("local")
改成
val conf = new SparkConf().setAppName("SparkDemo Application")
.setJars(List("E:\\OneDrive\\study\\spark\\out\\artifacts\\spark_jar\\spark.jar")).setMaster("spark://hadoop1:7077")
Github地址:https://github.com/lyhkmm/spark-demo















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









