







Linear Regression can’t be used for Classification Problems
Linear Regression isn’t Working Well for Regression Problem
An extra unusual point may affect all the linear function thus cause some error in the classification process.
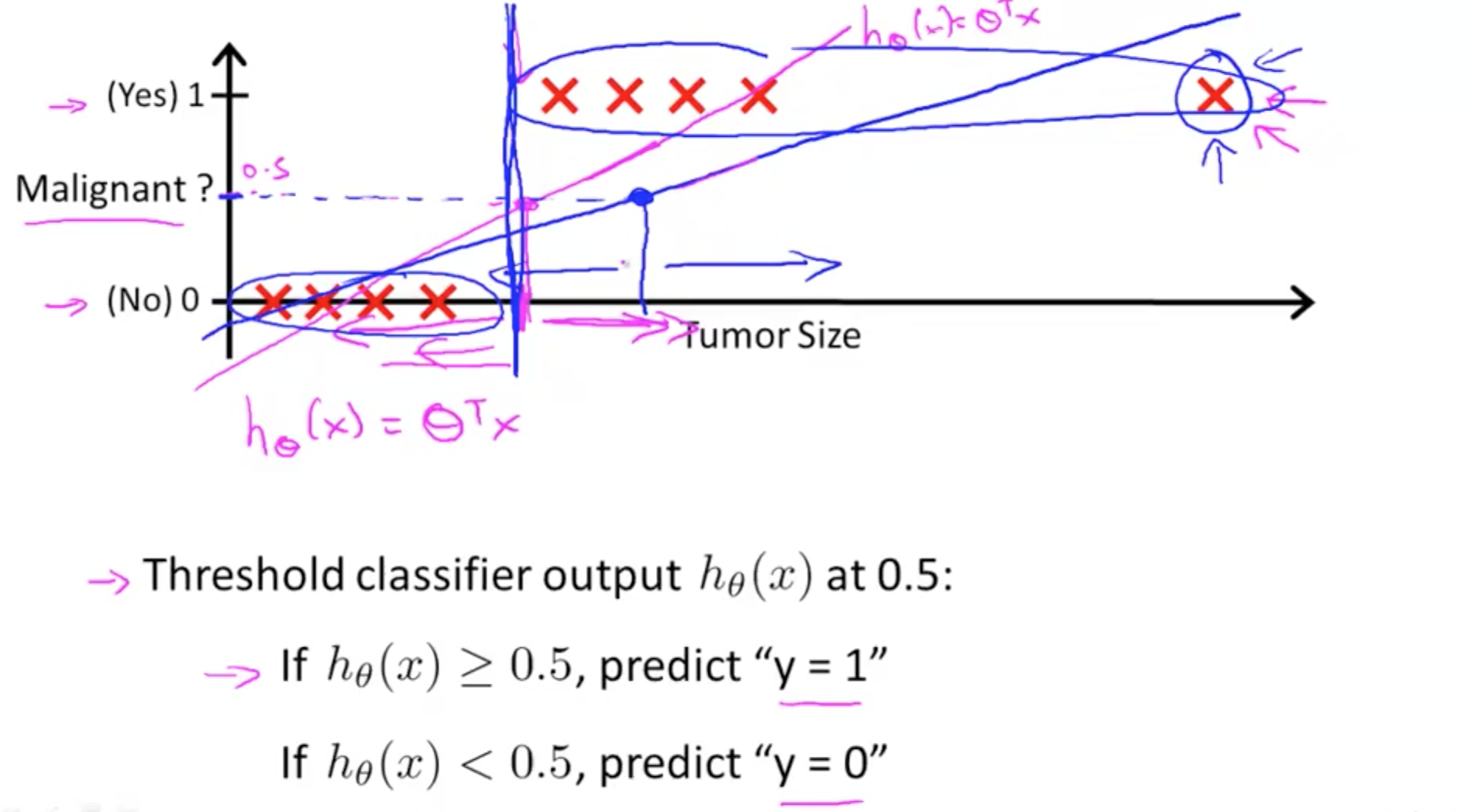
Logistic Regression Model
Sigmoid Function or Logistic Function
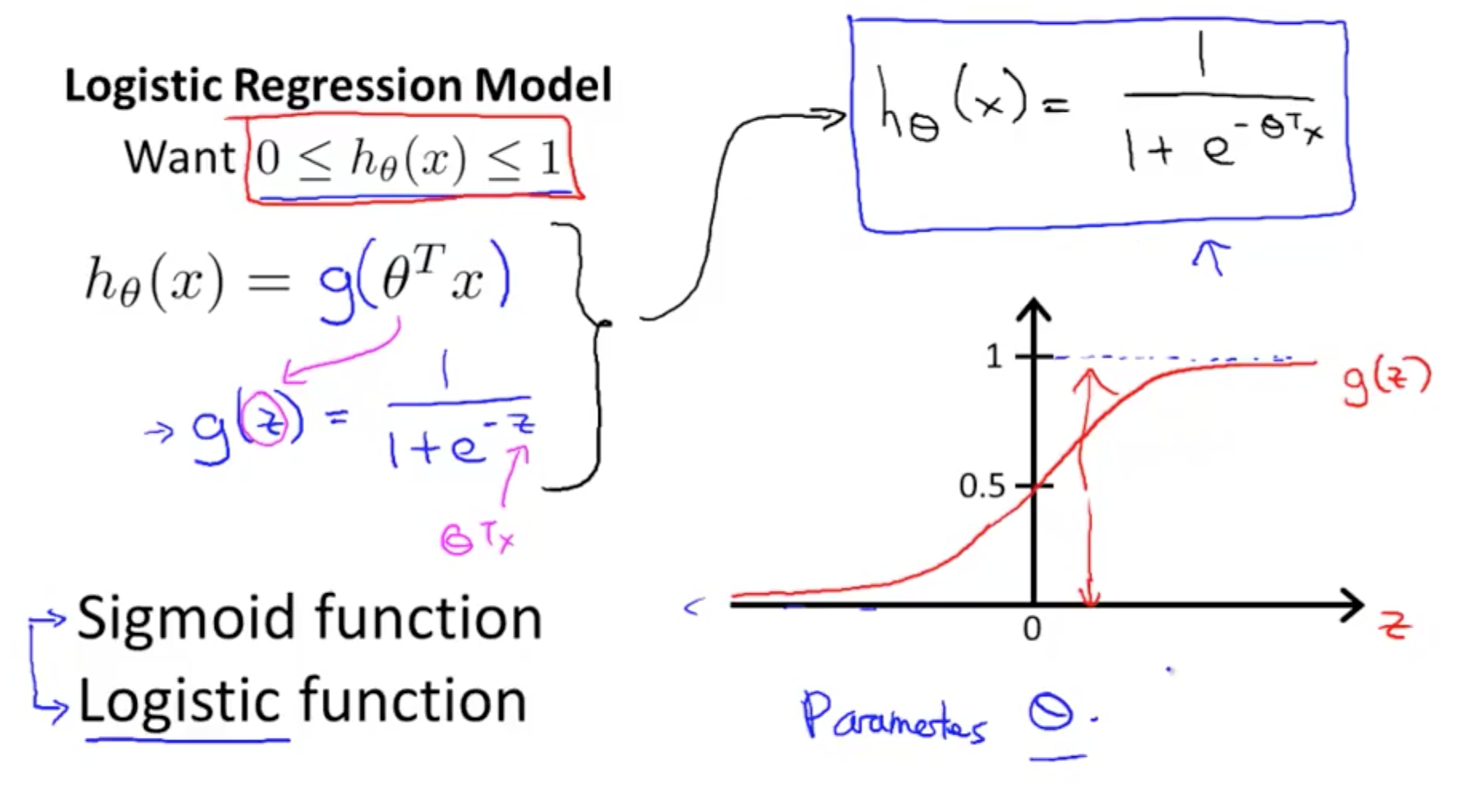
Decision Boundary
The predict is that if hθ(x)≥0.5 ,then y=1 ,and if hθ(x)<0.5 ,then y=0 which is also equivalent to that if θTx≥0 ,then y=1 and if θTx<0 ,then y=0

Example:
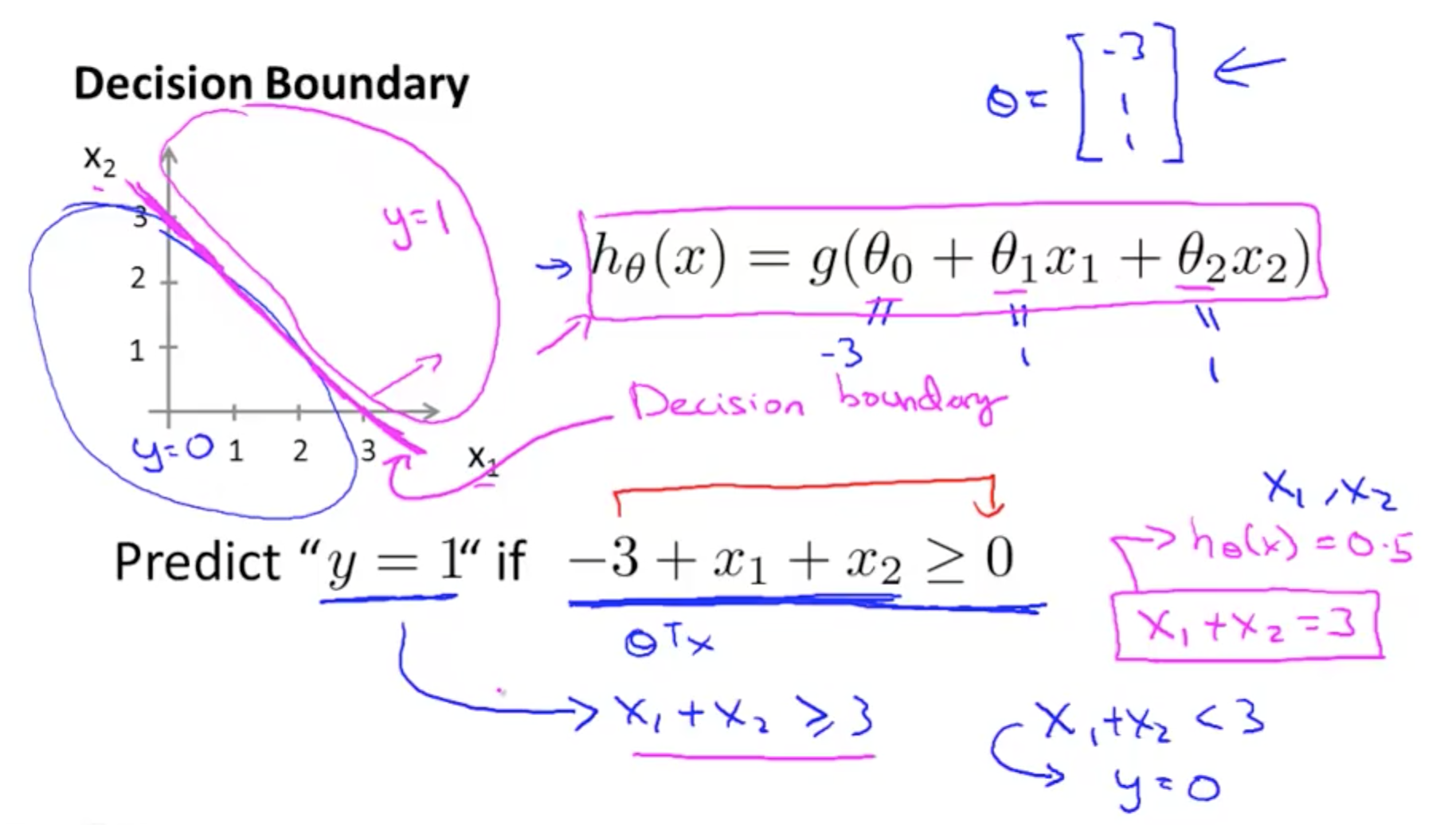
Cost Function and Gradient Descent for Logistic Regression
Cost Function for Logistic Regression

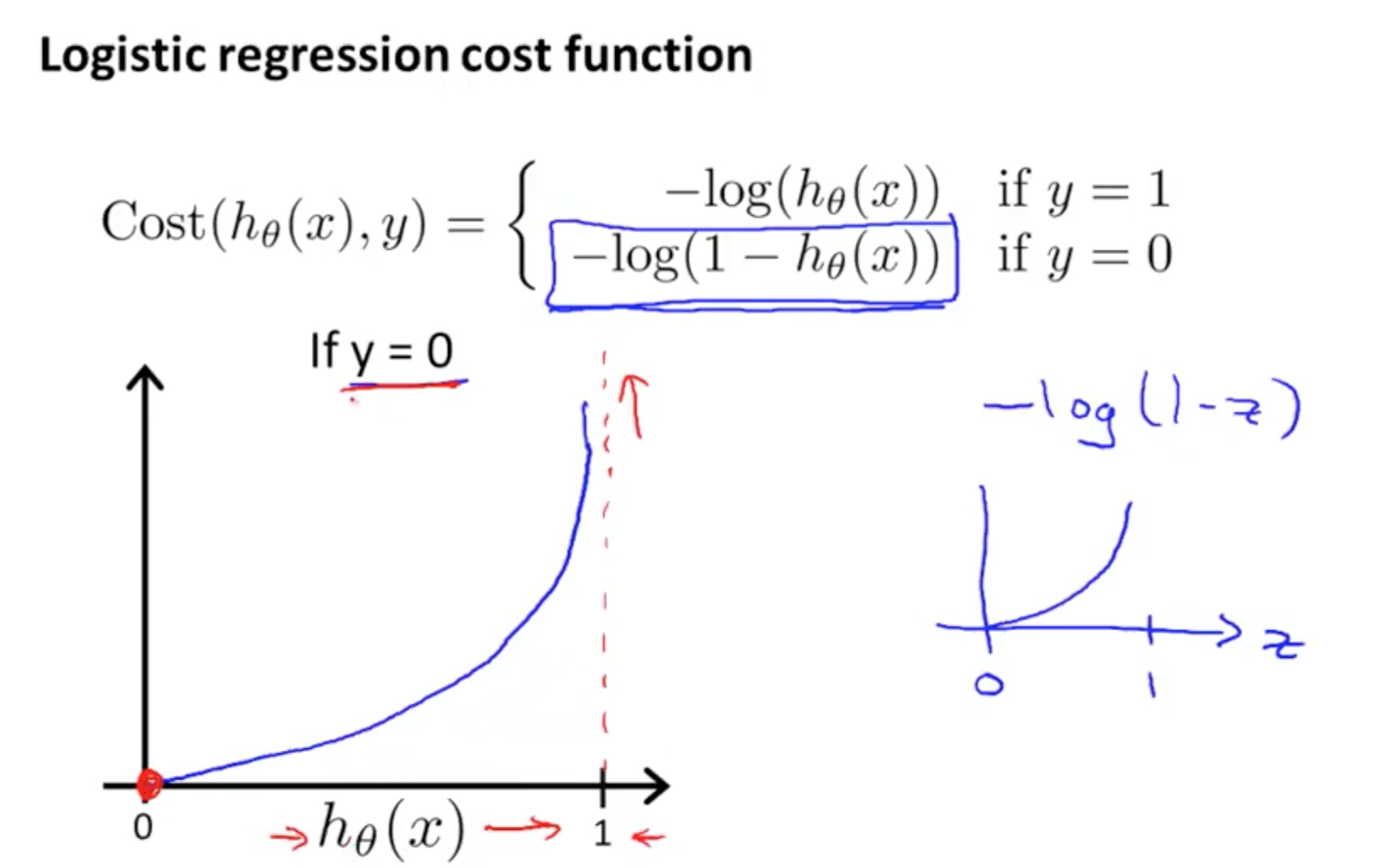
Together will be:
for linear regression:
for logistic regression:
Gradient descent of logistic regression is the same with linear regression

Several different way of optimization algorithm

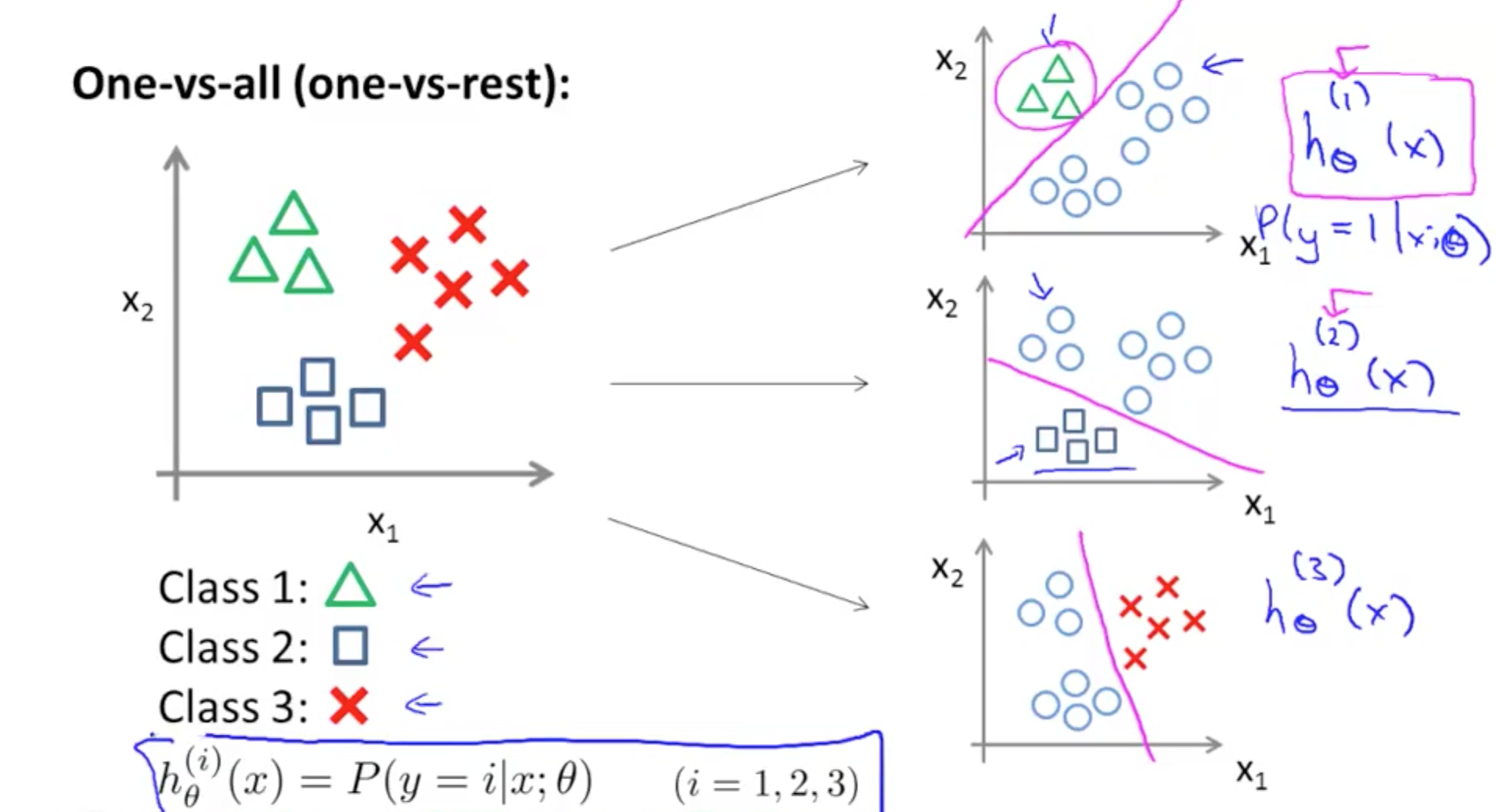
Multiclass Classification
One Vs All
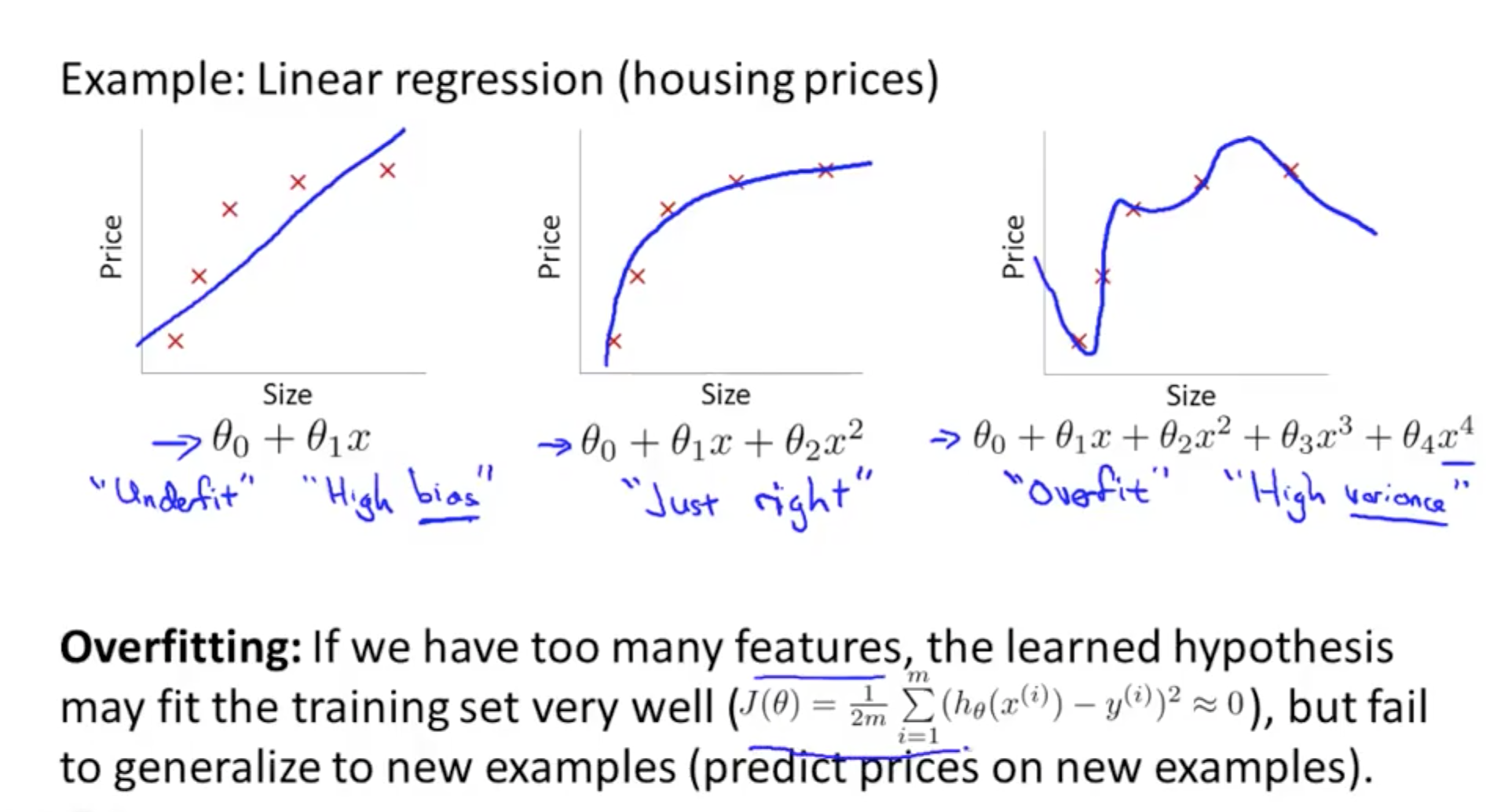
Problem of Overfitting
Under fitting - Just right - Over fitting
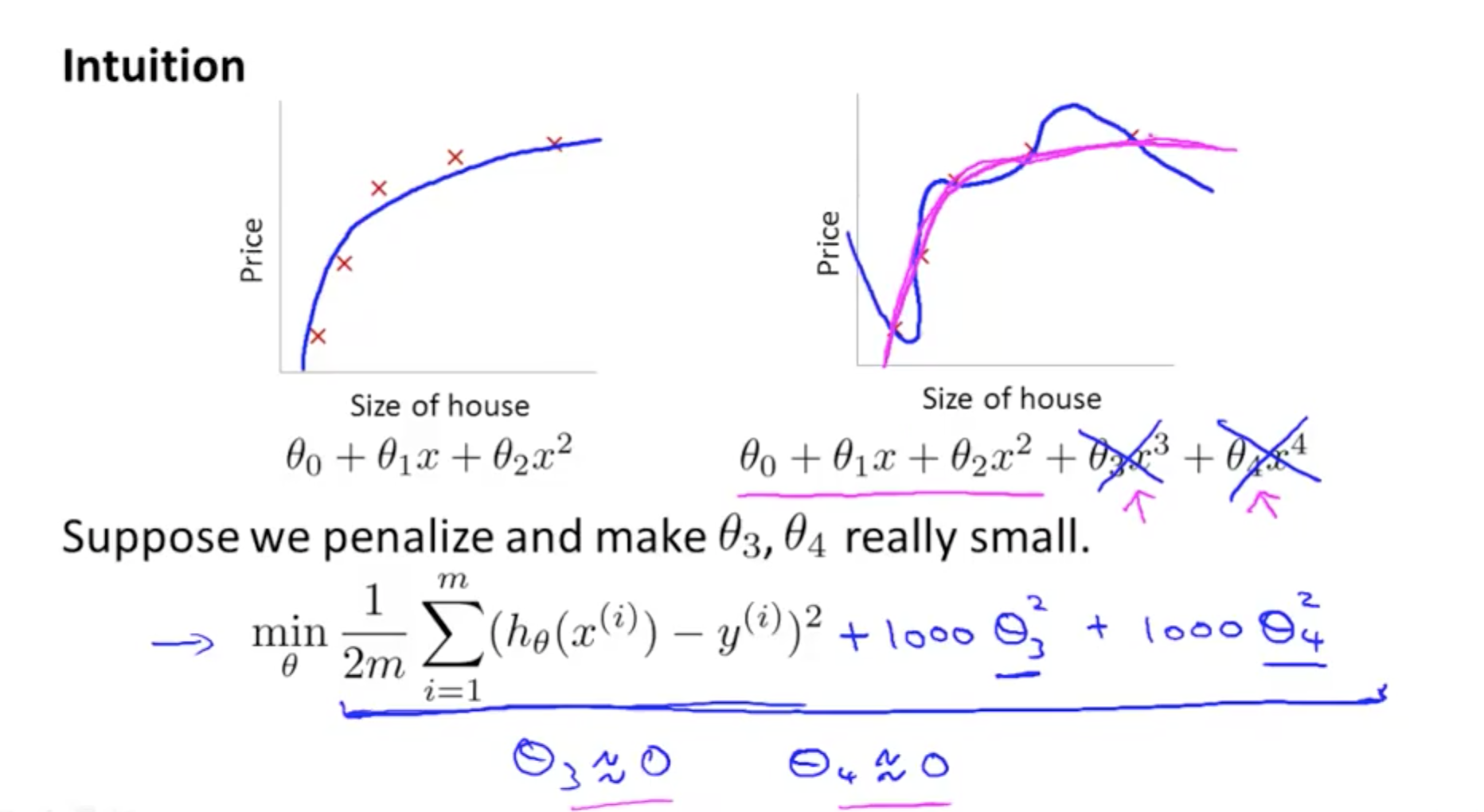
How to solve overfitting - Regularisation

Intuition of Regularisation - to make θ small
Shrink all the parameters - starts from θ1 not from θ0 :

Regularisation Parameters
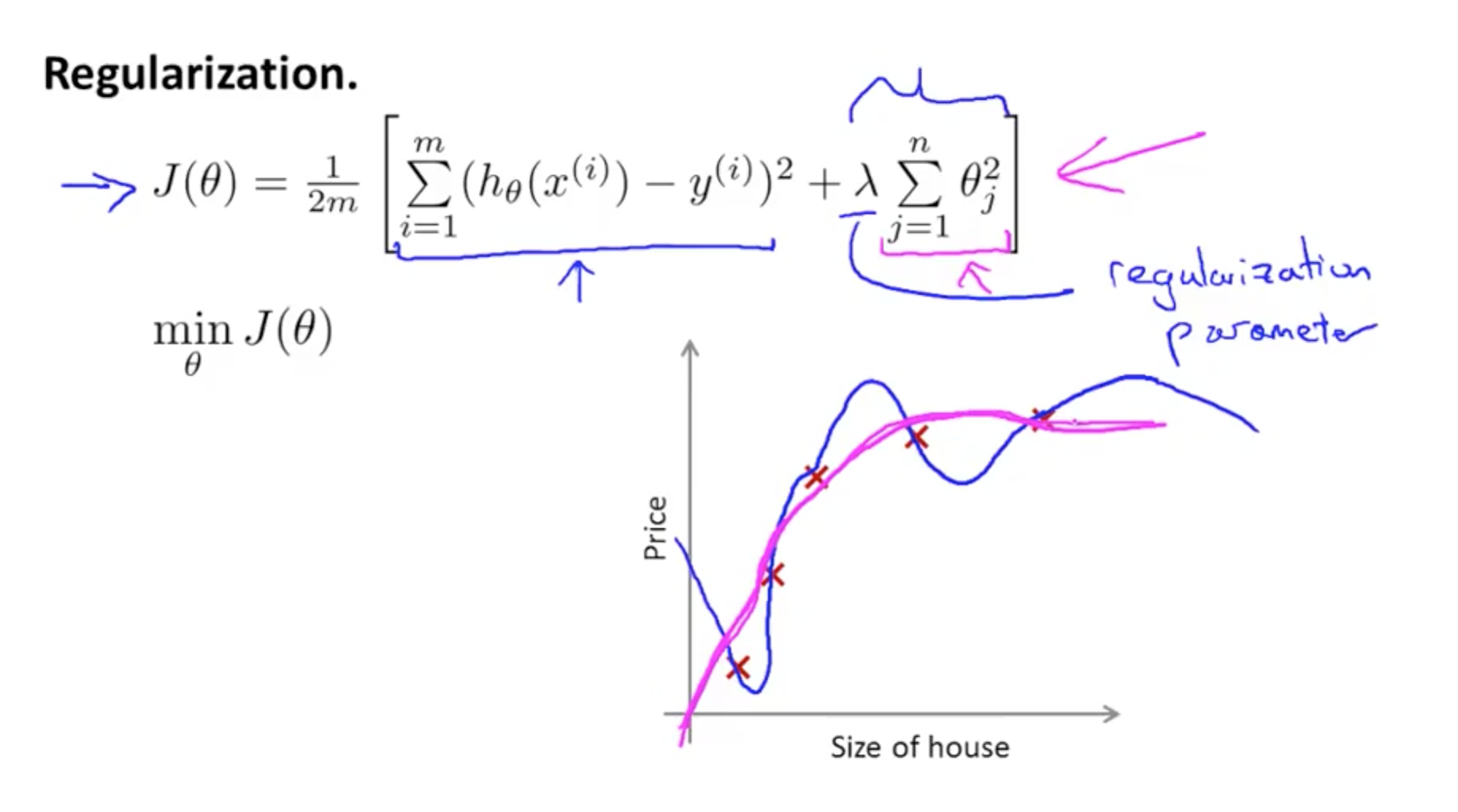
But the new parameter λ used for regularisation can’t be too big otherwise will cause the all the θ too small (almost equals to 0) - underfitting

Cost Function and Gradient Descent With Regularization
Cost Function:

Gradient Descent:

Normal Equation

The θ corresponding to global minimum:
This will also make the original non-invertible matrix invertible

Regularized Logistic Regression
Cost Function:
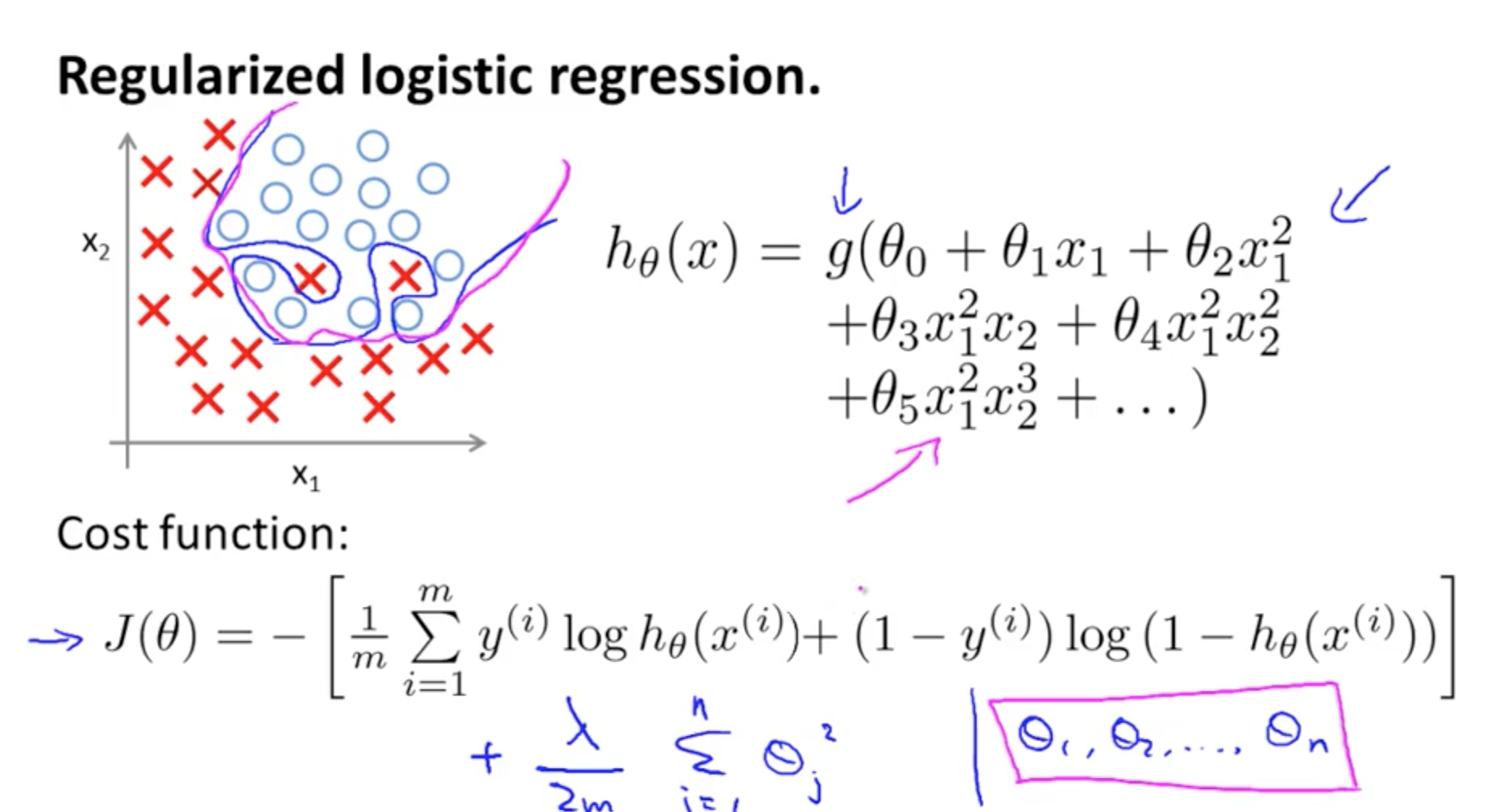
Repeating the Gradient Descent:

Matlab syntax:
fminunc(costFunction)
function[jVal,gradient]=costFunction(X,y, θ )

Weekly Matlab Exercise
%sigmoid:
function g = sigmoid(z)
g = zeros(size(z));
g=1./(1+exp(-z))
end
%plotData:
function plotData(X, y)
figure; hold on;
pos=find(y==1);neg=find(y==0);
plot(X(pos,1),X(pos,2),'k+','LineWidth',2,'MarkerSize',7);
plot(X(neg,1),X(neg,2),'ko','MarkerFaceColor','y','MarkerSize',7);
hold off;
end
%costFunction(without regularisation):
function [J, grad] = costFunction(theta, X, y)
m = length(y); % number of training examples
J = 0;
grad = zeros(size(theta));
J=1/m*(-log(sigmoid(X*theta))'*y-log(1-sigmoid(X*theta))'*(1-y));
grad=1/m*((sigmoid(X*theta)-y)'*X)';
end
%predict:
function p = predict(theta, X)
m = size(X, 1); % Number of training examples
p = zeros(m, 1);
p=round(1./(1+exp(-X*theta)))
end
%costFunction(with regularisation):
function [J, grad] = costFunctionReg(theta, X, y, lambda)
m = length(y); % number of training examples
J = 0;
grad = zeros(size(theta));
theta2=theta(2:size(theta,1),1)
J=1/m*(-y'*log(sigmoid(X*theta))-(1.-y)'*log(1-sigmoid(X*theta)))+lambda./(2*m)*(theta2'*theta2)
grad1=(1/m*(sigmoid(X*theta)-y)'*X)'
theta1=lambda/m*theta
theta1(1,1)=0
grad=grad1+theta1
end
%use the fminunc function:
initial_theta = zeros(size(X, 2), 1);
% Set regularization parameter lambda to 1 (you should vary this)
lambda = 1;
% Set Options
options = optimset('GradObj', 'on', 'MaxIter', 400);
% Optimize
[theta, J, exit_flag] = ...
fminunc(@(t)(costFunctionReg(t, X, y, lambda)), initial_theta, options);















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









