







为什么要初始化?暴力初始化效果如何?
神经网络,或者深度学习算法的参数初始化是一个很重要的方面,传统的初始化方法从高斯分布中随机初始化参数。甚至直接全初始化为1或者0。这样的方法暴力直接,但是往往效果一般。本篇文章的叙述来源于一个国外的讨论帖子[1],下面就自己的理解阐述一下。
首先我们来思考一下,为什么在神经网络算法(为了简化问题,我们以最基本的DNN来思考)中,参数的选择很重要呢?以sigmoid函数(logistic neurons)为例,当x的绝对值变大时,函数值越来越平滑,趋于饱和,这个时候函数的倒数趋于0,例如,在x=2时,函数的导数约为1/10,而在x=10时,函数的导数已经变成约为1/22000,也就是说,激活函数的输入是10的时候比2的时候神经网络的学习速率要慢2200倍!

为了让神经网络学习得快一些,我们希望激活函数sigmoid的导数较大。从数值上,大约让sigmoid的输入在[-4,4]之间即可,见上图。当然,也不一定要那么精确。我们知道,一个神经元j的输入是由前一层神经元的输出的加权和,。因此,我们可以通过控制权重参数初始值的范围,使得神经元的输入落在我们需要的范围内,以便梯度下降能够更快的进行。
先来看个例子。
在创建了神经网络后,通常需要对权重和偏置进行初始化,大部分的实现都是采取Gaussian distribution来生成随机初始值。假设现在输入层有1000个神经元,隐藏层有1个神经元,输入数据x为一个全为1的1000维向量,采取高斯分布来初始化权重矩阵w,偏置b取0。下面的代码计算隐藏层的输入z:

然而通过上述初始化后,因为w服从均值为0、方差为1的正太分布,x全为1,b全为0,输入层一共1000个神经元,所以z服从的是一个均值为0、方差为1000的正太分布。修改代码如下,生成20000万个z并查看其均值、方差以及分布图像:

输出结果如下:

输出图像如下:
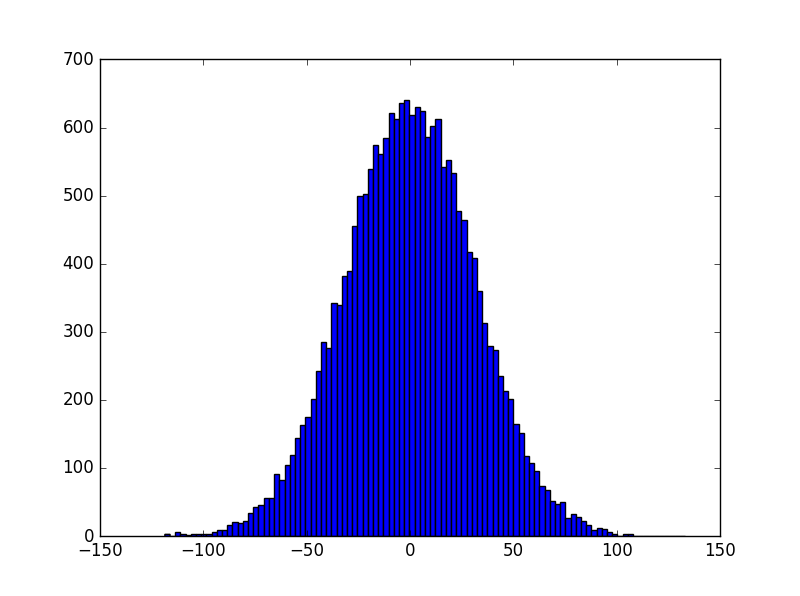
z分布(1)
在此情况下,z有可能是一个远小于-1或者远大于1的数,通过激活函数(比如sigmoid)后所得到的输出会非常接近0或者1,也就是隐藏层神经元处于饱和的状态。所以当出现这样的情况时,在权重中进行微小的调整仅仅会给隐藏层神经元的激活值带来极其微弱的改变。
而这种微弱的改变也会影响网络中剩下的神经元,然后会带来相应的代价函数的改变。结果就是,这些权重在我们进行梯度下降算法时会学习得非常缓慢。
因此,我们可以通过改变权重w的分布,使|z|尽量接近于0 而不是使权重w接近0,如果x非常非常小,则权重应该稍微大点,这样在正常的激活函数下能够分布在0附近。这就是我们为什么需要进行权重初始化的原因了。
权重初始化:How(取决于输入x,以及激活函数的特点,总的就是为了最后加权求和后更好的激活)
一种简单的做法是修改w的分布,使得z服从均值为0、方差为1的标准正态分布。根据正太分布期望与方差的特性,将w除以sqrt(1000)即可。修改后代码如下:

输出结果如下:

输出图像如下:
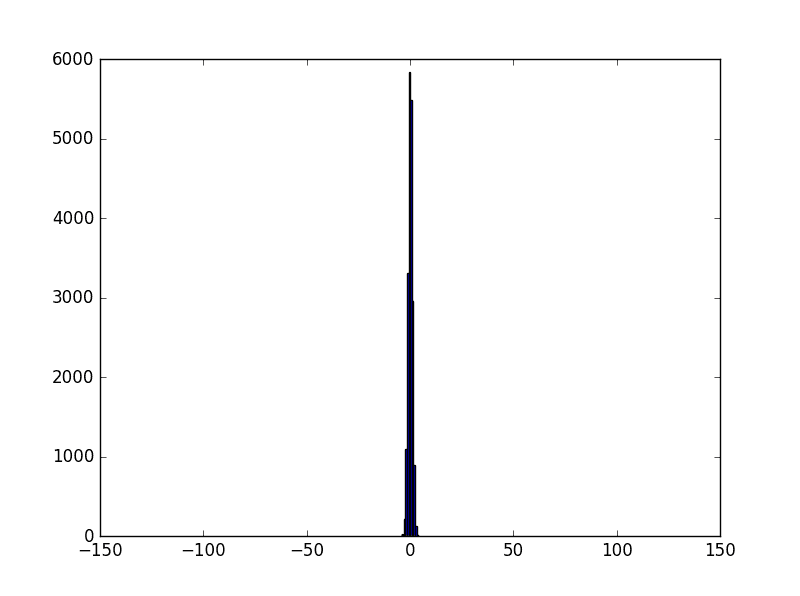
z分布(2)
这样的话z的分布就是一个比较接近于0的数,使得神经元处于不太饱和的状态,让BP过程能够正常进行下去。
除了这种方式之外(除以前一层神经元的个数n_in的开方),还有许多针对不同激活函数的不同权重初始化方法,比如兼顾了BP过程的除以( (n_in + n_out)/2 ),还有初始化方法是截断正态分布,将权重在离均值两个标准差外的值去掉。具体可以参考Stanford CS231n课程中提到的各种方法。
from:http://www.sohu.com/a/135067464_714863
https://blog.csdn.net/qq_26898461/article/details/50996308














 2686
2686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









