







目录
1.线性回归中的特征权重β:
线性模型中,特征可以归类为:数值特征(比如气温)、二进制特征(性别0/1)、范畴特征(天气:下雨、阴天、晴天,使用one-hot编码,让具体类别有自己的二进制选项)
 2. 树模型中的feature_importance:
2. 树模型中的feature_importance:
无论是经典的决策树算法,还是基于决策树算法的boost算法(xgboost)还是bagging算法(随机森林),都能利用基尼系数,信息增益和分裂次数,添加权重计算特征重要性。
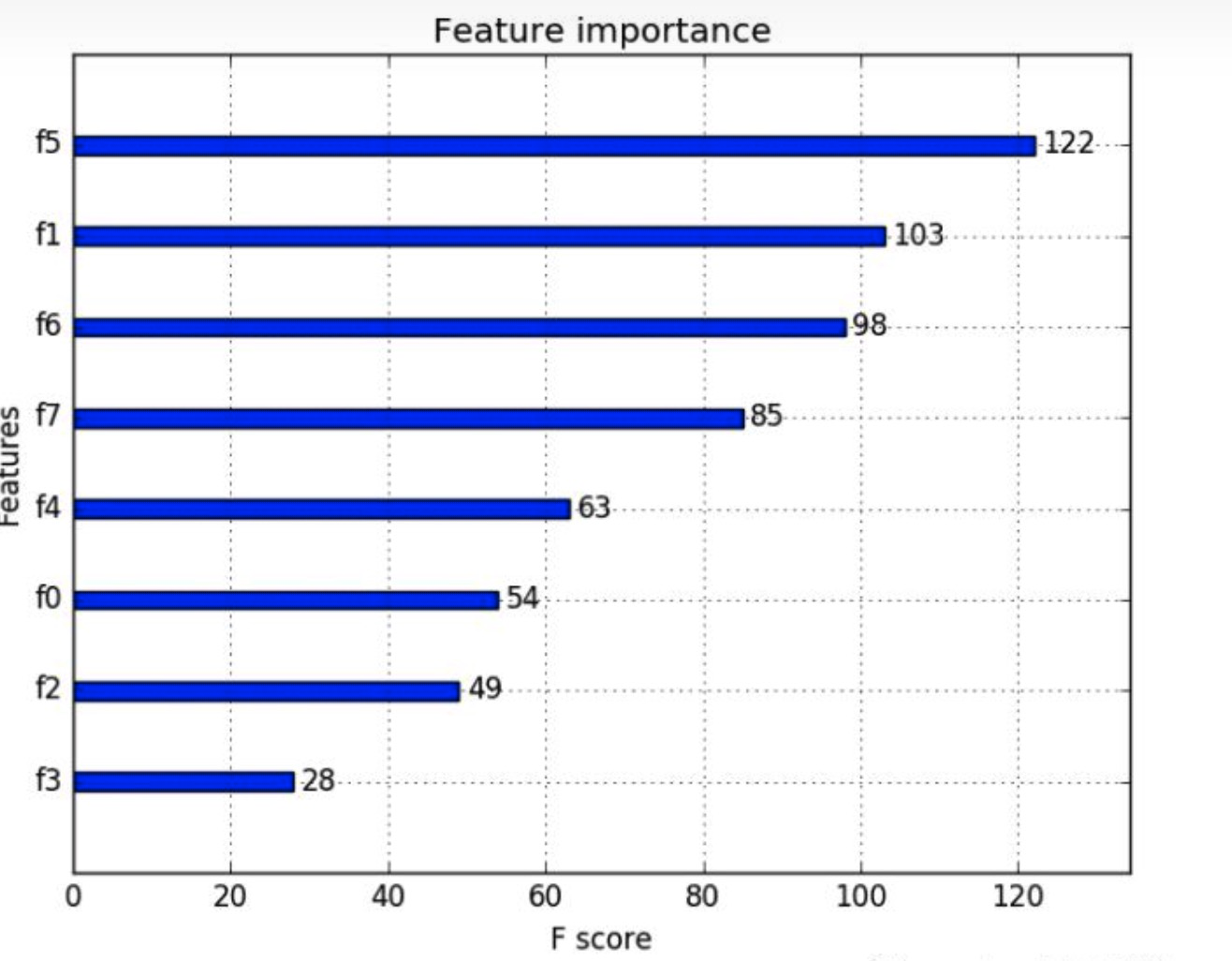
3. lime:
Lime(Local Interpretable Model-Agnostic Explanations)是使用训练的局部代理模型来对单个样本进行解释。假设对于需要解释的黑盒模型,取关注的实例样本,在其附近进行扰动生成新的样本点,并得到黑盒模型的预测值,使用新的数据集训练可解释的模型(如线性回归、决策树),得到对黑盒模型良好的局部近似。
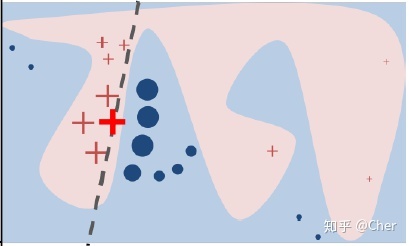
实现步骤
-
如上图是一个非线性的复杂模型,蓝/粉背景的交界为决策函数;
-
选取关注的样本点,如图粗线的红色十字叉为关注的样本点X;
-
定义一个相似度计算方式,以及要选取的K个特征来解释;
-
在该样本点周围进行扰动采样(细线的红色十字叉),按照它们到X的距离赋予样本权重;
-
用原模型对这些样本进行预测,并训练一个线性模型(虚线)在X的附近对原模型近似。
这样就可以使用可解释性的模型对复杂模型进行局部解释。
4. shap:
基于博弈论计算边际效益来计算各个特征对结果的贡献:
小明,小军,小强(是的,就是他们小学课本三人组),组队参加王者农药大赛,大赛设定哪个队先拿100个人头,可以获得一万元奖金。终于在他们三个的通力配合下,赢得了比赛,获得一万元奖金,但到了分钱阶段,分歧出现了,因为他们三个人的水平、角色不一,小强个人实力最强善用高输出角色,光是他自己就拿了大半的人头;但若是按照人头数分,也不合适,因为前期小强有几次差点挂掉,多亏队友及时治疗,另外有好多人头也是靠攻速抢到的。那么,应该怎么分配这一万块钱,才是最公平的呢?
_
机智(厚脸皮)的小老弟登场了,这个问题,我们可以从贡献出发:
小强自己可以干掉35个人,小军可以干掉15个人,小明可以干掉10个人,显然,他们每个人都无法独立完成目标。
小强和小军联手可以干掉70个人,小强和小明可以干掉60个人,小军和小明联手可以干掉40个人,同样,无法完成任务。
而只有当三个人联手时候,才可以干掉100个人,达成目标。
(可以理解为小军小强小明有辅助有输出有坦克)
考虑先后顺序,他们三个人一共有6种组队方式。
我们定义边际贡献:假定初始组合为小强一个人,贡献35,加入小军后,他们俩的组合贡献为70,则小军的边际贡献就是70-35=35,再加入小明,三个人的组合贡献为100,则小明的边际贡献为100-70=30;
根据组合次序计算全部的组合及组合中每个人的边际贡献,如表格所示,则可以求得每个人的贡献度。
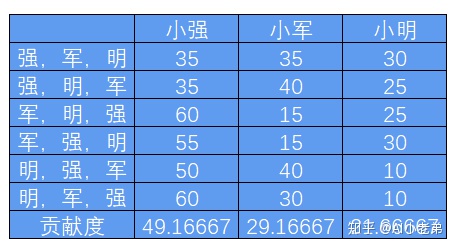
因此,最合理的分配方案就是小强小军小明分别获得4916、2917、2167。
大家可能奇怪上面的故事和本文主题有啥关系,实际上,上面的问题就是通俗的解释了SHAP方法的核心:shapley value(沙普利值)的简化版计算方法。
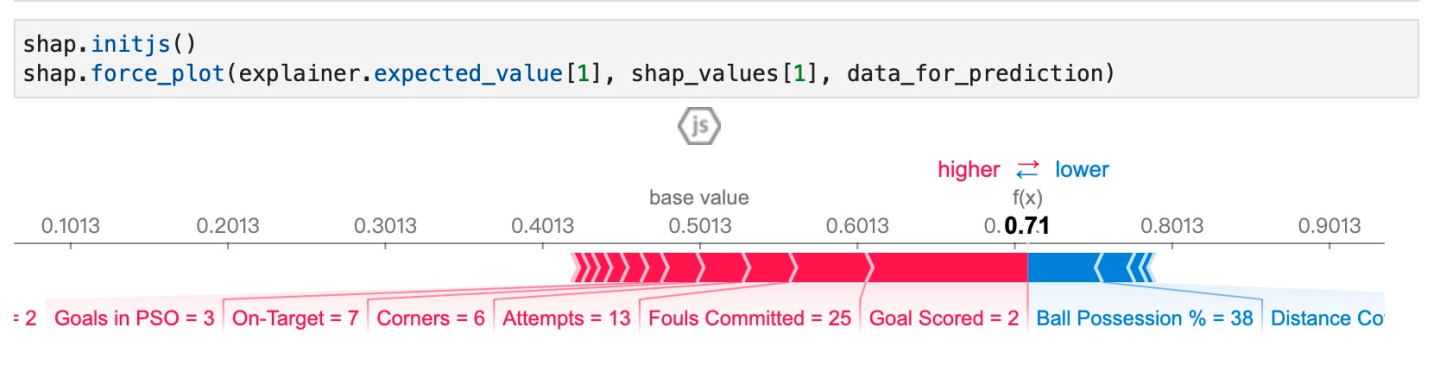
结果展示:
5. 各种算法对比:
-
线性算法的权重需要可以非常清晰的表明特征的重要程度,以及对结果的影响,但是缺点是需要做标准化,并缺模型准确度不高。
-
树类型算法的feature_importance也非常实用,特别是最近大火的xgboost, lightgbm都基于树算法,树类型算法无需对数据样本进行标准化,但是无法实现对单一样本对预测结果影响的刻画。
-
lime和shap都能实现单一单一样本对预测结果影响的刻画,但是对整个样本对预测结果的刻画上稍显不足,可以用在各种类型算法的解释性,以及线上模型突然结果恶化的场景描述上。


















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









