






原书《Introduction to Apache Flink》,没有找到中文版,硬着头皮啃。
Flink的命名即描述了它的风格,“flink”一词在德语中是快且灵活的意思,logo是一只柏林红褐色松鼠。
-------------------------------------------------------
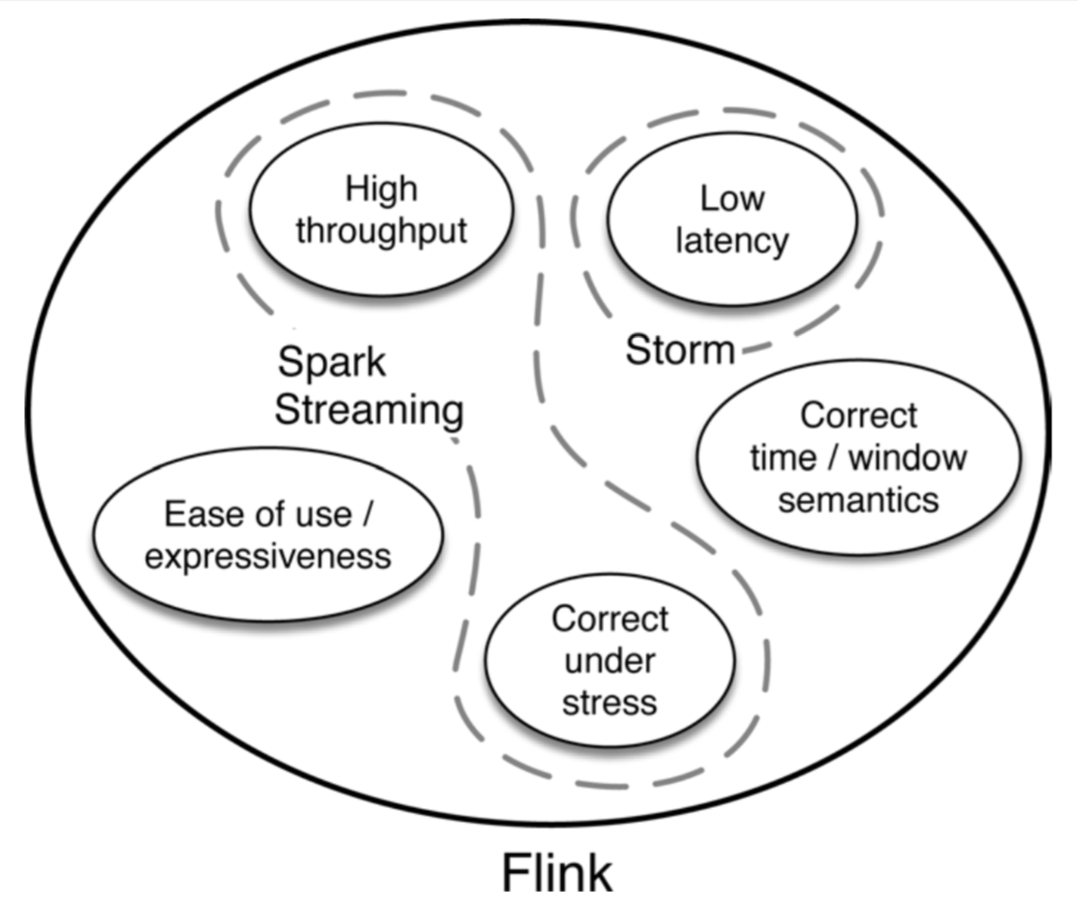
一、平行对比
1. Apache Storm
流式处理,低延迟。
难以获得高吞吐。
不保证“最少一次”(exactly-once guarantees)。
2. Lambda Architecture
提供延迟的批处理和流式处理。
需要为批处理和流式处理的两套API编程两套业务代码。运维困难。
3.Apache Spark Streaming
利用“微批”近似流式。
高吞吐。
保证“最少一次”。
4. Storm Trident
Storm的扩展。
依靠“微批”保证“最少一次”,以时效性的降低为代价。

-------------------------------------------------------
二、流式架构
传统的架构,状态维护在数据库中,属于数据库集约型:
(1)数据分析慢、复杂。
(2)过于集约,所有应用需要访问数据库系统。
(3)容错处理逻辑复杂。
(4)在大规模分布式系统中,维护状态一致性越来越困难。
flink流式架构包含两部分:消息传输层和消息处理层。
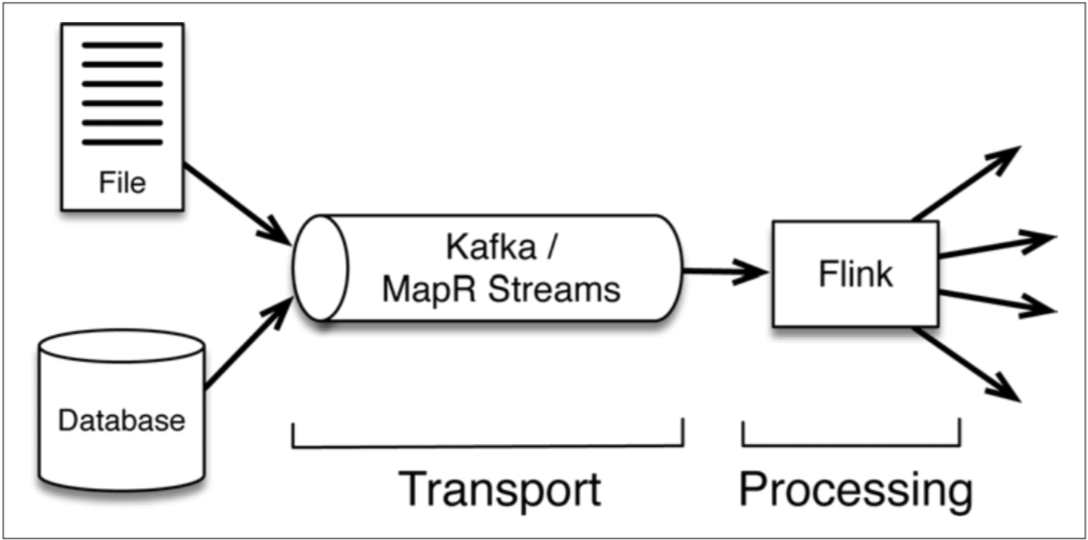
message transport layer的两个代表分别是kafka和MapR:
(1)高性能。
(2)高可靠。数据持久化,可回放。
(3)生产者、消费者解耦。消费者可定制化订阅,消费进度可控。
(4)增加消费者不影响其他的消费者,对queue带来的压力微不足道。
(5)全球流复制。MapR具备这个能力,双向循环的流复制可以保持数据一致性。
MapR的性能优于Kafka,且具备流复制的能力,有必要了解一下:https://mapr.com/blog/kafka-vs-mapr-streams-why-mapr/
-------------------------------------------------------
三、Flink的能力
1. window
如图,传统的微批窗口很难对其到真实的session,这就影响了流式处理的准确性。
而Flink可以设置动态的阈值,如果超过这个时间阈值都没有事件发生则认为session结束,以此形成一个window。
2.event time versus processing time
相比于老的流式处理,Flink区分事件时间和处理时间。在计算窗口中,使用事件时间更加准确。
3.checkpoint
使用checkpoint追踪状态,便于失败重置或者回溯处理。
4. 低延迟高准确
5. 开发和操作友好
表达能力减少错误概率,状态维护(开发人员无需在应用中管理状态),一套技术同时胜任流式和批处理
四、处理时间
流式处理和批处理的区别之一就是是否需要显示的处理时间。
批处理的问题:
1.部件太多。每个部件都有学习和管理成本以及自身的BUG。
2.隐式地处理时间。批任务调度时间不一定与业务期望的时间一致,这就导致开发运维的概念和业务的概念混淆。
3.事件时间和处理时间不一致,事件可能进入错误的批。
4.批的区间在边界上不是很明确。
lambda架构:
流式处理提供实时的近似结果,批处理提供小时级别的准确结果。
流式架构(message transport + flink):
解决了以上问题。
1.处理变慢或数据陡增可以反压在Q;
2.乱序事件处理对用户透明;
3.在flink中修改窗口的定义从而得到会话窗口;
4.可回放事件;
5.减少了多个系统的学习、管理和开发成本;
流处理和批处理最主要的两个区别就是:(1)以真实的事件流式的发生方式对待事件,而不是人为的分批;(2)显示定义分批窗口,而不是隐含在聚合、计算和调度中。















 222
222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









