








motivation:
a. 存在的问题:
- 以前的大多数只使用注意机制作为基于FCN的辅助模块,这限制了它们建模全局上下文的能力。
- 在以往的方法中,经常使用语言的Self-Attention来提取信息 。对于这些方法,它们的语言理解仅来自语言表达本身,而不与图像交互,因此它们无法区分哪些强调更合适、更有效,更适合特定的图像。因此,他们检测到的重点可能是不准确的或低效的。
- 在以前的工作中,对Transformer Decoder的查询通常是一组固定的学习向量,每个向量都用于预测一个对象。如果在Decoder中使用固定查询,必须有一个假设,即输入图像中的对象是在一些统计规则下分布的 ,这与RES的随机性不匹配。
b. 解决方案:
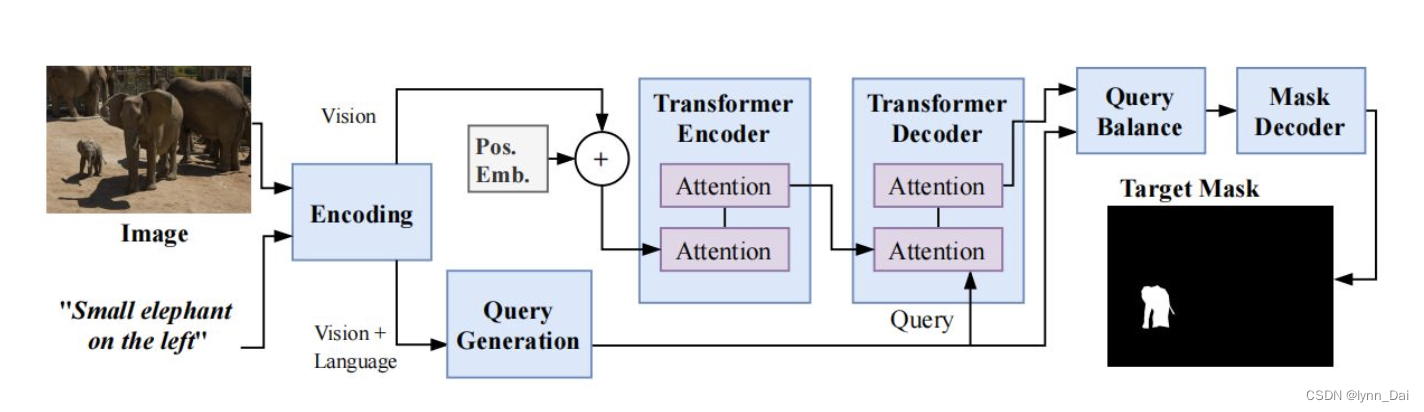
- 在本文中,作者采用了Transformer结构。作者使用视觉引导从语言特征中生成一组查询向量,并使用这些向量来“查询”给定的图像,并从响应中生成分割mask。这种基于注意力的框架在计算的每个阶段实现多模态特征之间的全局操作,使网络能够更好地建模视觉和语言信息的全局上下文。
- 为了处理由图像的多样性和语言的无约束表达所引起的随机性,作者结合视觉特征,以不同的方式来理解语言表达。
- 为了解决这些问题,作者提出了一个查询生成模块(QGM) ,基于该语言和相应的视觉特征生成多个不同的查询向量。
- 为了确保生成的查询向量有效并找到更适合图像和语言的理解方式,进一步提出了一个查询平衡模块(QBM)来自适应地选择这些查询的输出特征,以便更好地生成掩码。
contribution:
模型在不同层次上构建了语言和视觉特征之间的深度交互,极大地增强了多模态特征的融合和利用。此外,所提出的模块是轻量级的,其参数大小大致相当于七个卷积层。
- 设计了一种视觉-语言转换器(VLT)方法来构建多模态信息之间的深度交互,并增强对视觉-语言特征的整体理解。
- 提出了一个从不同理解方式理解语言的查询生成模块,以及一个查询平衡模块,以专注于合适的方式。















 1058
1058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









