







1. 共线性
1) 特征间共线性:
两个或多个特征包含了相似的信息,期间存在强烈的相关关系
2) 常用判断标准:
两个或两个以上的特征间的相关性系数高于0.8
3) 共线性的影响:
降低运算效率
降低一些模型的稳定性
弱化一些模型的预测能力
4) 处理方式:
删除:一组相互共线的特征中只保留与y相关性最高的一个
变换:对共线的两列特征进行求比值、求差值等计算
1.1 数据导入及查看
1)查看数据量
# 特征工程的演示
import pandas as pd
import matplotlib.pyplot as plt
import os
os.chdir(r'C:\Users\86177\Desktop')
# 样例数据读取
df = pd.read_excel('realestate_sample_preprocessed.xlsx')
# 数据集基本情况查看
print(df.shape)
–> 输出的结果为:(数据已经由原来的1000条变成了898条)
(898, 10)
2) 查看各字段数据类型
print(df.dtypes)
–> 输出的结果为:
id int64
complete_year int64
average_price float64
area float64
daypop float64
nightpop float64
night20-39 float64
sub_kde float64
bus_kde float64
kind_kde float64
dtype: object
3) 查看数据缺失值情况
id 0
complete_year 0
average_price 0
area 0
daypop 0
nightpop 0
night20-39 0
sub_kde 0
bus_kde 0
kind_kde 0
dtype: int64
4) 查看基本数据
print(df.head())
–> 输出的结果为:
id complete_year average_price area daypop nightpop night20-39 sub_kde bus_kde kind_kde
0 107000909879 2008 33464.0 25.70 119.127998 150.060287 53.842050 5.241426e-11 0.279422 7.210007e-11
1 107000908575 1996 38766.0 26.57 119.127998 150.060287 53.842050 5.241426e-11 0.279422 7.210007e-11
2 107000846227 2005 33852.0 28.95 436.765809 376.523010 183.301881 1.523092e-24 0.231135 2.922984e-01
3 107000676489 1995 39868.0 30.10 247.545324 385.412857 142.819971 4.370519e-11 0.321443 2.401811e-01
4 107000676873 1995 42858.0 30.10 247.545324 385.412857 142.819971 4.370519e-11 0.321443 2.401811e-01
1.2 变量相关性矩阵
既然要判断共线性,就需要查看各变量之间的相关性系数
correlation_table = df.drop(columns='id').corr()
print(correlation_table)
–> 输出的结果为:
complete_year average_price area daypop nightpop night20-39 sub_kde bus_kde kind_kde
complete_year 1.000000 0.203111 0.317025 -0.103519 -0.110359 -0.078844 -0.007865 -0.424366 -0.198453
average_price 0.203111 1.000000 0.128352 0.113801 0.084533 0.111855 0.312138 0.091660 0.256919
area 0.317025 0.128352 1.000000 -0.054506 -0.060293 -0.047174 0.350410 -0.199929 0.045079
daypop -0.103519 0.113801 -0.054506 1.000000 0.946124 0.935621 0.015707 0.486652 0.139208
nightpop -0.110359 0.084533 -0.060293 0.946124 1.000000 0.982556 -0.008679 0.468839 0.140402
night20-39 -0.078844 0.111855 -0.047174 0.935621 0.982556 1.000000 -0.012920 0.415522 0.141861
sub_kde -0.007865 0.312138 0.350410 0.015707 -0.008679 -0.012920 1.000000 -0.090661 0.041546
bus_kde -0.424366 0.091660 -0.199929 0.486652 0.468839 0.415522 -0.090661 1.000000 0.397623
kind_kde -0.198453 0.256919 0.045079 0.139208 0.140402 0.141861 0.041546 0.397623 1.000000
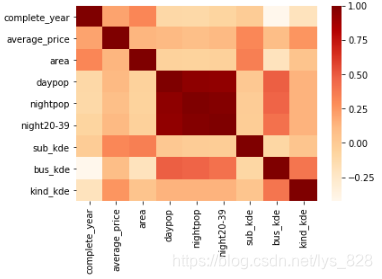
1.3 相关性矩阵进行可视化
通过上表绘制相关性矩阵热力图
import seaborn as sns
sns.heatmap(correlation_table,cmap='OrRd')
plt.show()
–> 输出的结果为:(可以看出中间的几个特征变量的相关性特别的高,也就对应了上一篇博文中的可以采用daypop nightpop night20-39三个变量进行彼此缺失值的填充)
1.4 查看共线的变量与标签之间的关系
print(df[['average_price','daypop','nightpop','night20-39']].corr())
–> 输出的结果为:(从第一列可以看出,与标签数据相关性最高的是daypop特征)
average_price daypop nightpop night20-39
average_price 1.000000 0.113801 0.084533 0.111855
daypop 0.113801 1.000000 0.946124 0.935621
nightpop 0.084533 0.946124 1.000000 0.982556
night20-39 0.111855 0.935621 0.982556 1.000000
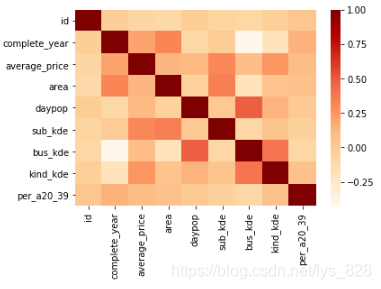
1.5 保留与标签相关性最高的特征变量,其余变量进行比例处理
def age_percent(row):
if row['nightpop'] == 0:
return 0
else:
return row['night20-39']/row['nightpop']
df['per_a20_39'] = df.apply(age_percent,axis=1)
df = df.drop(columns=['nightpop','night20-39'])
correlation_table = df.corr()
sns.heatmap(correlation_table)
–> 输出的结果为:(注意处理的时候,可能含有0在分母上)
2. 数据降维与特征提取
1) 处理目的:
降低不相关特征对于模型准确性的干扰
降低模型复杂度,提高模型泛化能力
减少建模特征,提高模型训练与预测速度
2) 处理方法:
基于数据理解,直接删除
使用主成分分析法(PCA)对特征进行变换
使用机器学习模型对特征进行筛选
2.1 查看特征参数
print(df.columns)
–> 输出的结果为:(一共有的是7个特征)
Index(['id', 'complete_year', 'average_price', 'area', 'daypop', 'sub_kde',
'bus_kde', 'kind_kde', 'per_a20_39'],
dtype='object')
2.2 PCA主成分分析
主成分对于数据的解释方差百分比,数值越大,说明选取的主成分对于数据特征的提取的程度就越高,下面假设选取其中的5个特征数据,进行判断
from sklearn.decomposition import PCA
pca = PCA(n_components=5)
x = df[['complete_year','area', 'daypop', 'sub_kde',
'bus_kde', 'kind_kde', 'per_a20_39']]
# 使用x进行pca模型训练同时对x进行转换
x_transform = pca.fit_transform(x)
print(pca.explained_variance_ratio_.sum())
–> 输出的结果为:(这里只是尝试输入主成分为5,累计解释方差百分比已经达到了0.999,如何确定主成分的个数?)
0.9999999094429124
可以通过遍历的方式,把主成分的数量分别进行输入,然后查看一下累计解释方差百分比
for i in range(1,8):
pca = PCA(n_components=i)
x_transform = pca.fit_transform(x)
print(f'components={i},explanined_variance={pca.explained_variance_ratio_.sum()}')
–> 输出的结果为:(对各个成分进行输出)
components=1,explanined_variance=0.9726544078736945
components=2,explanined_variance=0.999572122074863
components=3,explanined_variance=0.9999995768050572
components=4,explanined_variance=0.999999809994995
components=5,explanined_variance=0.9999999094429124
components=6,explanined_variance=0.999999987099206
components=7,explanined_variance=1.0000000000000002
2.3 提取主成分个数,进行Pipeline整合
主成分的个数是如何确定???
常用判断标准:保留数据的解释方差累计百分比达到95%的所有特征
# 使用pipeline整合数据标准化、主成分分析与模型
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.pipeline import Pipeline
# 构建模型工作流
pipe_lm = Pipeline([
('sc',StandardScaler()),
('pca',PCA(n_components=1)),
('lm_regr',LinearRegression())
])
print(pipe_lm)
–> 输出的结果为:(构建工作流)
Pipeline(memory=None,
steps=[('sc',
StandardScaler(copy=True, with_mean=True, with_std=True)),
('pca',
PCA(copy=True, iterated_power='auto', n_components=1,
random_state=None, svd_solver='auto', tol=0.0,
whiten=False)),
('lm_regr',
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None,
normalize=False))],
verbose=False)
2.4 使用模型进行特征筛选,提取主成分(特征数据)
上面一部是确定了主成分的个数,这一部要完成的就是确定具体的主成分,也就是获得特征数据,之前讲到的惩罚模型Lasso,具有特征筛选的功能,这里就可以使用上
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import Lasso
# 准备筛选数据
x = df[['complete_year','area', 'daypop', 'sub_kde',
'bus_kde', 'kind_kde', 'per_a20_39']]
print(x.shape[1])
y = df[['average_price']]
# 定义筛选模型
lasso_lm = Lasso(alpha = 500)
# 定义特征筛选器
select_m = SelectFromModel(lasso_lm)
# 训练筛选器
select_m.fit(x,y)
# 运行筛选结果
print(select_m.transform(x).shape[1])
–> 输出的结果为:(输出显示,特征数量的变化7 -> 3)
7
3
2.5 进行Pipeline整合
pipe_lm = Pipeline([
('sc',StandardScaler()),
('lasso_select',SelectFromModel(lasso_lm)),
('lm_regr',LinearRegression())
])
print(pipe_lm)
–> 输出的结果为:
Pipeline(memory=None,
steps=[('sc',
StandardScaler(copy=True, with_mean=True, with_std=True)),
('lasso_select',
SelectFromModel(estimator=Lasso(alpha=500, copy_X=True,
fit_intercept=True,
max_iter=1000, normalize=False,
positive=False,
precompute=False,
random_state=None,
selection='cyclic', tol=0.0001,
warm_start=False),
max_features=None, norm_order=1, prefit=False,
threshold=None)),
('lm_regr',
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None,
normalize=False))],
verbose=False)
3. 特征扩展
1) 处理目的:
解决模型欠拟合
捕捉自变量与应变量之间的非线性关系
2) 常见处理方法,多项式拓展:
假设数据集中包含自变量a、b
如果对自变量做二项式扩展
自变量集从两个变量扩展为5个变量(a、b、a×a、b×b、a×b)
有时候数据特征是有限的,可以通过特征扩展的方式进行扩充(针对欠拟合)
from sklearn.preprocessing import PolynomialFeatures
# 准备筛选数据
x = df[['complete_year','area', 'daypop', 'sub_kde',
'bus_kde', 'kind_kde', 'per_a20_39']]
print(x.shape[1])
# 定义特征扩展模型并扩展特征
polynomy = PolynomialFeatures(degree=2)
# 训练筛选器
new_x = polynomy.fit_transform(x)
print(new_x.shape[1])
–> 输出的结果为:(特征向量从7个变成了36个,注意线性回归中,特征数量不可以超过样本数量)
7
36
整合Pipeline
pipe_lm = Pipeline([
('sc',StandardScaler()),
('poly_trans',PolynomialFeatures(degree=2)),
('lm_regr',LinearRegression())
])
print(pipe_lm)
–> 输出的结果为:(先标准化,然后特征扩展,接着是进行线性回归)
Pipeline(memory=None,
steps=[('sc',
StandardScaler(copy=True, with_mean=True, with_std=True)),
('poly_trans',
PolynomialFeatures(degree=2, include_bias=True,
interaction_only=False, order='C')),
('lm_regr',
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None,
normalize=False))],
verbose=False)


















 5336
5336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











