







卡司数量
卡司是一个中式英语,是英语cast的中文音译,意思是演员阵容,
是台湾和香港地区常用名词。英语“CLASS”的粤语拟音(类似于“的士”“芝士”等用法),
意思是“级别、等级、格调”。“这个男人很卡司。”这里的“卡司”就是指实力很强劲。
1 主演人数与烂片比例
1) 将主演中的人数进行统计
df['主演人数'] = df['主演'].str.split('/').str.len()
df_leaderole1 = df[['主演人数','豆瓣评分']].groupby(by = '主演人数').count()
print(df_leaderole1)
–> 输出结果为:(只截取部分,最多的主演人数为65)
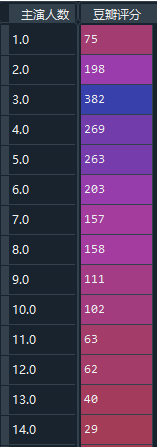
2) 假如要寻找这个主演为65个人对应的电影,注意成员判断两种方法的区别
#df[df['主演人数'].str.contains(65)]
print(df[df['主演人数'].isin([65])])
–> 输出结果为:(这里筛选的是数值,不能使用contains方法)
电影名称 豆瓣评论数 豆瓣评分 ... r2 r1 主演人数
1539 海角七号 海角七號 192665.0 7.5 ... 0.043 0.009 65.0
3) 查找不同主演人数下的烂片情况
df_leaderole2 = df[['主演人数','豆瓣评分']][df['豆瓣评分']<4.3].groupby(
by = '主演人数'
).count()
–> 输出结果为:(相对于上面的输出这里已经删减了一大部分了,这里也是只截取部分)
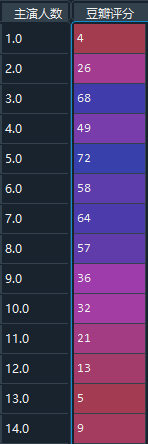
4) 将两组数据进行合并,并进行主演人数分类
df_leaderole = pd.merge(df_leaderole1,df_leaderole2,left_index = True,right_index =True)
df_leaderole.columns = ['电影数量','烂片数量']
df_leaderole.reset_index(inplace=True)
df_leaderole['主演人数分类'] = pd.cut(df_leaderole['主演人数'],[0,2,4,6,9,50],
labels =['1-2人','3-4人','5-6人','7-9人','10人以上'])
print(df_leaderole)
–> 输出结果为:(由于有相同的columns,所以合并后需要重新指定名称,将索引重置,最后再进行主演人数的分类)

5) 按照主演人数进行分组,然后统计烂片比例
df_leaderole_pre = df_leaderole[['电影数量','烂片数量','主演人数分类']].groupby(
by = '主演人数分类'
).sum()
df_leaderole_pre['烂片比例'] = df_leaderole_pre['烂片数量']/df_leaderole_pre['电影数量']
–> 输出结果为:
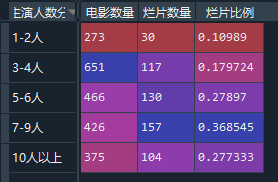
2 不同主演的烂片情况
1) 数据筛选,确定烂片的数量和全部电影的数量,需要剔除空值
df_role1 = df[(df['豆瓣评分']<4.3) & (df['主演'].notnull())]
df_role2 = df[df['主演'].notnull()]
2)进行主演人数的遍历,获取全部的主演人数,并保存在列表中
role_lst = []
for i in df_role1['主演'][df['主演'].notnull()].str.replace(' ','').str.split('/'):
role_lst.extend(i)
#获得所有的主演名称
role_lst = list(set(role_lst))
print(f'筛选后主演人数共有{len(role_lst)}人')
–> 输出结果为:
筛选后主演人数共有2667人
3)按照列表中的主演人数进行遍历,得到不同主演的烂片比例
lst_role_lp = []
for i in role_lst:
datai = df_role2[df_role2['主演'].str.contains(i)]
if len(datai) > 2:
dic_role_lp = {}
lp_pre_i = len(datai[datai['豆瓣评分']<4.3])/len(datai)
dic_role_lp['role'] = i
dic_role_lp['role_count'] = len(datai)
dic_role_lp['role_lp_pre'] = lp_pre_i
lst_role_lp.append(dic_role_lp)
4) 将处理的数据转化为DataFrame数据并进行排序
df_role_lp = pd.DataFrame(lst_role_lp)
role_lp_top20 = df_role_lp.sort_values(
by = 'role_lp_num',ascending=False
)[:20].set_index(np.arange(20))
–> 输出结果为:(这里是以烂片的数量作为排序的标准,还可以尝试使用烂片比例)

5)查看指定主演人员的烂片情况,比如这里向查看黄渤的
df_lp_hb = df_role_lp[df_role_lp['role'].isin(['黄渤'])]
print(df_lp_hb)
df_lp_hb = df_role1[df_role1['主演'].str.contains('黄渤')].set_index(np.arange(1))
print(df_lp_hb)
–> 输出结果为:(黄渤的烂片率很是很低的,而且唯一的一个还是给祖国做的贡献)
role role_lp_num role_count role_lp_pre
615 黄渤 1 18 0.055556
电影名称 豆瓣评论数 豆瓣评分 上映日期 ... r3 r2 r1 主演人数
0 奥运我爱你 344.0 2.9 2008(中国大陆) ... 0.119 0.102 0.743 31.0
6)比如上面就有一个数据特别亮眼,赵奕欢主演的电影烂片率是100%
df_lp_zyh = df_role2[df_role2['主演'].str.contains('赵奕欢')].set_index(np.arange(8))
–> 输出结果为:(也可以使用类似的方式查看其他主演的电影情况,这里再次使用成员判断的两种方式进行输出,要牢记)

















 3017
3017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











