







- 读取数据
①读取数据"moviedata.xlsx"
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
from bokeh.plotting import figure,show,output_file
from bokeh.models import ColumnDataSource,HoverTool
df=pd.read_excel(r'/Users/lihuilan/Desktop/moviedata.xlsx')
df=df[df['豆瓣评分']>0]
print('初步清洗后数据量为%i条' % len(df))
df.iloc[1]
# 读取数据
# 删除“豆瓣评分”小于等于0的值
初步清洗后数据量为2306条

② 查看“豆瓣评分”数据分布,绘制直方图、箱型图
# 查看豆瓣评分情况
fig = plt.figure(figsize = (10,6))
plt.subplots_adjust(hspace=0.2)
# 创建绘图空间
ax1 = fig.add_subplot(2,1,1)
df['豆瓣评分'].plot.hist(stacked=True,bins=50,color = 'green',alpha=0.5,grid=True)
plt.ylim([0,150])
plt.title('豆瓣评分数据分布-直方图')
# 绘制直方图
ax2 = fig.add_subplot(2,1,2)
color = dict(boxes='DarkGreen', whiskers='DarkOrange', medians='DarkBlue', caps='Gray')
df['豆瓣评分'].plot.box(vert=False, grid = True,color = color)
plt.title('豆瓣评分数据分布-箱型图')
# 绘制箱型图
df['豆瓣评分'].describe()


③ 判断“豆瓣评”数据是否符合正态分布
from scipy import stats
# 导入相关模块
u = df['豆瓣评分'].mean() # 计算均值
std = df['豆瓣评分'].std() # 计算标准差
stats.kstest(df['豆瓣评分'], 'norm', (u, std))#使用ks检验来判断数据是否符合正态分布
# 这里p值大于0.05,为正态分布
# 结论
# 这里以样本数据上四分位数为烂片评判标准 → 4.3分
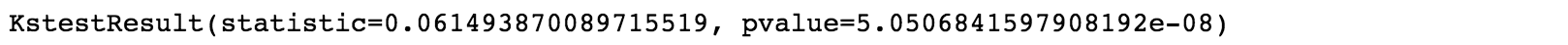
⑤ 筛选出烂片数据,并做排名,找到TOP20
data_lp = df[df['豆瓣评分']<4.3].reset_index()
print('数据整理后,得到烂片数据量为%i条' % len(data_lp))
# 筛选烂片数据
lp_top20 = data_lp[['电影名称','豆瓣评分','导演','主演']].sort_values(by = '豆瓣评分').iloc[:20].reset_index()
del lp_top20['index']
lp_top20
# 查看烂片top20


2. 什么题材的电影烂片最多?
① 按照“类型”字段分类,筛选不同电影属于什么题材
# 筛选出所有题材类型
typelst = []
for i in df[df['类型'].notnull()]['类型'].str.replace(' ','').str.split('/'):
typelst.extend(i)
# 取出所有电影的“类型”,并整理成列表
# 注意这里要删除“类型”中的空格字符
typelst = list(set(typelst))
print(typelst)
# 列表去重

② 整理数据,按照“题材”汇总,查看不同题材的烂片比例,并选取TOP20
# 创建函数,查看不同题材的烂片比例
# 这里要删除“类型”字段空值的数据
lst_type_lp = []
# 创建空字典、空列表
df_type = df[df['类型'] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3017
3017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









