






 本文介绍如何在Ubuntu 20.02系统上使用AMD Ryzen 9 5950X CPU和AMD 6700 XT 12G GPU配置Docker容器,并安装ROCm 5.0、PyTorch 1.10.0等软件,实现对GPU资源的有效利用。
本文介绍如何在Ubuntu 20.02系统上使用AMD Ryzen 9 5950X CPU和AMD 6700 XT 12G GPU配置Docker容器,并安装ROCm 5.0、PyTorch 1.10.0等软件,实现对GPU资源的有效利用。
环境
- 宿主机环境
ubuntu20.02(其实能跑docker的linux都可以)
CPU: AMD Ryzen 9 5950X
GPU: AMD 6700XT 12G理论上可以支持绝大部分的A卡 包含570 580
- 容器环境
ROCm5.0
pytorch1.10.0
python3.7
启动容器
docker run \
--device=/dev/kfd \
--device=/dev/dri \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--ipc=host \
-dit \
--rm \
-e HSA_OVERRIDE_GFX_VERSION=10.3.0 \
amdih/pytorch:rocm5.0_ubuntu18.04_py3.7_pytorch_1.10.0
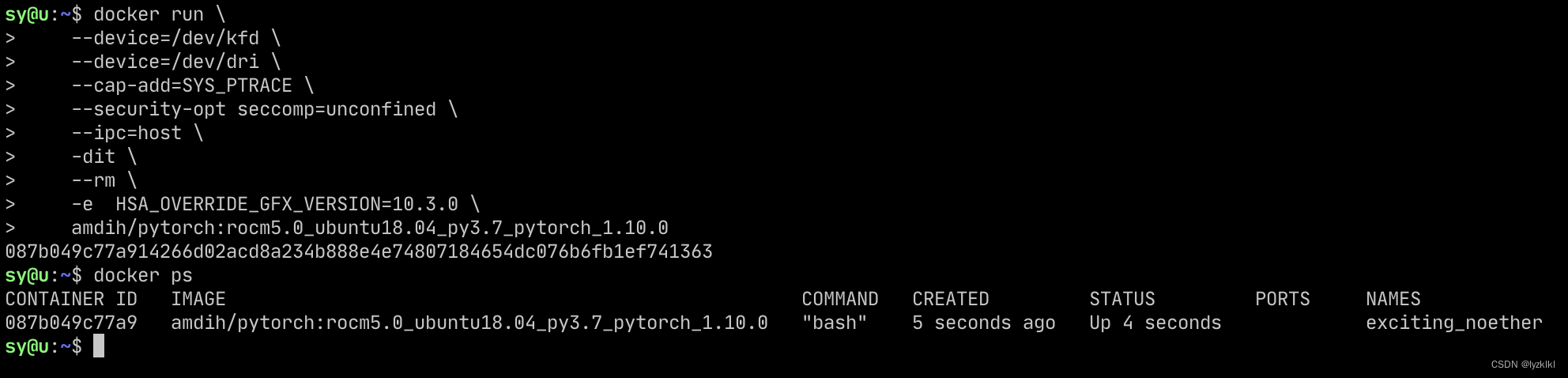
验证是否可用
docker exec -it 容器id bash
# 进入容器后输入一下命令
python
import torch
print(torch.cuda.is_available())
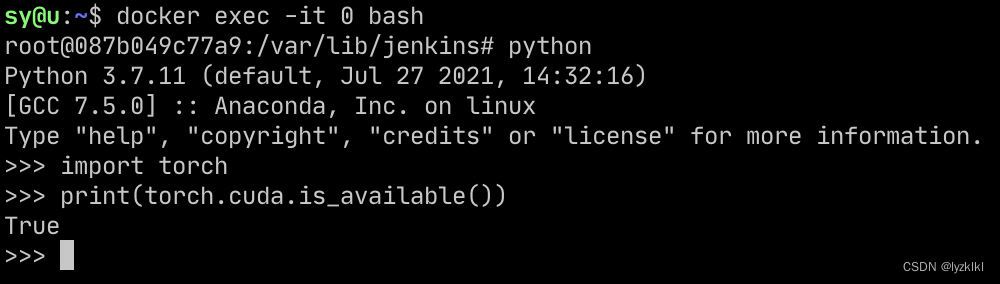
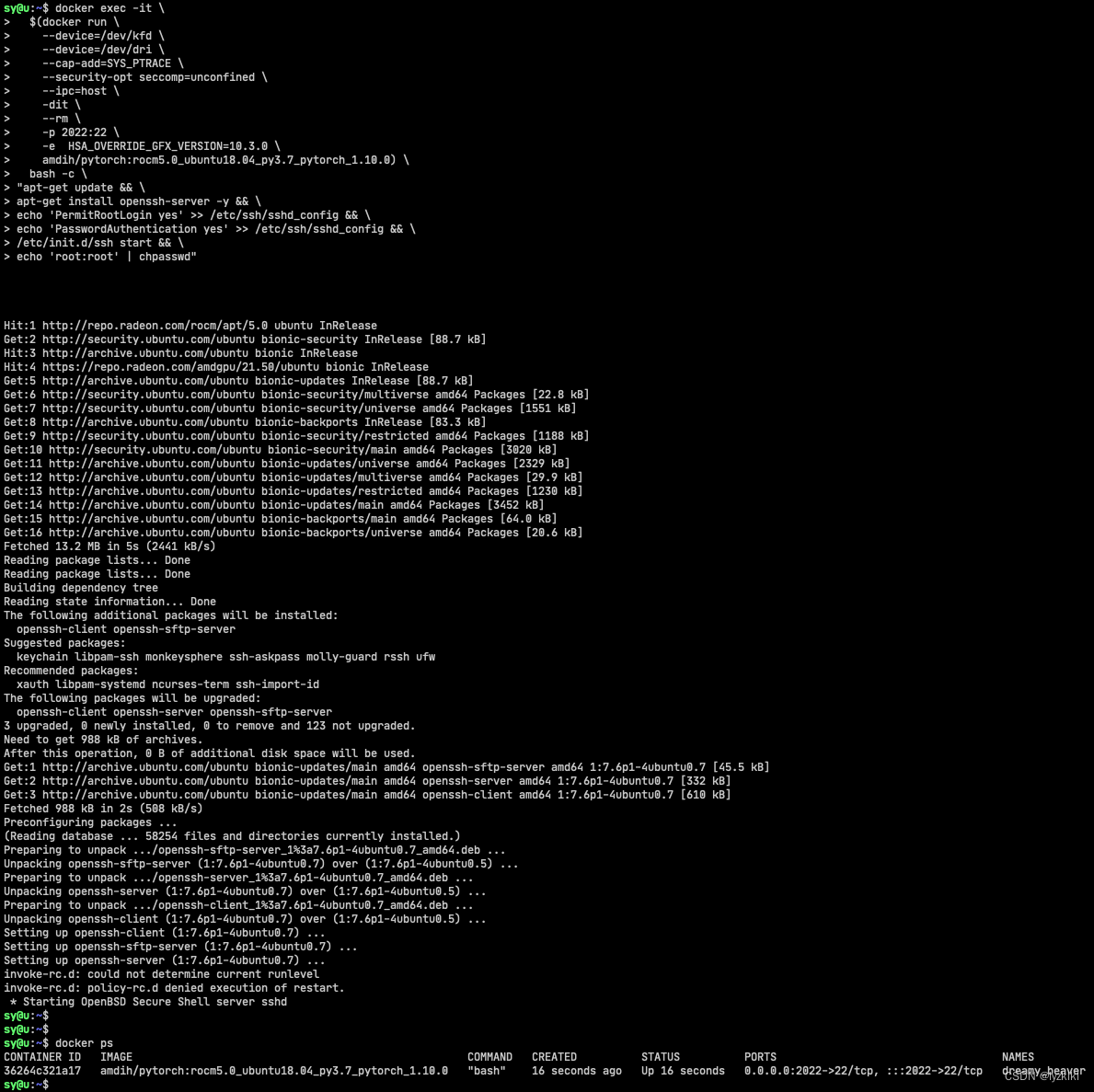
快速部署ssh直通版(ssh =直达=> 容器)
# 直接通过 exit run 的命令
# 并添加:2022端口ssh访问容器
# 设置root的密码为root
docker exec -it \
$(docker run \
--device=/dev/kfd \
--device=/dev/dri \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--ipc=host \
-dit \
--rm \
-p 2022:22 \
-e HSA_OVERRIDE_GFX_VERSION=10.3.0 \
amdih/pytorch:rocm5.0_ubuntu18.04_py3.7_pytorch_1.10.0) \
bash -c \
"apt-get update && \
apt-get install openssh-server -y && \
echo 'PermitRootLogin yes' >> /etc/ssh/sshd_config && \
echo 'PasswordAuthentication yes' >> /etc/ssh/sshd_config && \
/etc/init.d/ssh start && \
echo 'root:root' | chpasswd"
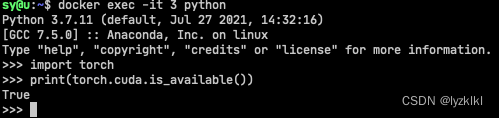
验证1, docker exec验证
docker exec -it 容器ID python
import torch
print(torch.cuda.is_available())
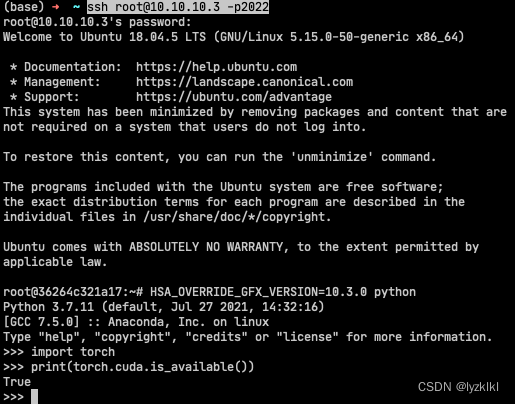
验证2, ssh 验证
# 这里的2022是上面的 -p映射的
ssh root@容器宿主机IP -p2022
# 这里需要输入环境变量运行python
HSA_OVERRIDE_GFX_VERSION=10.3.0 python
import torch
print(torch.cuda.is_available())


















 136
136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









