




 本文对YOLO系列算法论文进行解读,涵盖YOLOv1、YOLOv2和YOLOv3。介绍了各版本网络输出目标表示、架构、损失函数等内容,分析了YOLOv2相较于YOLOv1的改进点,以及YOLOv3的结构特点和训练方法,还提及了一些论文未详述的要点。
本文对YOLO系列算法论文进行解读,涵盖YOLOv1、YOLOv2和YOLOv3。介绍了各版本网络输出目标表示、架构、损失函数等内容,分析了YOLOv2相较于YOLOv1的改进点,以及YOLOv3的结构特点和训练方法,还提及了一些论文未详述的要点。
YOLO系列算法论文解读
手撕YOLOv3代码部分:https://github.com/lzneu/handwriten_net/tree/master/yolov3
目录
2.2 High Resolution Classifier
2.3 Convolutional With Anchor Boxes
2.5 Direct location prediction
3.2 Training for classification
YOLOv1
1、直接看网络的输出如何表示目标
如Fig2
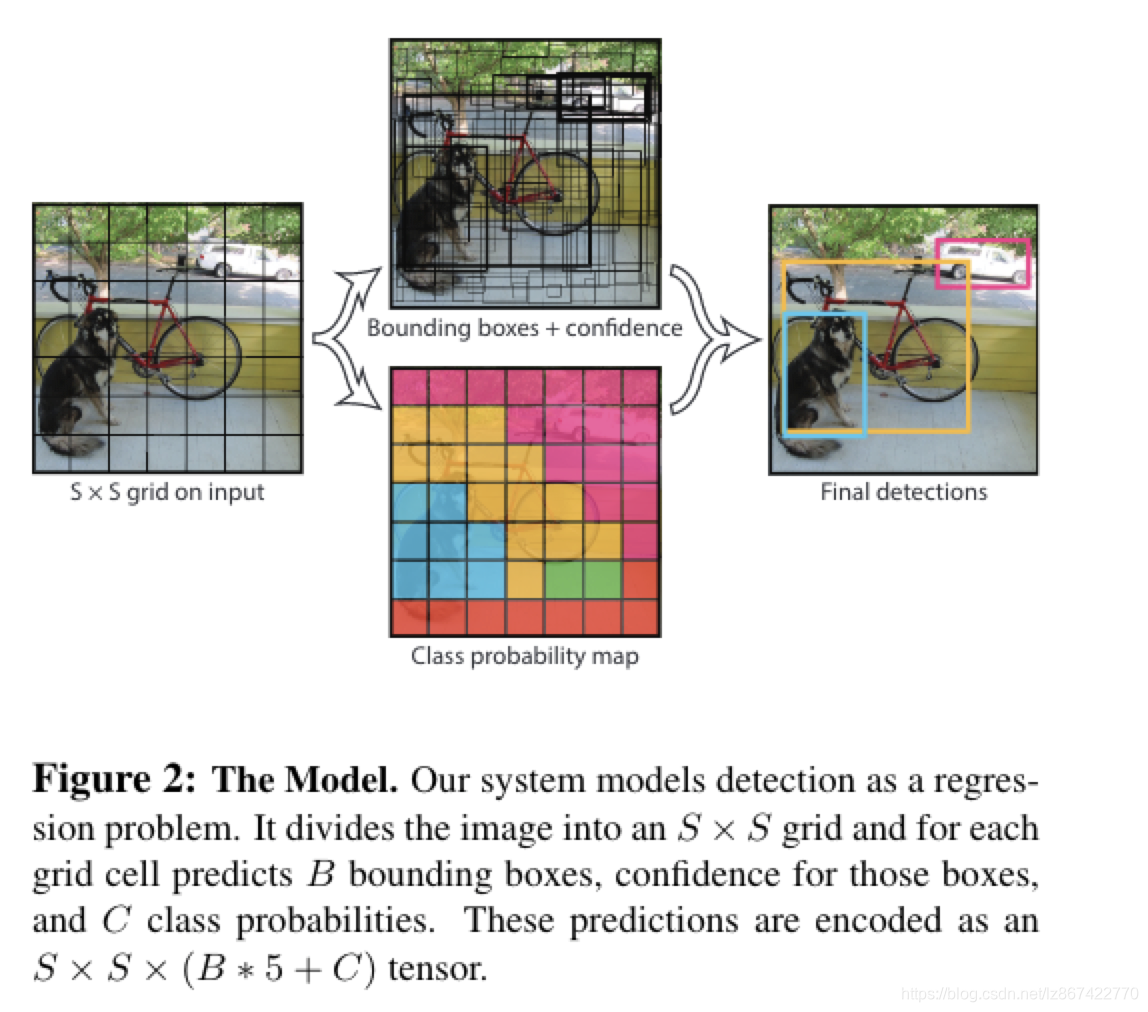
- 最终的输出层特征尺寸为S*S大小的grid,每个grid单元代表一个输出预测;
- 每个输出预测包括B个bbox以及C个类别的置信度
- bbox表示为[x,y,w,h, 置信度],其中,xy 为相对于gridcell边界的中心;w,h 为相对于整个图片的距离;置信度预测为预测框和真实框的IOU值,当grid cell中不存在目标时,其值为0
- C个类别置信度为Pr(Classi| Object),其中P(Object)为bbox中的置信度
- 注意,无论B为多少,都只预测一组C值
- 因此最终的输出特征的维度为:S*S*(B*5+C)
其中,在PASCAL VOC数据集上,设置S=7,B=2,C=20
因此,输出层最终的特征尺寸为:7*7*30
2、网络架构
整体的思路是:卷积网络提取特征+全连接层编码输出
网络架构图如fig3

- 使用24个卷积层+2个全连接层
- 使用224尺寸的图片,ImageNet数据集训练前20个卷积层
- 使用1*1卷积进行通道变换
- 增加4个卷积层和2个全连接层使用随机初始化参数
- 最后放大输入图片尺寸到448作为检测的卷积网络的输入
- 最后一层使用线性激活函数;其余层均使用leaky 线性激活函数,如公式(2)所示
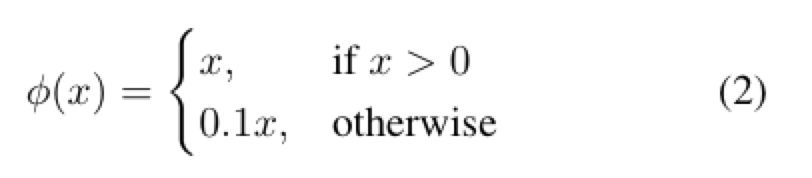
3、损失函数
全部使用平方和误差,但是有3个明显问题:
1)位置损失和类别损失不能具有相同的权重
2)大部分的grid cell不具有object,导致训练初期都为0,训练不稳定
3)平方和误差对于大box和小box的惩罚程度不同,导致小目标惩罚过轻
作者对此采取了一些措施:
1)使用两个参数λcoord=5和λnoobj=0.5来控制bbox损失和无目标预测的损失
2)使用宽高的平方根来计算位置损失,减少大小目标惩罚程度不同的问题
整体损失函数如公式(3)
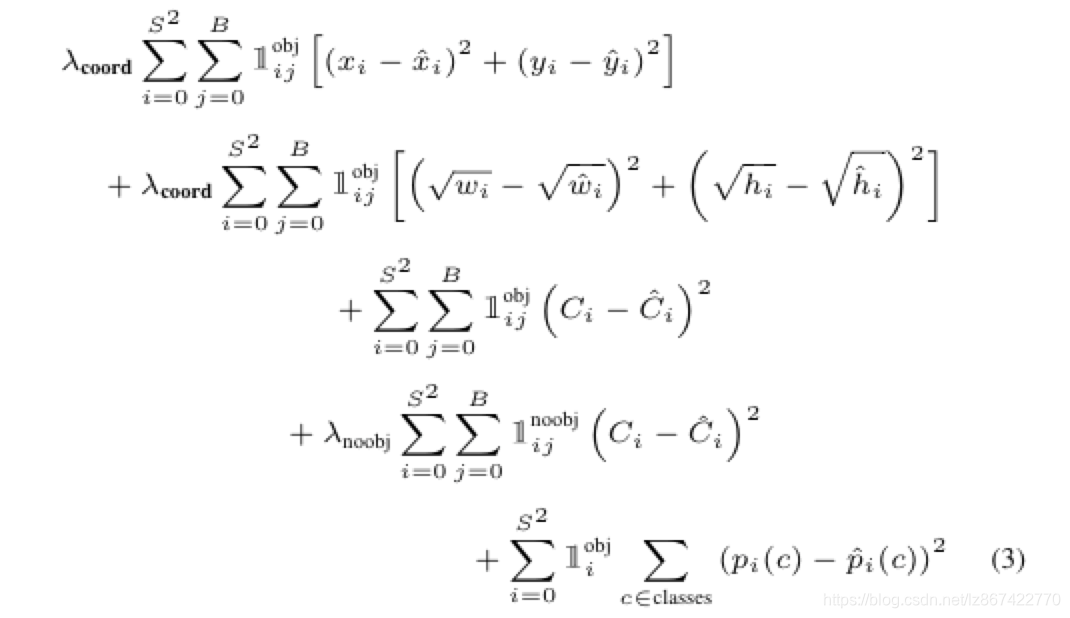
其中:
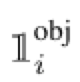 代表在gridcell i出现
代表在gridcell i出现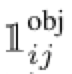 代表在gridcell i 和bbox j 出现目标
代表在gridcell i 和bbox j 出现目标
YOLOv2
1、背景
- 2017CVPR
- 相比较YOLOv1mAP提升10+%,并且检测速度更快
- 使用目标检测数据及学习定位,使用分类数据及学习类别判断,因此可以检测超过9000个类别,又称YOLO9000
2、相比较YOLOv1的改进
2.1 Batch Normalization
- 提升mAP约2%
- 帮助正则化模型,移除了所有的dropout
- 注意:卷积之后加入BN,卷积层的bias可以去掉了,因为其值可由bn层的平移因子代替
2.2 High Resolution Classifier
- 先使用448*448的输入尺寸的ImageNet训练分类网络10个epoch(YOLOv1中是使用224的输入尺寸训练,然后直接应用到448输入的检测中)
- 提升4%的mAP
2.3 Convolutional With Anchor Boxes
- 移除fc层,使用anchor boxes来预测bbox,模型预测偏移量而不是绝对坐标使得网络更易于学习
- 去掉pooling层,让输出有更高的分辨率
- 输入图片从448调整为416,使得特征图有一个绝对的中心位置,便于预测超大目标
- 下采样倍数为32,从416到13
- mAP降低0.3%,recall提升7%,意味着模型有更大的提升空间
2.4 Dimension Clusters
- 使用k-means方法做anchor设置
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 411
411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









