







当一个表中的数据量足够大,在 HQL查询时效率就会大打折扣,就好比: Order By、Sort By、Distribute By、Cluster By 的使用 中的 Order By,只能使用一个 reduce 来处理数据,查询速度就会慢的多。
为了提高查询效率。Hive 中引入了分区表的概念。在 MapReduce 中也有分区的概念,Map端对数据进行切片,Reduce阶段进行 Shuffle分区并汇总计算。其实也是为了提高任务的并行度,提高任务处理的效率。
1.分区表
分区表:实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式,选择查询所需要的指定的分区,避免对整个目录文件进行全表扫描,这样的查询效率会提高很多。
生产环境中,分区表的使用是非常多的。一般是按天为单位进行统计,将一天的数据专门放在一个文件夹中,在查询时,直接指定分区,就可以避免全表扫描,提高查询效率。
提示:
分区字段,也是表中的一个正常字段,和普通字段一样对待即可,没有其他任何区别。
Ⅰ.分区表基本操作
1.创建分区表语句
# 创建order_info分区表(以day为分区字段)
create table order_info(order_no string, name string, phone_no string, address string, order_amt double)
partitioned by (day string)
row format delimited fields terminated by ',';
2.分区数据准备
三个文件名分别是: order_info_2021-05-25.txt、order_info_2021-05-26.txt、order_info_2021-05-27.txt;每个文件中的数据如下:
order_info_2021-05-25.txt
20210525001,Smith,13456962478,北京市石景山区,453.24
20210525002,Luka,13523659632,北京市门头沟区,62.5
20210525003,Donic,18500230698,北京市朝阳区,383.6
20210525004,George,18666668521,河北省廊坊市,863.12
order_info_2021-05-26.txt
20210526001,Bob,13856932545,北京市西城区,74.2
20210526002,Clark,18521356984,北京市通州区,23.69
20210526003,John,18734468296,北京市大兴区,36.64
20210526004,Mary,18565239658,北京市昌平区,89.12
order_info_2021-05-27.txt
20210527001,James,13800138000,北京市海淀区,138.5
20210527002,Lucy,13651365453,北京市朝阳区,88.4
20210527003,Lily,13852365748,北京市东城区,79.3
20210527004,Paul,18600612596,北京市大兴区,49.2
3.装载数据至指定分区
# 转载数据至day=2021-05-25分区
load data local inpath '/opt/module/hive/data/order_2021-05-25.txt' into table order_info
partition(day='2021-05-25'); # 分区表装载数据时,必须指定分区
# 转载数据至day=2021-05-26分区
load data local inpath '/opt/module/hive/data/order_2021-05-26.txt' into table order_info
partition(day='2021-05-26');
# 转载数据至day=2021-05-27分区
load data local inpath '/opt/module/hive/data/order_2021-05-27.txt' into table order_info
partition(day='2021-05-27');


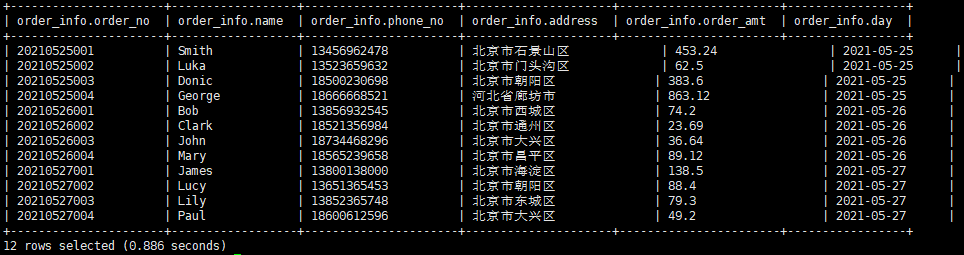
4.数据查询
Ⅰ.全表数据查询
select * from order_info;
查询结果:
Ⅱ.单个分区数据查询
select * from order_info where day = '2021-05-27';
指定分区字段day进行查询,就会去指定分区查询

如果使用非分区字段address查询,则会进行全表扫描(数据特别多时,查询效率就会有区别)
select * from order_info where address = '北京市大兴区';

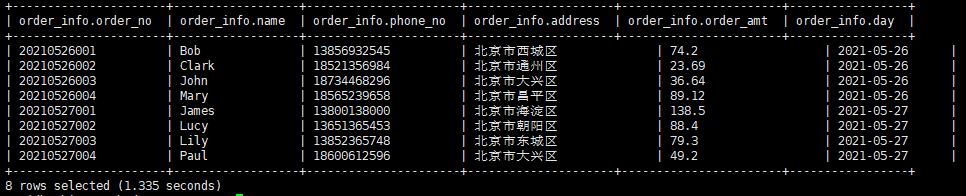
Ⅲ.多个分区数据查询
#方法1:
select * from order_info where day='2021-05-27'
union
select * from order_info where day='2021-05-26'; ---- union方式,会走 MR 查询
#方法2:
select * from order_info where day='2021-05-27' or day='2021-05-26'; -- or方式,不会走 MR 查询
查询结果:
5.增加分区
# 增加一个分区
alter table order_info add partition(day='2021-05-28');
# 一次增加多个分区(中间用空格分隔)
alter table order_info add partition(day='2021-05-28') (day='2021-05-29');
# load数据时,直接load到指定分区
load data local inpath xxx into table order_info partition(day='2021-05-28');
6.删除分区
# 删除一个分区
alter table order_info drop partition(day='2021-05-27');
# 一次删除多个分区(中间用逗号分隔)
alter table order_info drop partition(day='2021-05-27'),partition(day='2021-05-28');
# 删除指定范围的分区
alter table order_info drop partition(day>'2021-05-20',day<'2021-05-25');
# 删除表所有分区的数据
truncate table order_info; # 直接清空表即可(此操作会清空数据,但是分区信息还存在)
#删除某个分区的数据(直接删除分区即可,没找到truncate指定分区)
alter table order_info drop partition(day='2021-05-30');
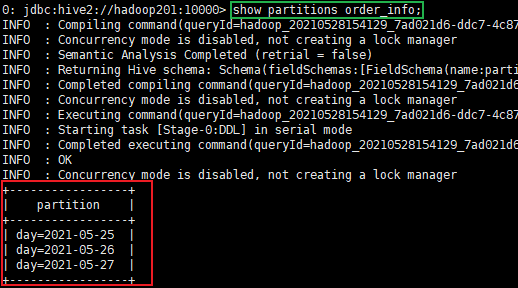
7.查看分区表有多少分区
show partitions order_info;
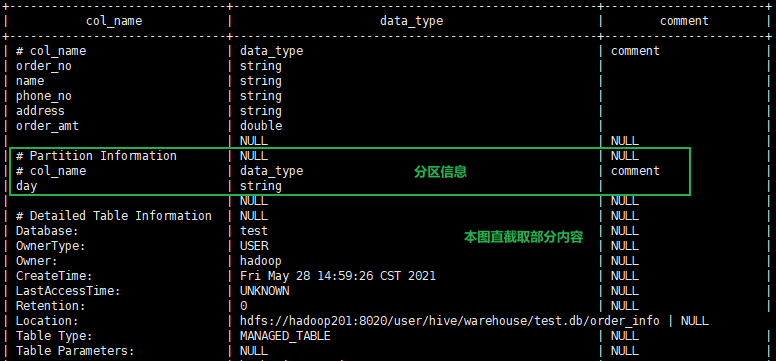
8.查看分区表结构
desc formatted order_info;
Ⅱ.二级分区
如何一天的日志数据量也很大,如何再将数据拆分?就有了
二级分区的概念
1.二级分区创建语句
# 创建 day + hour 的分级分区表
create table order_info_partition_hour(order_no string, name string, phone_no string, address string, order_amt double)
partitioned by (day string, hour string)
row format delimited fields terminated by ',';
2.装载数据至指定分区
# 转载数据至day=2021-05-25,hour=01分区下
load data local inpath '/opt/module/hive/data/order_2021-05-25-01.txt' into table order_info_partition_hour
partition(day='2021-05-25',hour='01');
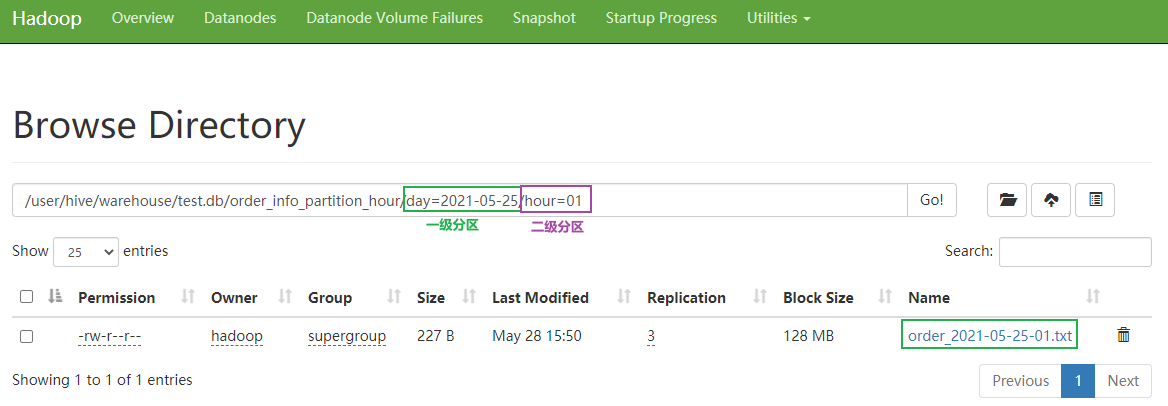
3.查询二级分区数据
select
*
from
order_info_partition_hour
where
day='2021-05-25' and hour='01';`
Ⅲ.动态分区
关系型数据库中,对分区表 Insert 数据时候,数据库自动会根据分区字段的值,将数据插入到相应的分区中,Hive 中也提供了类似的机制,即动态分区(Dynamic Partition),只不过,使用 Hive 的动态分区,需要进行相应的配置。
1.动态分区案例(通过案例来介绍)
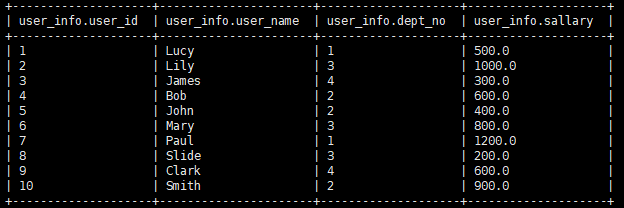
将以下user_info结果,根据 dept_no 部门号进行动态分区,就不能像上文一样,直接指定 partition(dept_no=1) 这样了,因为dept_no 是查询出来的。
最终结果:
【deptno=1,2条数据 (user_id:1、7)】
【deptno=2,3条数据 (user_id:4、5、10)】
【deptno=3,3条数据 (user_id:2、6、8)】
【deptno=4,2条数据 (user_id:3、9)】
过程:
1.创建分区表 user_info_dynamic_partition
create table user_info_dynamic_partition(user_id int, user_name string, sallary double)
partitioned by (dept_no int)
row format delimited fields terminated by ',';
2.动态分区SQL
# Hive 3.x 以前版本
insert into table user_info_dynamic_partition partition(dept_no)
select user_id, user_name, sallary, dept_no from user_info;
# Hive 3.x 版本
insert into table user_info_dynamic_partition # 3.x版本此处有点小变化
select user_id, user_name, sallary, dept_no from user_info;
提示:
Hive 3.x 之前版本,动态分区,在 partition 中直接定义分区名。在select 语句中,默认会使用最后一个字段作为它的一个分区字段信息。(最后一个字段留给分区使用)
Hive 3.x 版本,动态分区,insert into 方式导入数据,可以省去了分区字段。默认,还是将 select 最后一个字段作为它的一个分区字段信息。(最后一个字段留给分区使用)
3.x 以前版本语句,成功执行动态分区,需要设置 Hive 为非严格模式才能。通过 set hive.exec.dynamic.partition.mode=nonstrict; 即可设置。3.x 版本语句,就没有这个限制,使用更加方便了)
2.开启动态分区的几个参数设置
这几个参数在官网有介绍,地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DML#LanguageManualDML-DynamicPartitionInserts
1.开启动态分区功能(默认 true,开启)hive.exec.dynamic.partition=true2.设置为非严格模式(动态分区的模式,默认 strict,表示必须指定至少一个分区为静态分区,nonstrict 模式表示允许所有的分区字段都可以使用动态分区。)
hive.exec.dynamic.partition.mode=nonstrict3.在所有执行 MR 的节点上,最大一共可以创建多少个动态分区。默认 1000
hive.exec.max.dynamic.partitions=10004.在每个执行 MR 的节点上,最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。比如:源数据中包含了一年的数据,即 day 字段有 365 个值,那么该参数就需要设置成大于 365,如果使用默认值 100,则会报错。
hive.exec.max.dynamic.partitions.pernode=1005.整个 MR Job 中,最大可以创建多少个 HDFS 文件。默认 100000
hive.exec.max.created.files=1000006.当有空分区生成时,是否抛出异常。一般不需要设置。默认 false
hive.error.on.empty.partition=false

Ⅳ.手工创建的分区目录,如何让数据与分区信息进行关联
因为 Hive 数据是存储在 HDFS 中的,所以我们可以手动 mkdir 一个分区文件夹,然后通过 hadoop put 的方式将数据上传至指定分区文件夹。这种方式由于没有经过 Hive 元数据,元数据是没有该分区信息的,所以是没法查询出这个分区以及分区数据的。(load方式装载数据,是会走hive元数据的,所以能够关联成功)
把数据直接上传到分区目录上,让分区表和数据产生关联,一共有如下三种方式:
- 上传数据后修复分区信息
- 上传数据后添加分区
- 创建文件夹后 load 数据到分区
1.执行修复分区命令
mkdir手工在 HDFS 创建分区文件夹,使用 put 方式上传数据后,执行如下命令修复分区即可。
# 修复分区命令
msck repair table 表名;
注意:
修复分区。比如一个二级分区 day 和 hour,如果自己创建文件夹,2021-05-30 分区,没有hour二级分区文件夹,如下:
day=2021-05-28 hour=01
day=2021-05-29 hour=01
day=2021-05-30
这种情况,在执行 msck repair table 时,会直接报 Error 错误的。只有分区文件夹齐全后,执行修复分区命令,才会成功。
2.上传数据后添加分区
1.手动 mkdir 创建分区文件夹
hive > dfs -mkdir -p /user/hive/warehouse/test.db/order_info_partition_hour/day=2021-05-25/hour=01;
2.手动 put 上传文件
hive > dfs -put xxx.log /user/hive/warehouse/test.db/order_info_partition_hour/day=2021-05-25/hour=01;
3.alter 添加分区
hive > alter table order_info_partition_hour add partition(day=‘2021-05-25’,hour=‘01’);
4.此时关联成功,便能够正常查询了
3.创建文件夹后 load 数据到分区
1.手动 mkdir 创建分区文件夹
hive > dfs -mkdir -p /user/hive/warehouse/test.db/order_info_partition_hour/day=2021-05-25/hour=01;
2.load 装载数据到指定分区(load装载会走hive元数据,所以能够关联成功)
hive > load data local inpath xxx.log into table order_info_partition_hour partition(day=‘2021-05-25’,hour=‘01’);
3.此时关联成功,便能够正常查询了
2.分桶表
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分。(分区后,分区内的表,可以再进行分桶)分桶是将数据集分解成更容易管理的若干部分的另一个技术。
分桶表,也是将数据集拆分开。这个分开不是针对于文件夹,而是针对于文件。将一张表文件,做了分桶,会将数据拆分成多个小文件。分桶表在数据集极大时会才会使用。分桶表可以配合后续的抽样查询。分桶表做了解即可。
分区/分桶区别:
分区针对的是数据的存储路径;分桶针对的是数据文件。
Ⅰ.分桶表基本操作
1.数据准备
student_info.txt 文档
内容如下:
1,Lucy
2,Lily
3,James
4,Bob
5,John
6,Mary
7,Paul
8,Slide
9,Clark
10,Smith
11,Smart
12,Lilei
13,Andra
14,Donic
15,Jelly
16,Chris
17,Schla
18,Elea
19,Flink
20,Grash
2.分桶表创建语句
create table stu_buck(id int, name string)
clustered by(id) # 分桶表分桶字段,必须是已有字段,不能指定类型(分区表则必须是创建表时不存在的字段)
into 4 buckets
row format delimited fields terminated by ',';
3.导入数据
3.1 load 的方式导入数据到分桶表中
hive (default)>
load data local inpath '/opt/module/hive/data/student_info.txt' into table stu_buck;
提示:
分桶表,在load导入数据时,是会走 MR 程序的。(数据如果在hdfs,去掉local;如果在本机,添加local)。
注意:
【此处建议不要使用 local 本地模式】,建议使用从 hdfs 中 load 数据到分桶表中,避免本地文件找不到问题。【load 模式会走MR程序,local模式下,Yarn会将任务随机分发到集群某个节点,如果该节点没有你要装载的文件,则会报文件找不到的问题,所以最好从 hdfs 中 load 数据到分桶表】

查看创建的分桶表中是否分成 4 个桶

3.2 insert 方式将数据导入分桶表
注意:insert 方式也是走 MR 程序的
1.创建分桶表 stu_buck_2create table stu_buck_2(id int, name string) clustered by(id) into 4 buckets row format delimited fields terminated by ',';2.insert方式将数据导入
insert into table stu_buck_2 select * from stu_buck where id > 5;
3.每个桶中的数据,如下图所示


4.查询分桶的数据
hive (test)> select * from stu_buck;
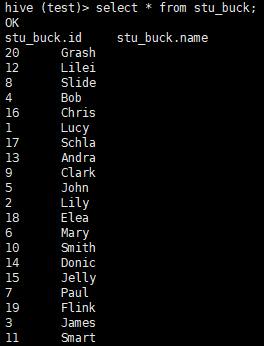
5.分桶规则
根据结果可知:Hive 的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中

6.分桶表注意事项
- reduce 的个数设置为-1,让 Job 自行决定需要用多少个 reduce 或者将 reduce 的个数设置为大于等于分桶表的桶数
- 从 hdfs 中 load 数据到分桶表中,避免本地文件找不到问题
Ⅱ.抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。Hive 可以通过对表进行抽样来满足这个需求。
语法:
TABLESAMPLE(BUCKET x OUT OF y)
查询表 stu_buck 中的数据
hive (test) > select * from stu_buck tablesample(bucket 1 out of 4 on id);
注意:
x 的值必须小于等于 y 的值,否则会报如下错误:
FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu_buck
Tip小提示:
分桶表在数据量足够大的情况下会使用到。一般用的也不多,需要用到时再过来学习吧。生产环境下用的最多的,还是分区表
下一篇:Hive 内置函数
博主写作不易,加个关注呗
求关注、求点赞,加个关注不迷路 ヾ(◍°∇°◍)ノ゙
我不能保证所写的内容都正确,但是可以保证不复制、不粘贴。保证每一句话、每一行代码都是亲手敲过的,错误也请指出,望轻喷 Thanks♪(・ω・)ノ
















 4074
4074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











