







技术背景
DeepSeek R1作为最新开源大模型,原生采用FP8精度训练,需要英伟达Ada/Hopper架构新型GPU支持。这导致三个核心问题:
- 硬件限制:A100等存量GPU无法直接部署
- 显存压力:反量化BF16方案显存需求翻倍
- 性能损耗:BF16推理吞吐下降约33%
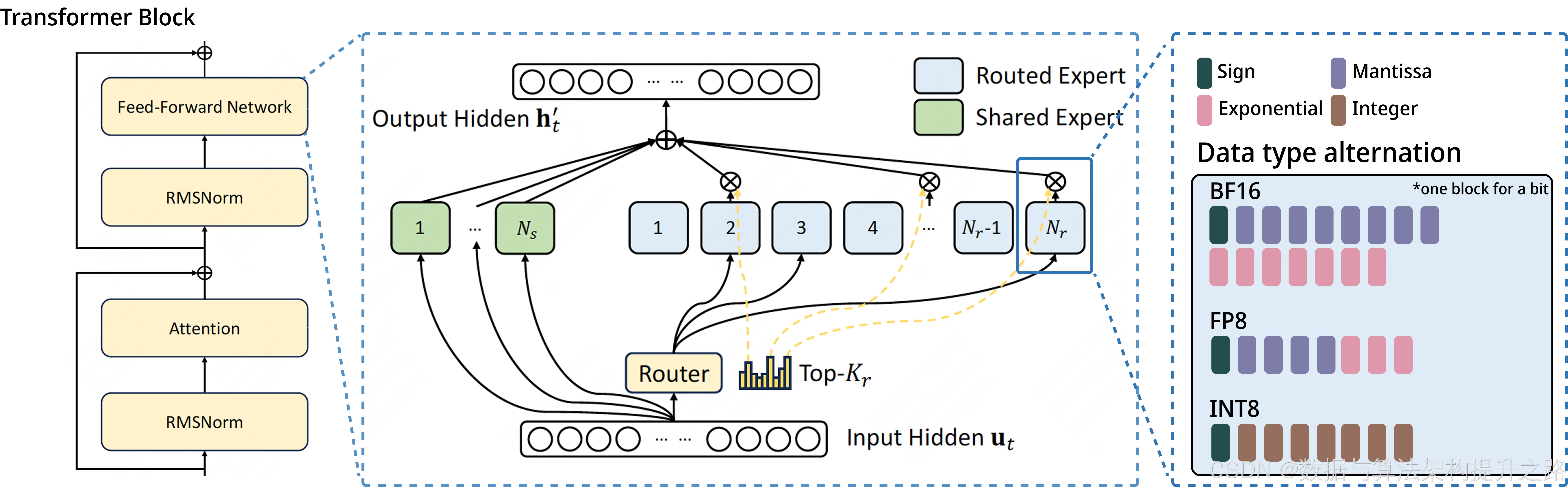
美团技术团队通过INT8无损量化方案突破硬件限制,在A100上实现:
✅ 推理吞吐提升50%
✅ 16张卡即可部署(原需32张)
✅ 精度损失<0.5%(GSM8K/MMLU基准)
技术实现详解
量化原理
采用INT8对称量化策略:
# 量化公式
scale = max(abs(tensor)) / 127
quantized = torch.clamp(torch.round(tensor / scale), -128, 127)
# 反量化公式
dequantized = quantized * scale
双重量化策略
| 方法 | 优势 | 适用场景 |
|---|---|---|
| 分块量化 | 精度损失小(<0.3%) | 精度敏感型任务 |
| 通道量化 | 计算效率高(+17%吞吐) | 高并发推理场景 |
关键技术突破
- 动态激活量化
采用逐token-group量化策略,最大程度保留上下文信息
# 激活值分组量化示例
group_size = 128
for i in 0 to num_groups:
act_group = activation[i*group_size:(i+1)*group_size]
quantize(act_group)
- 混合精度计算
关键计算路径保留BF16精度,平衡效率与精度
性能实测
精度对比(GSM8K数据集)
| 精度类型 | 准确率 | 相对损失 |
|---|---|---|
| FP8原生 | 82.3% | - |
| INT8分块 | 82.1% | -0.24% |
| INT8通道 | 81.9% | -0.49% |
推理吞吐对比
| 部署方案 | A100数量 | Tokens/sec |
|---|---|---|
| BF16原生 | 32 | 12,500 |
| INT8分块 | 16 | 16,700 |
| INT8通道 | 16 | 18,800 |
一键部署指南
# 分块量化部署(精度优先)
python3 -m sglang.launch_server \
--model meituan/DeepSeek-R1-Block-INT8 \
--tp 16 --dist-init-addr HEAD_IP:5000 \
--nnodes 2 --node-rank 0 \
--enable-torch-compile
# 通道量化部署(性能优先)
python3 -m sglang.launch_server \
--model meituan/DeepSeek-R1-Channel-INT8 \
--quantization w8a8_int8 \
--tp 16 --dist-init-addr HEAD_IP:5000 \
--nnodes 2 --node-rank 0
实际效果展示
复杂推理测试
curl -X POST 'http://HEAD_IP:5000/v1/chat/completions' \
-d '{
"messages": [{
"role": "user",
"content": "下列选项中,找出与众不同的一个:1.铝 2.锡 3.钢 4.铁 5.铜"
}]
}'
模型输出:
经过多步推理确认:钢是唯一合金材料,其他均为纯金属。
最终答案:3.钢
代码生成测试
用p5.js编写100个弹性小球在旋转球体内的碰撞检测脚本

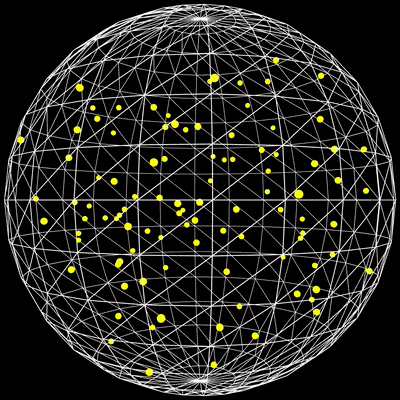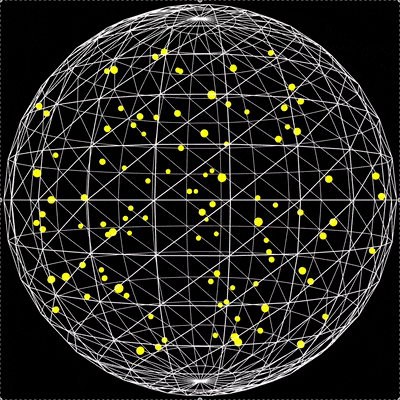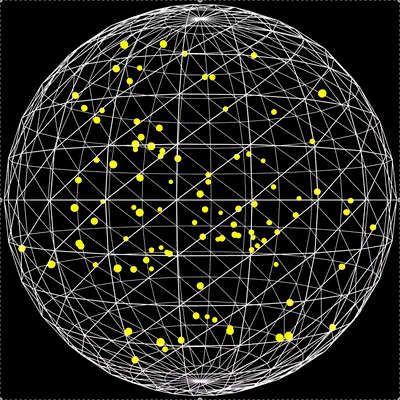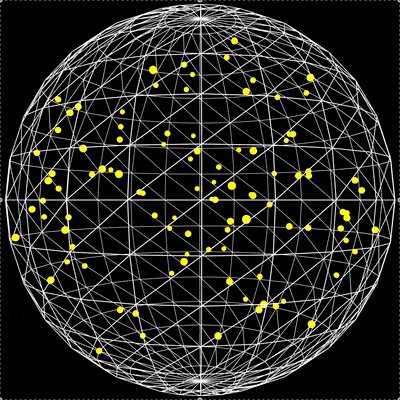


















 2226
2226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











