







机器学习算法与Python实践(10) - 分类回归树 classification and regression tree-CART
CART算法的重要基础包含以下三个方面:
- 二分(Binary Split):在每次判断过程中,都是对观察变量进行二分。
CART算法采用一种二分递归分割的技术,算法总是将当前样本集分割为两个子样本集,使得生成的决策树的每个非叶结点都只有两个分枝。因此CART算法生成的决策树是结构简洁的二叉树。因此CART算法适用于样本特征的取值为是或非的场景,对于连续特征的处理则与C4.5算法相似。 - 单变量分割(Split Based on One Variable):每次最优划分都是针对单个变量。
- 剪枝策略:CART算法的关键点,也是整个Tree-Based算法的关键步骤。
更多理论介绍,参考:http://dataunion.org/5771.html
还是以决策树之ID3中的例子,当然CART是可以处理条件属性是连续值的分类问题。CART是一个二叉树
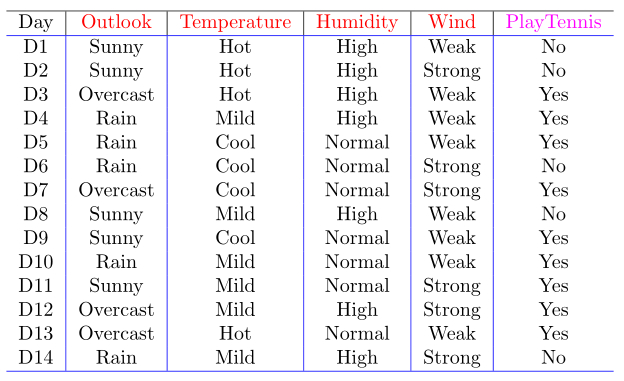
在CART中的出现的概念是GINI。
我们先根据Outlook条件属性计算GINI,Outlook有三个属性值,因为CART是一个二叉树,我们把三个属性值按照2+1的组合(有三种)即:

针对上表,
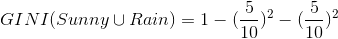
我们得出第一个GINI:
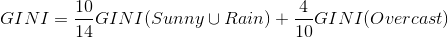
针对上表,
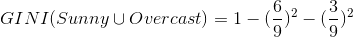
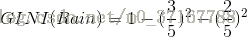
我们得出第二个GINI:
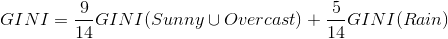

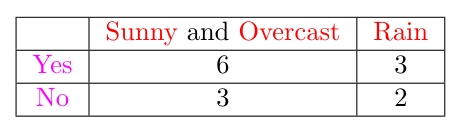
针对上表,
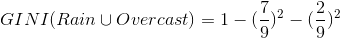
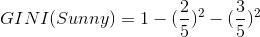
我们得到第三个GINI:

然后根据其他条件属性,继续计算GINI ,然后选最小的那一个GINI,作为节点。
上述的就是分类回归树的介绍。下面对其 Python 代码进行介绍:
my_data = [['slashdot', 'USA', 'yes', 18, 'None'],
['google', 'France', 'yes', 23, 'Premium'],
['digg', 'USA', 'yes', 24, 'Basic'],
['kiwitobes', 'France', 'yes', 23, 'Basic'],
['google', 'UK', 'no', 21, 'Premium'],
['(direct)', 'New Zealand', 'no', 12, 'None'],
['(direct)', 'UK', 'no', 21, 'Basic'],
['google', 'USA', 'no', 24, 'Premium'],
['slashdot', 'France', 'yes', 19, 'None'],
['digg', 'USA', 'no', 18, 'None'],
['google', 'UK', 'no', 18, 'None'],
['kiwitobes', 'UK', 'no', 19, 'None'],
['digg', 'New Zealand', 'yes', 12, 'Basic'],
['slashdot', 'UK', 'no', 21, 'None'],
['google', 'UK', 'yes', 18, 'Basic'],
['kiwitobes', 'France', 'yes', 19, 'Basic']]
class decisionnode: # 决策树节点结构
def __init__(self, col=-1, value=None, results=None, tb=None, fb=None):
self.col = col # 被测试规则索引
self.value = value # 要被测试的值
self.results = results # 测试结果
# tb,fb是决策树节点,tb为true时的节点,fb为false的节点
self.tb = tb
self.fb = fb
# 训练决策树:CART (Classification and Regression Trees)分类与回归树
# 1)建立根节点
# 2)遍历表中所有数据,选择最好的变量划分数据
def devideset(rows, column, value): # column为栏位在row的索引,value为此栏位的值
split_function = None
if isinstance(value, int) or isinstance(value, float):
split_function = lambda row: row[column] >= value
else:
split_function = lambda row: row[column] == value
# 根据split_function划分
set1 = [row for row in rows if split_function(row)]
set2 = [row for row in rows if not split_function(row)]
return (set1, set2)
# 没row中最后一个栏位的个数
def uniquecounts(rows):
result = {}
for row in rows:
r = row[len(row) - 1]
if r not in result: result[r] = 0
result[r] += 1
return result
# 整个rows随机放置item到错误category中的可能性
def giniimpurity(rows):
total = len(rows)
counts = uniquecounts(rows)
imp = 0
for k1 in counts:
# 计算k1放到错误category中的可能性
p1 = float(counts[k1]) / total
for k2 in counts:
if k1 == k2: continue
p2 = float(counts[k2]) / total
imp += p1 * p2
return imp
# sum(p(x)*log2(p(x)))
def entropy(rows):
from math import log
log2 = lambda x: log(x) / log(2)
results = uniquecounts(rows)
ent = 0.0
for r in results.keys():
p = float(results[r]) / len(rows)
ent += p * log2(p)
return ent
# 递归构建决策树
def buildtree(rows, scoref=entropy):
if len(rows) == 0: return decisionnode()
current_score = scoref(rows)
# 设置变量,跟踪最好的规则
best_gain = 0
best_criteria = None
best_sets = None
# record的栏 item数
column_count = len(rows[0]) - 1
for col in range(0, column_count):
# 生成
column_values = {}
for row in rows:
column_values[row[col]] = 1
# 尝试为rows中的每个记录的第col个field划分set
for value in column_values.keys():
# 划分后的set
(set1, set2) = devideset(rows, col, value)
# 划分后的长度比例
p = float(len(set1)) / len(rows)
# 权重得分
gain = current_score - p * scoref(set1) - (1 - p) * scoref(set2)
# 找到了最好的规则
if gain > best_gain and len(set1) > 0 and len(set2) > 0:
best_gain = gain
best_criteria = (col, value)
best_sets = (set1, set2)
# 取最好的规则,并对划分后的子集合进行递归构建决策树
if best_gain > 0:
trueBranch = buildtree(best_sets[0])
falseBranch = buildtree(best_sets[1])
return decisionnode(col=best_criteria[0], value=best_criteria[1],
tb=trueBranch, fb=falseBranch)
else:
return decisionnode(results=uniquecounts(rows))
# 利用决策树来对observation进行归类
def classify(observation, tree):
if tree.results != None:
return tree.results
v = observation[tree.col]
branch = None
# 查找分支,此处算法与划分set规则一致
if isinstance(v, int) or isinstance(v, float):
if v >= tree.value:
branch = tree.tb
else:
branch = tree.fb
else:
if v == tree.value:
branch = tree.tb
else:
branch = tree.fb
return classify(observation, branch)















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









